- 배열에 저장된 값에는 관계 연산자가 정의된 유형의 키 값이 있다
- 정렬하면 요소가 배열 내에서 그 키값을 기준으로 오름차순 또는 내림차순으로 재정렬된다.
SIMPLE SORT
- Straight Selection Sort
- Bubble Sort
- Insertion Sort
MORE COMPLEX SORT(재귀를 통해 구현됨)
- Quick Sort
- Merge Sort
- Heap Sort
SELECTION SORT
- 배열은 두 파트로 나뉘게 된다→already sorted 파트와 not yet sorted 파트
- on each pass, unsorted part에서 가장 작은 값을 찾아서 적절한 위치의 값과 swap. 이렇게 반복하면 sorted 파트의 elements가 증가하게 된다.
- 즉, 정리하자면 한 번 수행할 때 마다 정렬이 아직 안 된 부분 중에 제일 작은 값을 가진 원소를 찾아서 현재 포인터가 가르키는(이제 sorted part가 될 위치) 위치에 집어넣고, 현재 위치를 가르키는 포인터를 한 칸 더 이동시킴
- 기본 구현시 stability 만족시키지 않음

- selection sort에서는 아직 정렬이 안 된 부분에서 최솟값을 구하기 위해 정렬이 안 된 파트에서 비교해야 함. 즉 비교횟수가 무조건 정해져있음!!

- 따라서 비교 횟수를 일반화 한다면 Sum=(N-1)+(N-2)+.....2+1
- 따라서 Sum=
- 즉 , O(N^2)
BUBBLE SORT
- 두 개의 인접 원소들을 묶어서(묶은 게 하나의 버블이 됨) 그 버블 안에서 큰 것, 작은 것을 비교해서 역순으로 되어있으면 그 둘의 위치를 바꿈. 그리고 다시 한 칸 옮겨서 또 BUBBLE을 생성
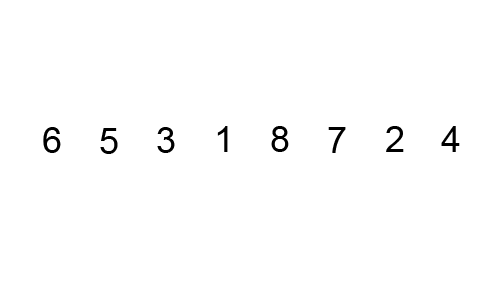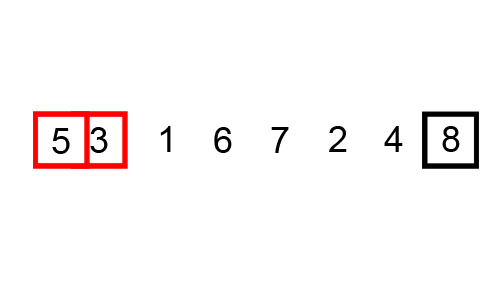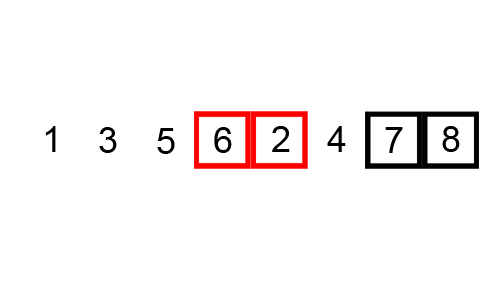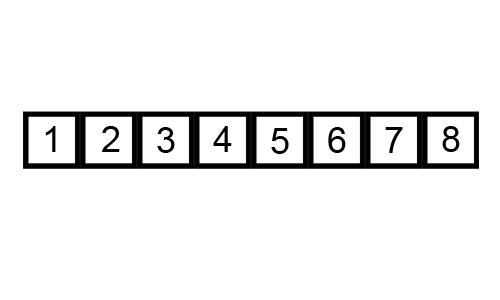
- BUBBLE SORT는 항상 거의 최악이다
- 매번 swap이 굉장히 많이 발생하기 때문. 단위연산을 비교가 아니라 swap 연산으로 해보면 최악의 경우 N^2이 된다.(SELECTION의 경우 최악이더라도 N^2)
- 쨌든 지금 비교 연산을 단위연산으로 하기 때문에 O(N^2)이 된다.
INSERTION SORT
- 이름 그대로 INSERT 일 때 사용된다
- 일단 제일 첫 원소(다음의 경우 6)가 이미 존재한다는 가정에서 시작

