Language Model (LM)
- 문장의 확률을 나타낸 모델
- 문장 자체의 출현 확률 예측
- 다음 단어를 예측 : 인간도 가장 나올 확률이 높은 단어를 선택해 문장을 완료한다
빈칸에 들어갈 가장 적절한 말은?
안녕하세요, _________
1. 으아악!
2. 반갑습니다.
3. 꿿돲숗
- 답은 2번이다
- 사람들의 입에서 나온 문장들을 분석해봤을때, 가장 출현 확률이 높은 것이기 때문.
- 그렇다면, 나머지는 확률이 0이라고 할 수 있을까?
=> 누군가가 말한 순간, 확률이 0보다 크게 되기 때문에 이는 아니다. - 인간은 단어와 단어 사이의 확률이 학습되어 있다.
- 따라서 대화를 하다가 정확하게 듣지 못해도 엄청난 지장은 없다
LM 의 궁극적인 목표는 우리가 사용하는 언어의 문장 분포를 정확하게 모델링 하는 것.
LM 의 수식
- 문장이 들어있는 dataset 을 corpus 라고 한다 :
- 단어들이 순차적으로 등장해 구성하는 문장이 corpus 내의 문장을 만들 확률을 최대화하는 것이 목적.
- 는 어떤 sequence 가 등장할 확률
- LM은 이를 위한 매개변수 ( -> ) 를 학습한다
- 는 모델 파라미터, 는 가능한 파라미터 조합
- 단어들의 등장 확률(결합 확률)은 조건부확률로 나타내어진다.

- 위 수식을 LM에 적용해보자
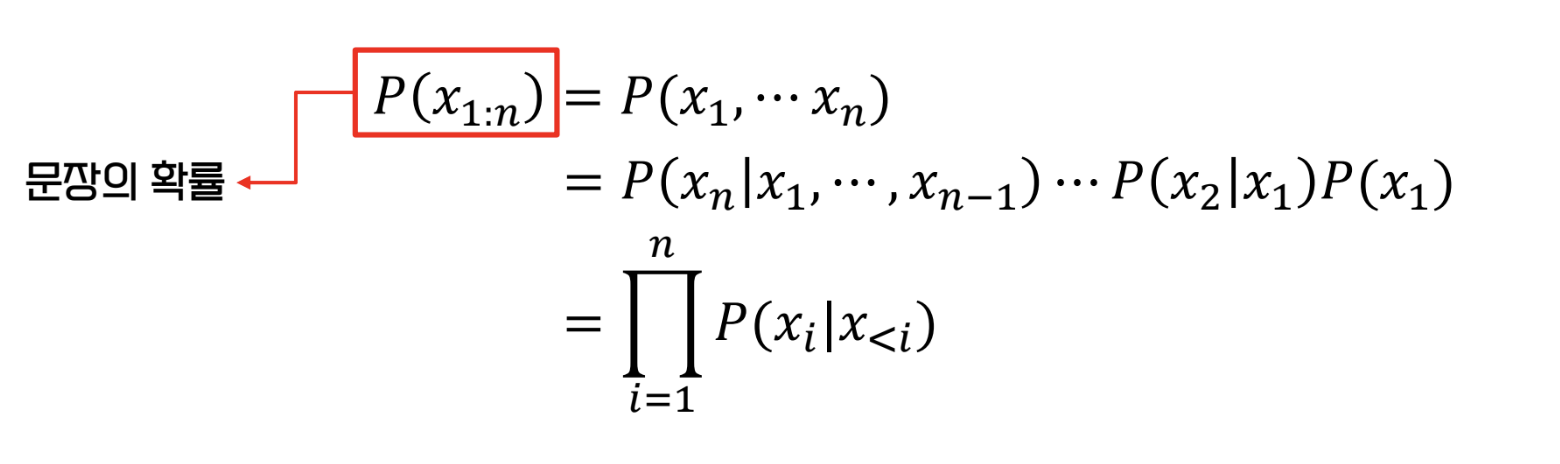
- 이를 덧셈으로 나타내는 것이 편하기 때문에 log 를 취하기도 한다
- 위 수식을 실제 문장에 적용해보자
문장 구분을 위해 앞뒤로 토큰을 붙인다
<BOS> : Beginning of Sentence
* <EOS> : End of Sentence
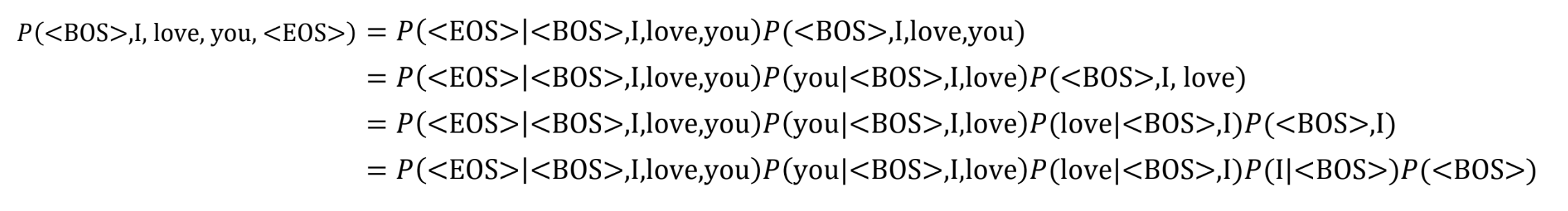
- 문장의 시작은 항상 <BOS> 이기 때문에, P(<BOS>) 는 1이다.
