수정된 구조
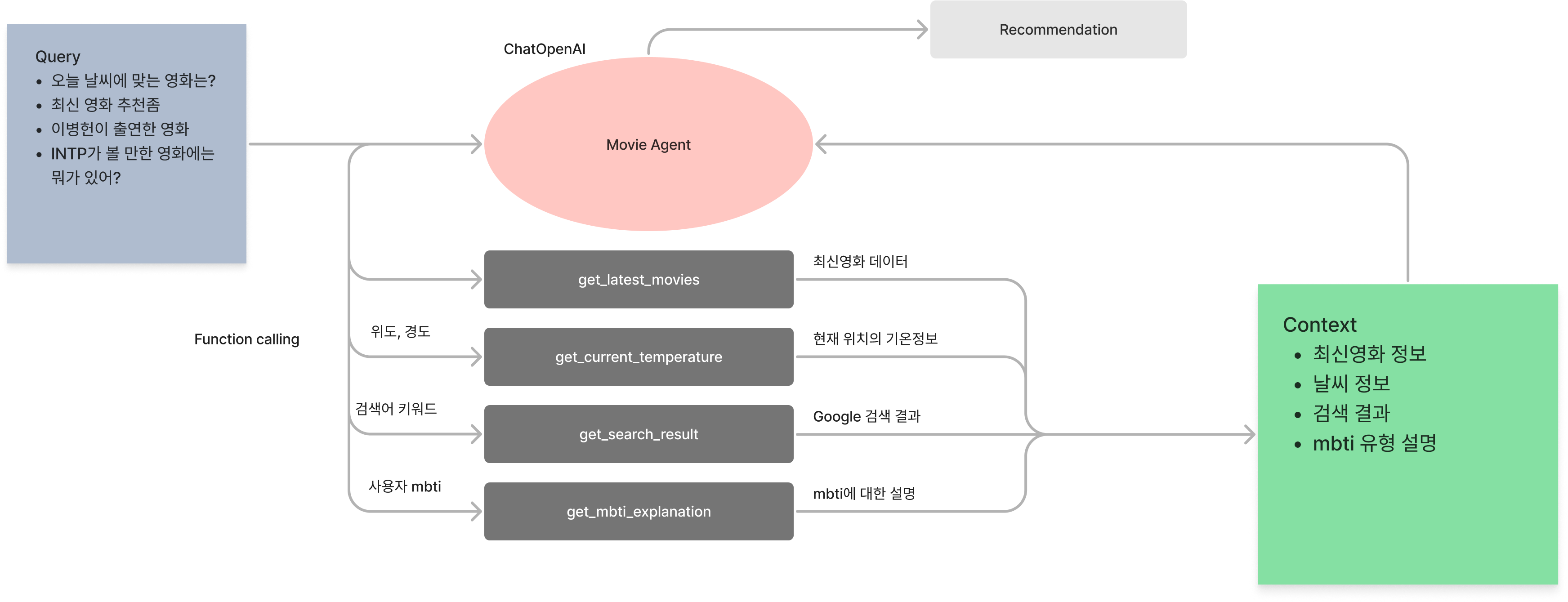
Agent Executor
- 지난번 시도에서는 retriever와 rewriter 두 부분으로 나누었다.
- 이를 Agent Executor를 이용해 하나의 에이전트로 만들었다.
- Agent Executor란 agent의 runtime으로, 어떤 action을 취할 지 결정하고 action을 취한 결과 output(observation)을 agent에 넘겨주면서 Stop condition(AgentFinish)을 만족할때까지 반복한다.
- 이를 이용하여 시스템 프롬프트에 각 행동을 명시하고 각 상황에 맞는 tool을 쓰라고 명시했다.
prompt1_system = """
You are a kind recommender for movies and your goal is to recommend movies. You can also retrieve informations with available tools.
Given User {input}, figure out the user's intentions and decide which tool to use. Try to use available tools
For successful retrieval, I will give some examples
- Latest movies
If user asked like this examples '최신영화 정보', '요새 볼만한 영화 없나',
You can give informations about latest movies or 최신 영화, use 'get_latest_movies' tool.
- MBTI Personality
If you think user need information about personality, you can reference this {mbti_list}. For example, 잇티제 means ISTJ, '인팁' means INTP
match personality and use 'get_mbti_explanation' function.