- 즉 sorted array에 insert할 때처럼 자기가 들어갈 위치를 찾고, 그 다음 원소들을 moving down시켜 공간을 만든 후, 그 공간에 삽입한다.
- 비교 연산만 놓고 보면 효율이 제일 좋다.
- 하지만 삽입시 그 뒤의 칸들을 모두 한 칸씩 옮겨야한다는 점을 고려하면 별로
- +) 뒤에서부터(큰 값인 것부터) 정렬하면 비교 횟수를 줄일 수 있다.
HEAP SORT
- Recall that: Heap is a Binary Tree that satisfies these special SHAPE and ORDER properties.
- SHAPE: must be a COMPLETE BINARY TREE
- ORDER: 부모 노드의 값이 자식들보다 반드시 더 커야 함
- HEAP을 array로 표현할 때 가지는 장점
- 인덱스를 통해 random access 가능
- heap자체가 complete binary tree이므로 메모리의 낭비가 없음
- 따라서 heap의 경우에는 adjacency list(linked list형태)보다 배열로 구현하는 것이 더 이득임
- HEAP SORT APPROACH
- make the unsorted array into a heap
- then repeat below steps
- take the root(maximum) element off the heap
- Reheap the remaining unsorted elements
- 그런데 위의(2~4번) 과정은 이미 HEAP이 만들어졌다는 가정임.
- 그렇다면 1번에서 소개한, 진짜 SORT가 아예 되어있지 않은, 그냥 just COMPLETE BINARY TREE인 상태에서 어떻게 HEAP을 만들 수 있을까?(BST도 아님. 진짜 그냥 binary tree인 경우), 단, complete binary tree라는 전제는 반드시 있어야 함
- Building Heap From Unsorted Array
-
Leaf nodes are already heaps(그 자체로 이미 HEAP)
-
Move up a level in tree and continue reheaping until we reach the root node
-
code로 구현한 것
#ifndef HEAPSORT_H #define HEAPSORT_H template<class ItemType> void ReheapDown(ItemType elements[], int root, int bottom); template<class ItemType> void HeapSort(ItemType values[], int numValues); template<class ItemType> void ReheapDown(ItemType elements[], int root, int bottom) // Post: Heap property is restored. { int maxChild; int rightChild; int leftChild; leftChild = root * 2 + 1; rightChild = root * 2 + 2; if (leftChild <= bottom) { if (leftChild == bottom) maxChild = leftChild; else { if (elements[leftChild] <= elements[rightChild]) maxChild = rightChild; else maxChild = leftChild; } if (elements[root] < elements[maxChild]) { Swap(elements[root], elements[maxChild]); ReheapDown(elements, maxChild, bottom); } } } template<class ItemType> void HeapSort(ItemType values[], int numValues) // Pre: Struct HeapType is available. // Post: The elements in the array values are sorted by key. { int index; // Convert the array of values into a heap. //자식을 가지고 있는 (leaf가 아닌) 부모들부터 ReheapDown을 진행 - leaf는 이미 그 자체가 heap이므로 //numValues / 2 - 1부터 0까지는 부모들의 인덱스임 for (index = numValues / 2 - 1; index >= 0; index--) ReheapDown(values, index, numValues - 1); //즉 각 subtree마다!!! ReheapDown을 해주는 것(각 부모를 루트로 서브트리임) // Sort the array. 이 과정은 걍 굳이..? 그냥 따로 배열 하나 만들어서 //루트들 빼서 저장하는 게 더 낫다고 교수님께서 말씀하심 for (index = numValues - 1; index >= 1; index--) { Swap(values[0], values[index]); ReheapDown(values, 0, index - 1); } } #endif
-
- Reheap을 통해 heap을 빌딩하는 것은 O(
- 따라서 HeapSort는 O()