- 반면, 문장이 언제 끝나는지는 모르기 때문에 P(<EOS>) 는 1이 아니다.
좋은 LM 이란?
- 사람의 사고를 함수로 잘 모방한 모델
- 하지만 문장의 확률은 단어들의 확률에 대한 곱으로 표현되기에 문장이 길어질수록 확률 값은 작아진다
- 따라서 문장의 길이에 관계 없는 지표가 필요하다.
Perplexity (PPL)
- 문장 확률의 역수에 길이를 더해서 기하평균을 낸 값
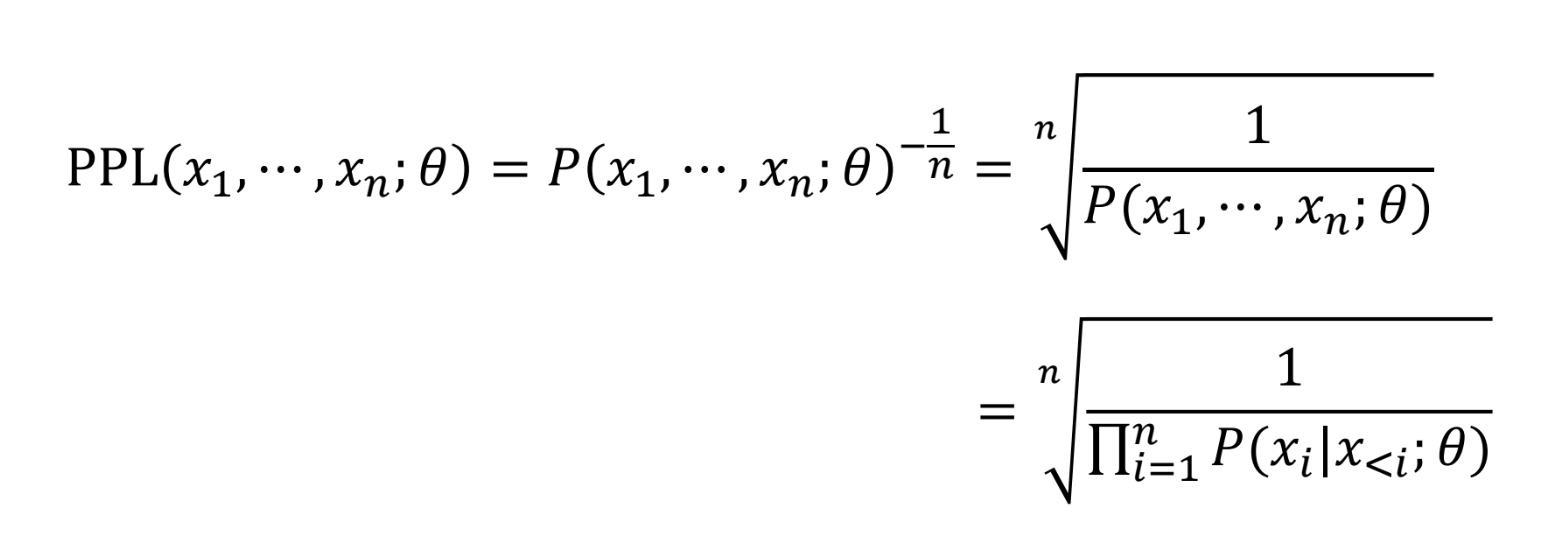
- PPL 이 작은 모델일수록 덜 헷갈리게 문장을 만든다고 할 수 있다.