- Weather information
If you think user need weather information, you can use 'get_current_temperature' function. If you don't have user information, define user is in Seoul, Korea and use the function.
- More informations
If user wants MORE informations, use 'get_serpapi_search' with extracted movie, director or cast name.
When finished, go to Final Step.
- Final Step
Use what you retrieved.
When you recommend movies, you should answer based on this {recommend_format} structure.
Remember that your goal is to recommend movies!
"""
recommend_format = """
- <Short greetings>
- <movie name> - <plot>
- <movie name> - <plot>
- <movie name> - <plot>
- <Explanation about your recommendation in more than two sentences>
- <Greetings>
***ANSWER IN KOREAN!!***
"""
mbti_list = """
| mbti | 한국어 |
| --- | --- |
| ISTJ | 잇티제 |
| INTJ | 인티제 |
| ESTJ | 엣티제 |
| ENTJ | 엔티제 |
| ISFJ | 잇프제 |
| INFJ | 인프제 |
| ESFJ | 엣프제 |
| ENFJ | 엔프제 |
| ISTP | 잇팁 |
| INTP | 인팁 |
| ESTP | 엣팁 |
| ENTP | 엔팁 |
| ISFP | 잇프피 |
| INFP | 인프피 |
| ESFP | 엣프피 |
| ENFP | 앤프피 |
"""Agent Executor 코드
import openai
from langchain.chat_models import ChatOpenAI
from langchain.tools.render import format_tool_to_openai_function
from langchain.prompts import ChatPromptTemplate
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.agents import AgentExecutor
from langchain.prompts import MessagesPlaceholder
from langchain.schema.runnable import RunnablePassthrough
from langchain.memory import ConversationBufferWindowMemory
from langchain.agents.format_scratchpad import format_to_openai_functions
from prompts import *
# Tools
from Tools.search import get_serpapi_search
from Tools.temperature import get_current_temperature
from Tools.mbti import get_mbti_explaination
from Tools.latest import LatestmovieTool
# utils
from utils import get_openai_api_key
openai.api_key = get_openai_api_key()
memory = ConversationBufferWindowMemory(return_messages=True, memory_key='chat_history', input_key='input', k=5)
functions = [
format_tool_to_openai_function(f) for f in [get_current_temperature, get_serpapi_search, get_mbti_explaination]
]
prompt1 = ChatPromptTemplate.from_messages([
("system", prompt1_system),
MessagesPlaceholder(variable_name='chat_history'),
("user", "{input}"),
MessagesPlaceholder(variable_name='agent_scratchpad')
])
model = ChatOpenAI(temperature=0.4, max_tokens=1024, streaming=True).bind(functions=functions)
retrieval_chain = RunnablePassthrough.assign(
agent_scratchpad = lambda x: format_to_openai_functions(x["intermediate_steps"])
) | prompt1 | model | OpenAIFunctionsAgentOutputParser()
agent_executor = AgentExecutor(agent=retrieval_chain, tools=[get_current_temperature, get_serpapi_search, get_mbti_explaination, LatestmovieTool()], memory=memory, verbose=True)- memory를 사용하여 이전 대화의 input, output을 기억하여 대화의 맥락을 기억하게 했다.
- Agent scratchpad를 추가하여 agent가 각 스텝마다 어떤 행동을 취했는지 기억하게 해준다.