QUICK SORT
- 비교횟수를 정확하게 파악하기 어렵다. 최악의 경우에는 이지만 평균적으로는 ; it depends on the order of original array
- Quick Sort에서의 최악의 경우: pivot이 전체 배열에서의 최소(혹은 최댓)값
- 투 포인터 알고리즘.
- LEFT에서 PIVOT보다 큰지 작은지를 판단할 원소를 가르키는 포인터(쭉 이동하면서)
- RIGHT에서 PIVOT보다 큰지 작은지를 판단할 원소를 가르키는 포인터(쭉 이동하면서)
- 즉, 각 split 한 번마다 전체 배열에서 pivot인 원소의 위치가 결정되는 것
- 수업에서 구현한, 배운 코드는 아래의 gif와는 조금 다르다.걍 참고용

MERGE SORT
- 대소 관계 상관 없이 일단 자름(재귀적으로 최소 단위가 될 때까지 일단 계속 쪼갬)!
- 그리고 잘린 결과인 각 파트마다 SORT한 후 합침
- 추가적인 공간이 필요함(공간의 재활용을 통해서 그렇지 않은 경우의 1/2 수준으로 줄일 수 있음)
- O(

SORTING OBJECTS
- sort시 object 자체가 아니라! 포인터 배열을 만들어서, 그 object들 각각을 가르키는 포인터를 변경함
- 즉 포인터가 가르키는 것을 변경함
- 객체의 크기가 클수록 이 방법이 훨씬 효율적임

STABILITY
- STABLE SORT: preserves the order of duplicates
- only HeapSort,QuickSort and SelectionSort are inherently unstable


SEARCHING
- Linear (or sequential) searching: 순차검색
- High-probability ordering: 가장 그럴싸한 부분부터 검색(ex.보간 검색)
- Key Ordering: 키를 중심으로 찾기
BINARY SEARCH
- 전제 조건: 배열이 미리! 정렬되어있어야 함!
HASHING
- Sort,Search알고리즘이라기보다는 입력/삭제에 대한 알고리즘임
- search를 최적화하기 위해 입력할 때부터 hash function을 활용하는 것
- 즉, data를 어떻게 배치할 것인가
- 그런데 Hash function을 통해 얻은 값이 중복될 수 있다. 이 경우 collision을 어떻게 해결할 것인가?
- Linear Probing(closed hashing)
- hash function을 통해 얻은 인덱스 값의 칸에서 충돌이 날 때, 비어있는 칸을 만날 때까지 한 칸씩 내려간 후 삽입
- [단점] Delete시에! 삭제될 칸 아래의 요소들을 한 칸씩 땡겨주어야! 다음 찾기에서 empty라고 착각되는 불상사를 막을 수 있음
- Rehashing
- 걍 다시 hash해서 다른 값을 얻어내기
- Buckets and Chaining(open hashing)
- Bucket: 특정 해시 위치와 연결된 요소들의 모임
- Chain: 동일한 해시 함수를 공유하는 요소들로 이루어진 linked list
- 즉 각 인덱스 값에 중복된 애들을 list 형태로 두는 것 - 각 인덱스 칸에 linked list형태로 연결되어 있음
- [단점]메모리 공간이 얼마나 필요할 지 예측이 되지 않음
- Linear Probing(closed hashing)
- 2 ways to minimize collisions
- Increase the range of the hash function
- Distribute elements as unifomly as possible throughout the hash table
- 좋은 hash function을 만들기 위해서는 statistical distribution에 대한 지식을 가지고 있어야 함
RADIX SORT
- [전제] 데이터들의 자릿수들의 거의 일치한다는 것을 알고 있음
{kind=link}

멋진 개발자가 될 거야