Seq2Seq (Sequence to Sequence)
- 원시적인 자연어 생성 모델
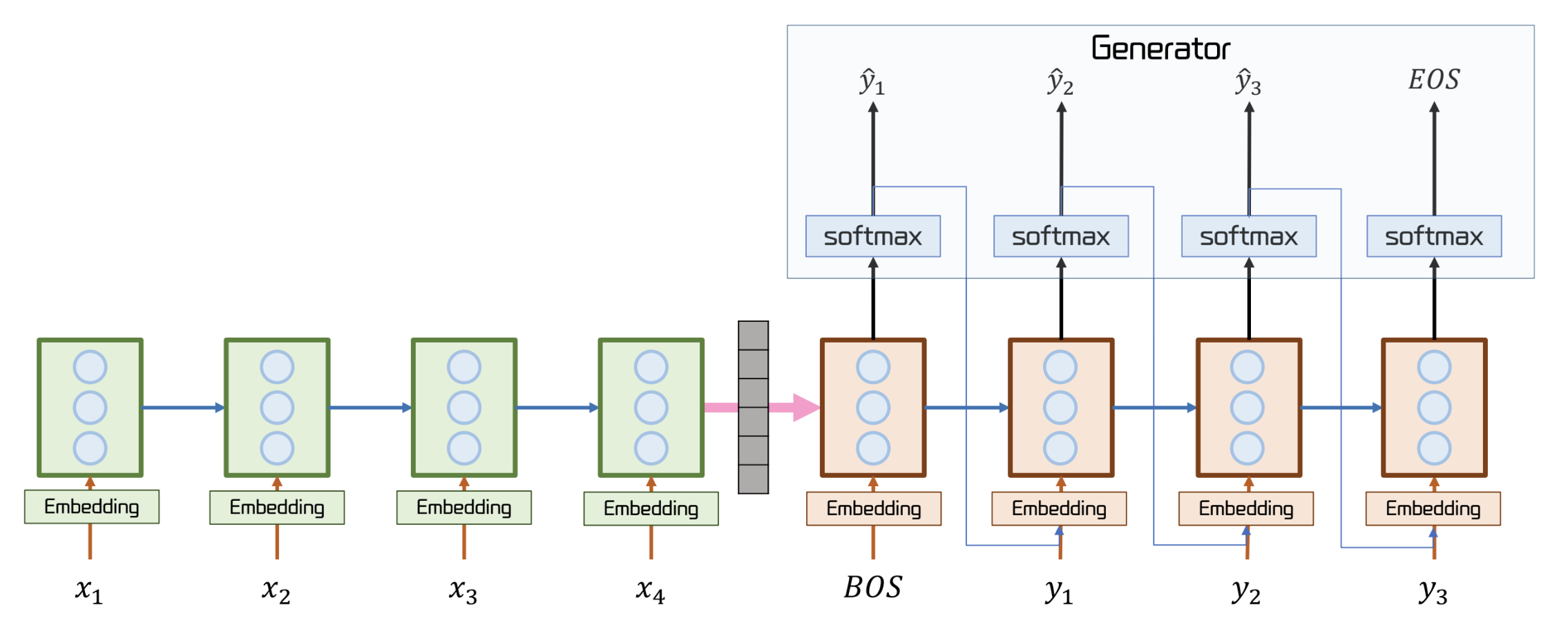
- Encoder (초록색) 에서 문장의 문맥을 담은 context vector 를 생성
- context vector 는 Decoder (주황색)에 전달된다.
- 이 때, context vector 의 길이가 decoder 의 즉, 첫 상태가 된다.
- Decoder 는 이 문맥을 기반으로 결과물을 도출한다.
