Functions, Tools and agents with Langchain - 4
L4. Tagging and Extraction
- OpenAI function의 main usecase인 Tagging, Extraction에 대해 실습
Tagging
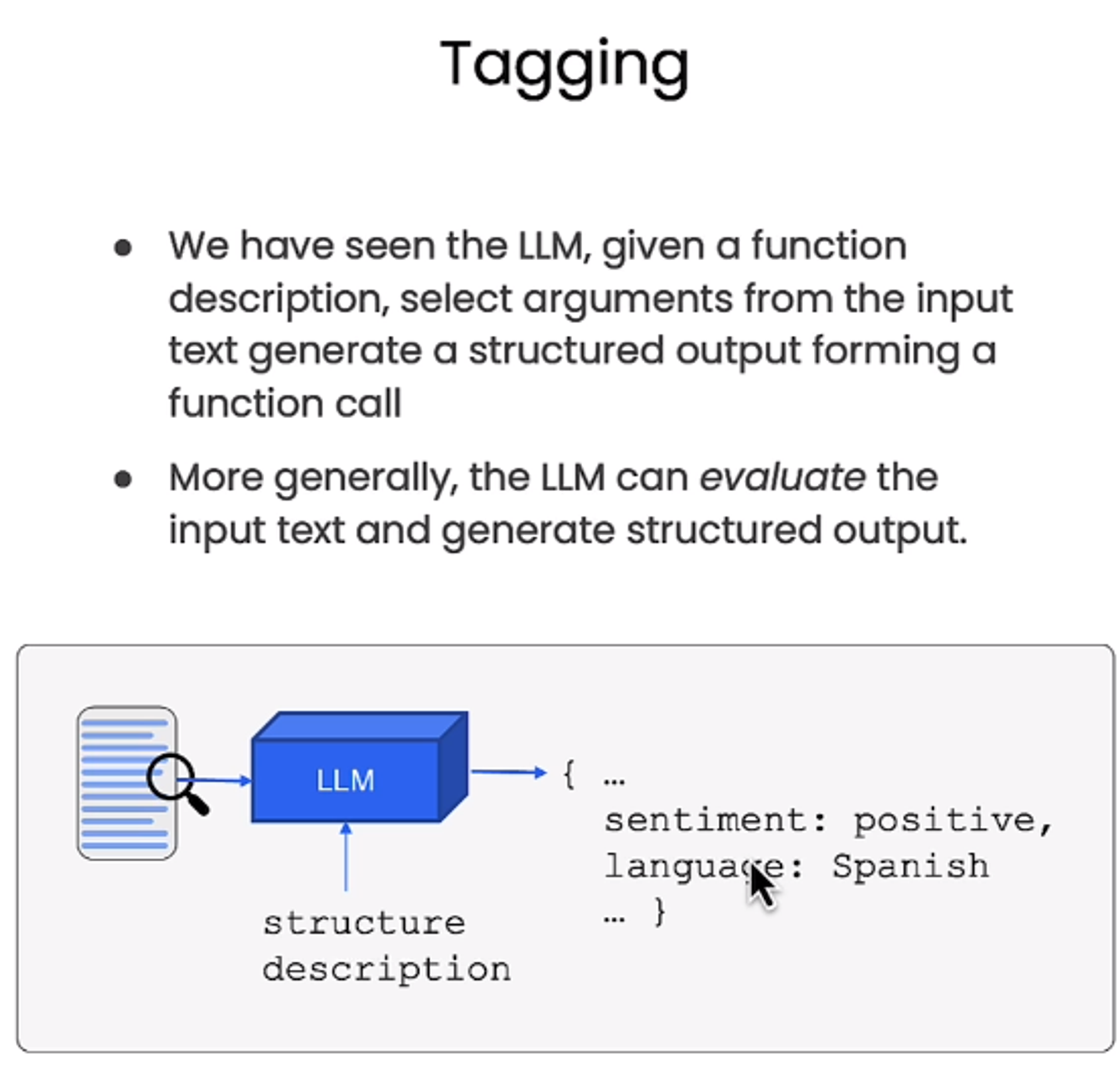
- LLM이 구문을 분석해서 추론하여 태깅해준 후 구조화된 output으로
Extraction

- single output이아닌 문서 전체를 본다
Tagging and Extraction Using OpenAI functions
from typing import List
from pydantic import BaseModel, Field
from langchain.utils.openai_functions import convert_pydantic_to_openai_function
class Tagging(BaseModel):
"""Tag the piece of text with particular info."""