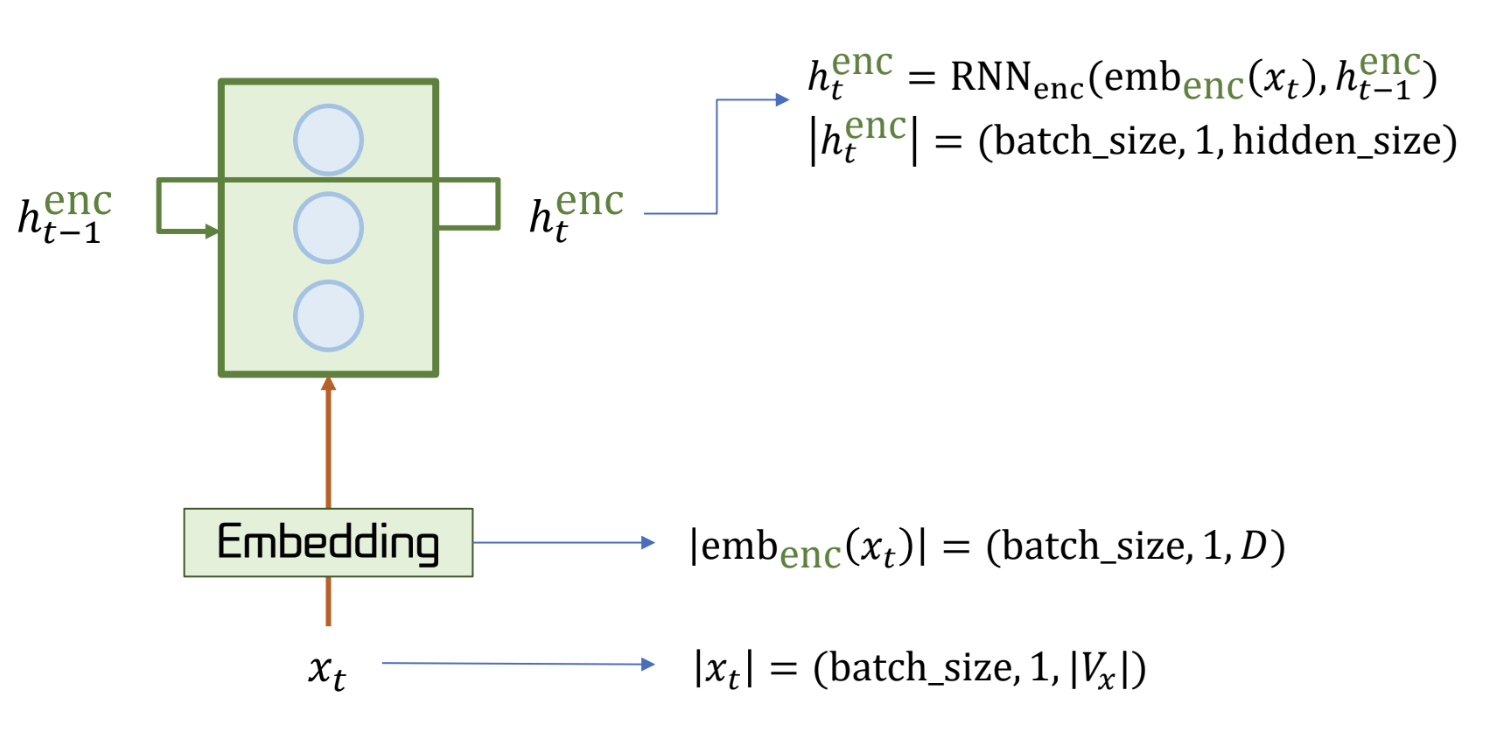
Encoder
- 수행하고자 하는 목적을 출력하기 위한 context vector 를 생성
- context vector는 문장의 전체적인 의미를 요약한 고정 크기의 벡터
- encoder 의 마지막 hidden state 가 context vector 가 되는 것이다.
- encoder 의 입력은 다음과 같다
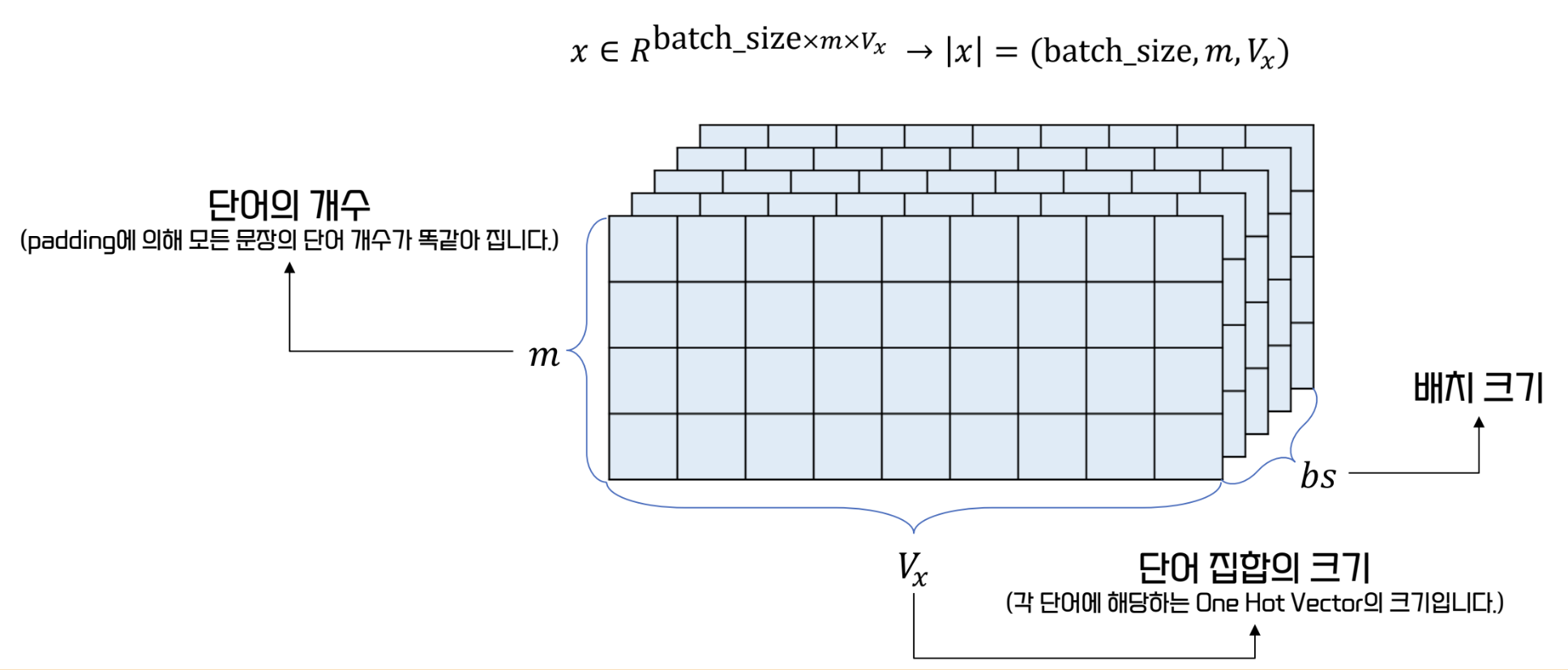
- 이 때, encoder 입력의 vocab_size 와 decoder 출력의 vocab_size 가 같다는 보장은 없다
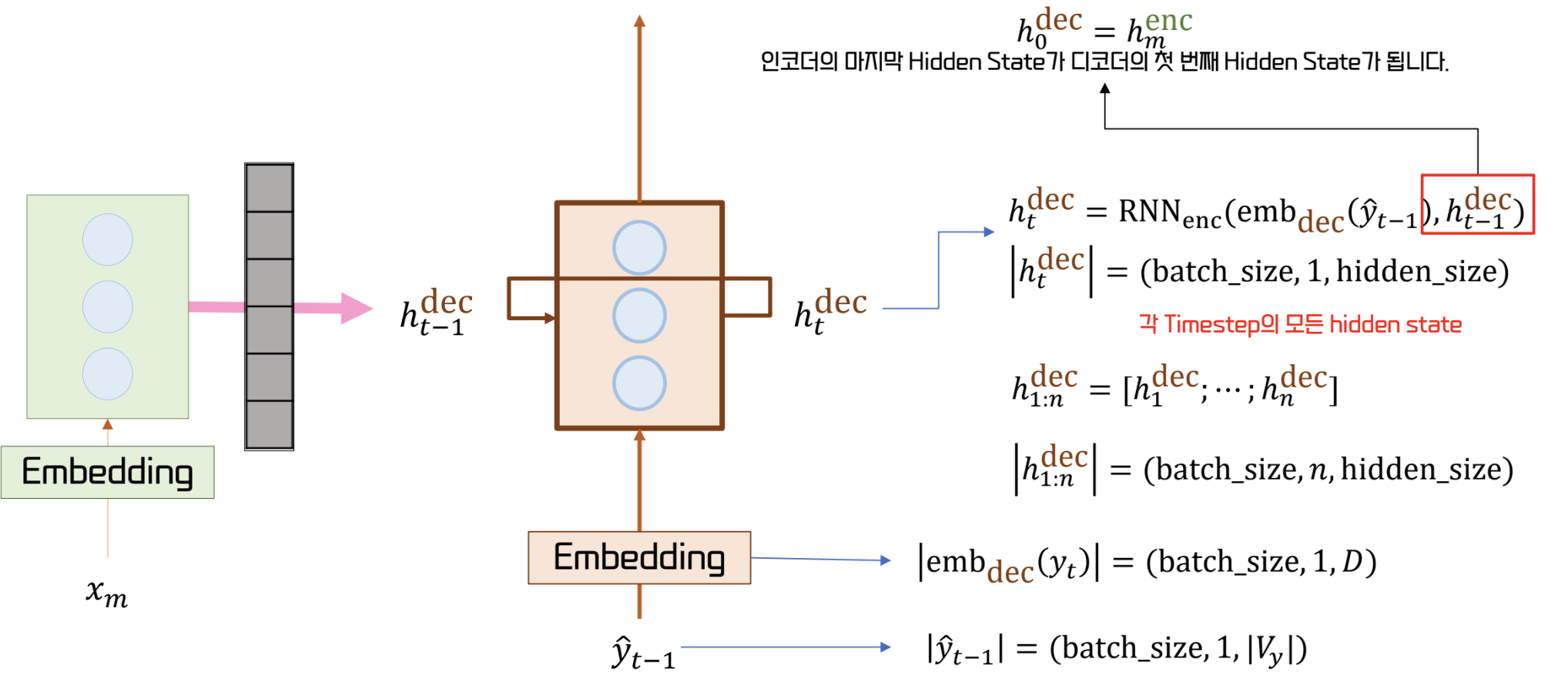
Decoder
- Encoder로 부터 받아낸 Context Vector를 토대로 문장을 생성