sentiment: str = Field(description="sentiment of text, should be `pos`, `neg`, or `neutral`")
language: str = Field(description="language of text (should be ISO 639-1 code)") # llm에 들어가야하기 때문에 지정해줘야함
convert_pydantic to_openai_function(Tagging)
# 결과
{'name': 'Tagging',
'description': 'Tag the piece of text with particular info.',
'parameters': {'title': 'Tagging',
'description': 'Tag the piece of text with particular info.',
'type': 'object',
'properties': {'sentiment': {'title': 'Sentiment',
'description': 'sentiment of text, should be `pos`, `neg`, or `neutral`',
'type': 'string'},
'language': {'title': 'Language',
'description': 'language of text (should be ISO 639-1 code)',
'type': 'string'}},
'required': ['sentiment', 'language']}}
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models improt ChatOpenAI
model = ChatOpenAI(temperature=temperature)
tagging_functions = [convert_pydnatic_to_openai_function(Tagging)]
prompt = ChatPromptTemplate.from_messages([
("system", "Think carefully, and then tag the text as instructed"),
("user", "{input}")
])
model_with_functions = model.bind(
functions=tagging_functions,
function_call={"name": "Tagging"}
)
tagging_chain = prompt | model_with_functions
tagging_chain.invoke({"input": "I love langchain"})
# 결과
AIMessage(content='', additional_kwargs={'function_call': {'name': 'Tagging', 'arguments': '{\n "sentiment": "pos",\n "language": "en"\n}'}})
tagging_chain.invoke({"input": "non mi piace questo cibo"})
# 결과
AIMessage(content='', additional_kwargs={'function_call': {'name': 'Tagging', 'arguments': '{\n "sentiment": "neg",\n "language": "it"\n}'}})
# 결과를 예쁘게 출력하기 위해 Parser 추가
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
tagging_chain = prompt | model_with_functions | JsonOutputFunctionsParser()
tagging_chain.invoke({"input": "non mi piace questo cibo"})Extraction
- Extraction은 tagging과 비슷하지만, 정보의 여러 조각을 뽑아낸다
from typing import Optional
class Person(BaseModel):
"""Information about a person."""
name: str = Field(description="person's name")
age: Optional[int] = Field(description="person's age")
class Information(BaseModel):
"""Information to extract."""