- decoder 의 입력은 다음과 같다
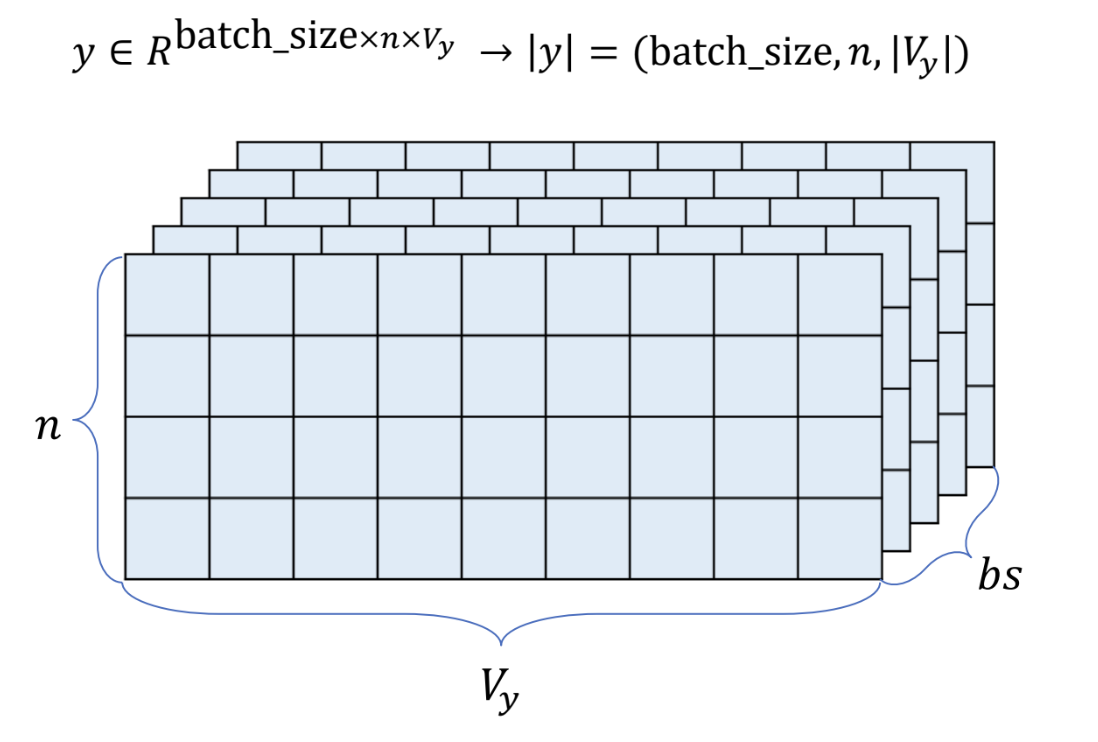
- encoder 와 같은 형태
- = <BOS> , = <EOS>
- encoder 는 bidirectional 이 가능하지만, decoder 는 안된다
* decoder 는 문장을 순차적으로 생성해야 하기 때문이다.