people: List[Person] = Field(description="List of info about people")
convert_pydantic_to_openai_function(Information)
# 결과
{'name': 'Information',
'description': 'Information to extract.',
'parameters': {'title': 'Information',
'description': 'Information to extract.',
'type': 'object',
'properties': {'people': {'title': 'People',
'description': 'List of info about people',
'type': 'array',
'items': {'title': 'Person',
'description': 'Information about a person.',
'type': 'object',
'properties': {'name': {'title': 'Name',
'description': "person's name",
'type': 'string'},
'age': {'title': 'Age',
'description': "person's age",
'type': 'integer'}},
'required': ['name']}}},
'required': ['people']}}
extraction_functions = [convert_pydantic_to_openai_function(Information)]
# extraction_functions만 쓰도록 강제
extraction_model = model.bind(functions=extraction_functions, function_call={"name": "Information"})
extraction_model.invoke("Joe is 30, his mom is Martha")
# 결과
AIMessage(content='', additional_kwargs={'function_call': {'name': 'Information', 'arguments': '{\n "people": [\n {\n "name": "Joe",\n "age": 30\n },\n {\n "name": "Martha",\n "age": 0\n }\n ]\n}'}})
# 좋은 결과를 위해 프롬프트 추가
prompt = ChatPromptTemplate.from_messages([
("system", "Extract the relevant information, if not explicitly provided do not guess. Extract partial info"),
("human", "{input}")
])
extraction_chain = prompt | extraction_model
extraction_chain.invoke({"input": "Joe is 30, his mom is Martha"})
# 결과
AIMessage(content='', additional_kwargs={'function_call': {'name': 'Information', 'arguments': '{\n "people": [\n {\n "name": "Joe",\n "age": 30\n },\n {\n "name": "Martha"\n }\n ]\n}'}})
# 파서 추가
extraction_chain = prompt | extraction_model | JsonOutputFunctionsParser()
extraction_chain.invoke({"input": "Joe is 30, his mom is Martha"})
# 결과
{'people': [{'name': 'Joe', 'age': 30}, {'name': 'Martha'}]}
# 리스트가 필요한거지 people이라는 키는 중요하지 않으므로 다른 parser로 해결
from langchain.output_parser import JsonKeyOutputFunctionsParser
extraction_chain = prompt | extraction_model | JsonKeyOutputFunctionsParser(key_name="people")
extraction_chain.invoke({"input": "Joe is 30, his mom is Martha"})
# 결과
[{'name': 'Joe', 'age': 30}, {'name': 'Martha'}]Doing it for real
- 실제 웹 페이지에서 태깅, 추출하는 예제
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
documents = loader.load() # 리스트에 원소 하나
doc = documents[0]
doc.metadata
# 출력 - 메타데이터 자동으로 요약?
{'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/',
'title': "LLM Powered Autonomous Agents | Lil'Log",
'description': 'Building agents with LLM (large language model) as its core controller is a cool concept. Several proof-of-concepts demos, such as AutoGPT, GPT-Engineer and BabyAGI, serve as inspiring examples. The potentiality of LLM extends beyond generating well-written copies, stories, essays and programs; it can be framed as a powerful general problem solver.\nAgent System Overview In a LLM-powered autonomous agent system, LLM functions as the agent’s brain, complemented by several key components:',
'language': 'en'}
page_content = doc.page_content[:10000] # 글자가 매우 많기 때문에 10000개만 담기
#### 예제 1 Tagging
# 함수 작성
class Overview(BaseModel):
"""Overview of a section of text."""
summary: str = Field(description="Provide a concise summary of the content.")
language: str = Field(description="Provide the language that the content is written in.")
keywords: str = Field(description="Provide keywords related to the content.")
overview_tagging_function = [
convert_pydantic_to_openai_function(Overview)
]
tagging_model = model.bind(
functions=overview_tagging_function,
function_call={"name":"Overview"}
)
tagging_chain = prompt | tagging_model | JsonOutputFunctionsParser()
tagging_chain.invoke({"input": page_content})
# 결과
{'summary': 'This article discusses the concept of building autonomous agents powered by LLM (large language model) as their core controller. It explores the key components of such agent systems, including planning, memory, and tool use. It also covers various techniques for task decomposition and self-reflection in autonomous agents. The article provides examples of case studies and challenges in implementing LLM-powered agents.',
'language': 'English',
'keywords': 'LLM, autonomous agents, planning, memory, tool use, task decomposition, self-reflection, case studies, challenges'}
#### Extraction 예제
# 함수 작성
class Paper(BaseModel):
"""information about papers mentioned."""
title: str
autor: Optional[str]
class Info(BaseModel):
"""information to extract"""
papers: List[Paper]
paper_extarction_function = [
convert_pydantic_to_openai_function(Info)
]
extraction_model = model.bind(
functions=paper_extraction_function,
function_call={"name":"Info"}
)
extraction_chain = prompt | extraction_model | JsonKeyOutputFunctionParser(key_name="papers")
# 10000자로만 테스트
extraction_chain.invoke({"input": page_content})
# 결과
[{'title': 'LLM Powered Autonomous Agents', 'author': 'Lilian Weng'}]
# 추출을 위한 프롬프트 작성. 추출 작업 시 할루시네이션을 방지하기 위해 구체적으로 추출만 하고 없으면 없다고 하라고 명시
# 이를 system message로 넣어줌
template = """A article will be passed to you. Extract from it all papers that are mentioned by this article.