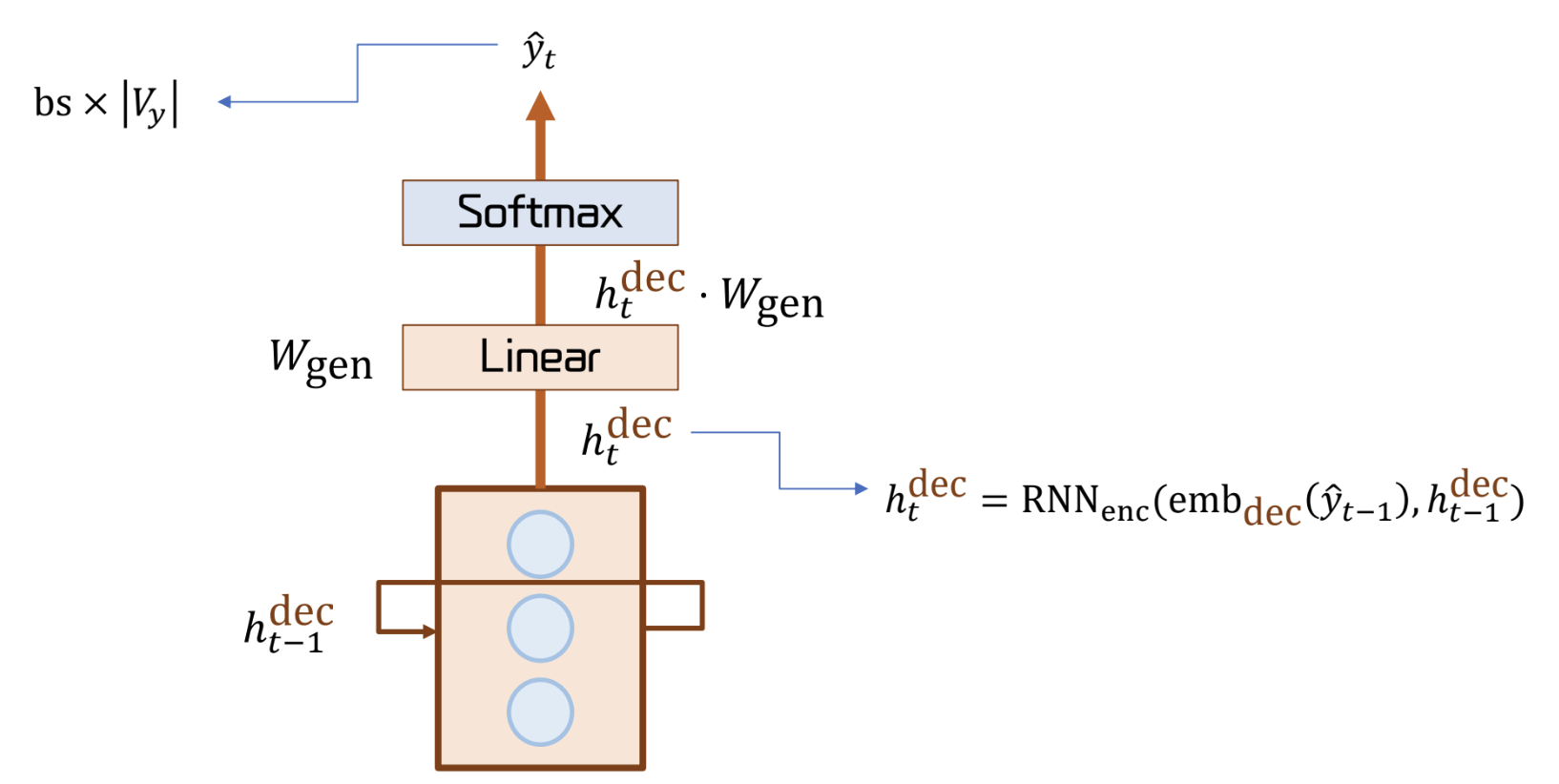
Generator
- Decoder의 Hidden State 에 Linear 연산을 수행한 후 softmax 를 적용해 확률 분포를 도출

인하대학교 컴퓨터공학과