Do not extract the name of the article itself. If no papers are mentioned that's fine - you don't need to extract any! Just return an empty list.
Do not make up or guess ANY extra information. Only extract what exactly is in the text."""
prompt = ChatPromptTemplate.from_messages([
("system", template),
("human", "{input}")
])
extraction_chain = prompt | extraction_model | JsonKeyOutputFuctionsParser(key="papers")
extraction_chain.invoke({"input": page_content})
# 결과
[{'title': 'Chain of thought (CoT; Wei et al. 2022)', 'author': 'Wei et al.'},
{'title': 'Tree of Thoughts (Yao et al. 2023)', 'author': 'Yao et al.'},
{'title': 'LLM+P (Liu et al. 2023)', 'author': 'Liu et al.'},
{'title': 'ReAct (Yao et al. 2023)', 'author': 'Yao et al.'},
{'title': 'Reflexion (Shinn & Labash 2023)', 'author': 'Shinn & Labash'},
{'title': 'Chain of Hindsight (CoH; Liu et al. 2023)',
'author': 'Liu et al.'},
{'title': 'Algorithm Distillation (AD; Laskin et al. 2023)',
'author': 'Laskin et al.'}]
### 전체 문서에 실행, 전체 문장이 길기 때문에 잘라서 실행하기 위해
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_overlap=0) # chunk에 따라 정보가 손실될수도 있는데 여기선 overlap 0으로 설정
splits = text_splitter.split_text(doc.page_content) # 실행해보면 14개의 chunk로 잘림
# 후처리를 위한 함수. chunk별로 나온 리스트들을 합치기 위해
def flatten(matrix):
flat_list = []
for row in matrix:
flat_list += row
return flat_list
# 위의 split 과정을 RunnableLambda와 map을 활용하여 한번에 처리해보자
from langchain.schema.runnable import RunnableLambda
prep = RunnableLambda(
lambda x: [{"input": doc} for doc in text_splitter.split_text(x)]
)
chain = prep | extraction_chain.map() | flatten
chain.invoke(doc.page_content)
# 결과
[{'title': 'AutoGPT', 'author': ''},
{'title': 'GPT-Engineer', 'author': ''},
{'title': 'BabyAGI', 'author': ''},
{'title': 'Chain of thought (CoT; Wei et al. 2022)', 'author': ''},
...
{'title': 'Park et al. 2023', 'author': ''},
{'title': 'Super Mario: How Nintendo Conquered America', # 코드 블록 속에 주석 내용이 논문명으로 들어감
'author': 'Jeff Ryan'},
{'title': 'Model-View-Controller (MVC) Explained', 'author': 'Techopedia'},
{'title': 'Python Game Development: Creating a Snake Game',
'author': 'Real Python'},
{'title': 'Paper A', 'author': 'Author A'}, # 여기서 잘 이해가 안가는데 prompt에 대한 내용이 들어가면 llm이 헷갈려서 이런식으로 나온다고..?
{'title': 'Paper B', 'author': 'Author B'},
{'title': 'Paper C', 'author': 'Author C'},
...
{'title': 'HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace',
'author': 'Shen et al.'},
{'title': 'ChemCrow: Augmenting large-language models with chemistry tools.',
'author': 'Bran et al.'},
{'title': 'Emergent autonomous scientific research capabilities of large language models.',
'author': 'Boiko et al.'},
{'title': 'Generative Agents: Interactive Simulacra of Human Behavior.',
'author': 'Joon Sung Park, et al.'}]
라이브데이터 Developer