결과
memory 사용


- 대화 기억 확인
tool 사용
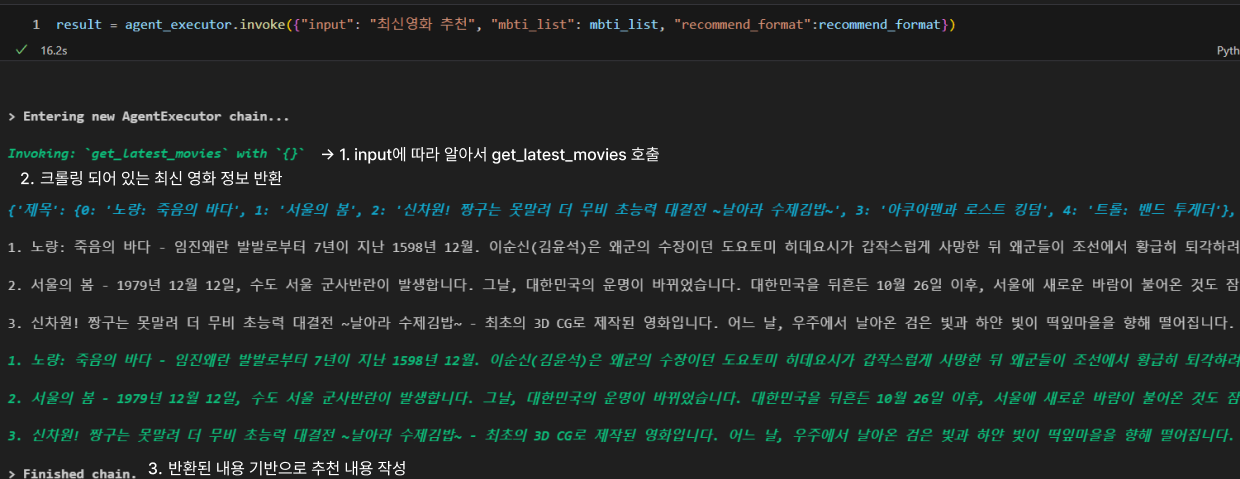
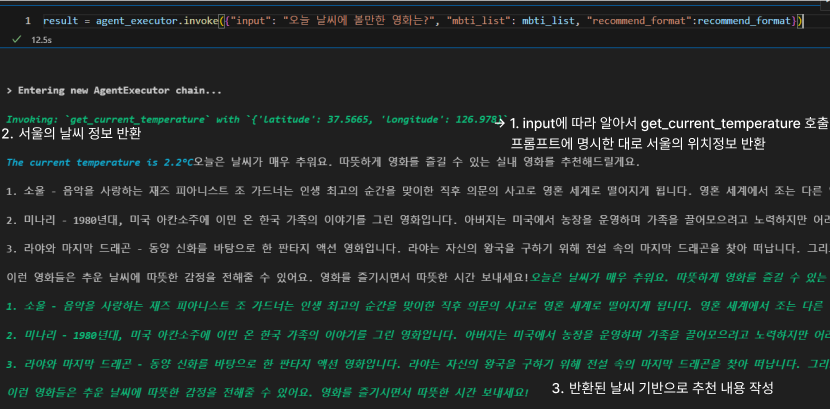
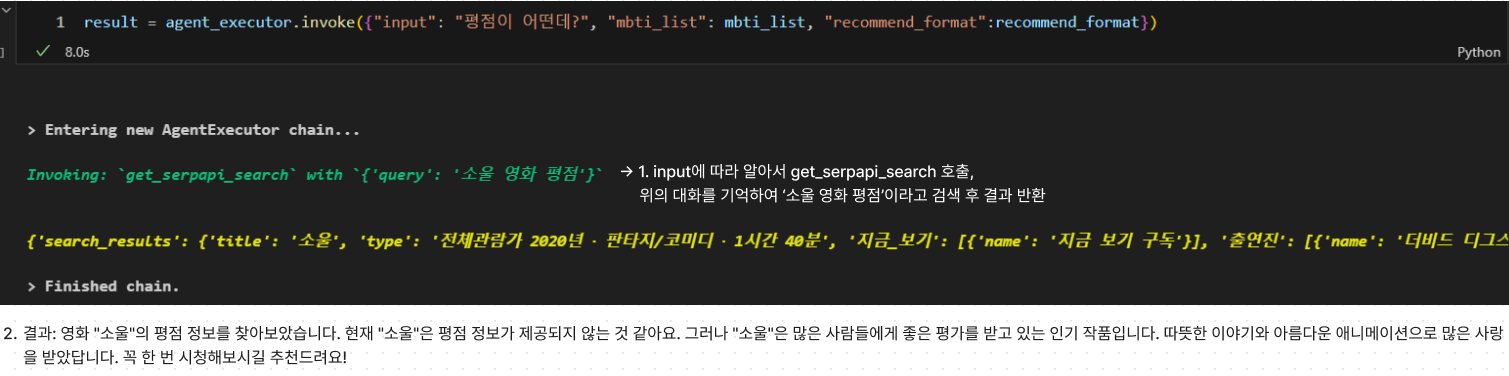
- 대화 내용 기반으로도 잘 작동 확인
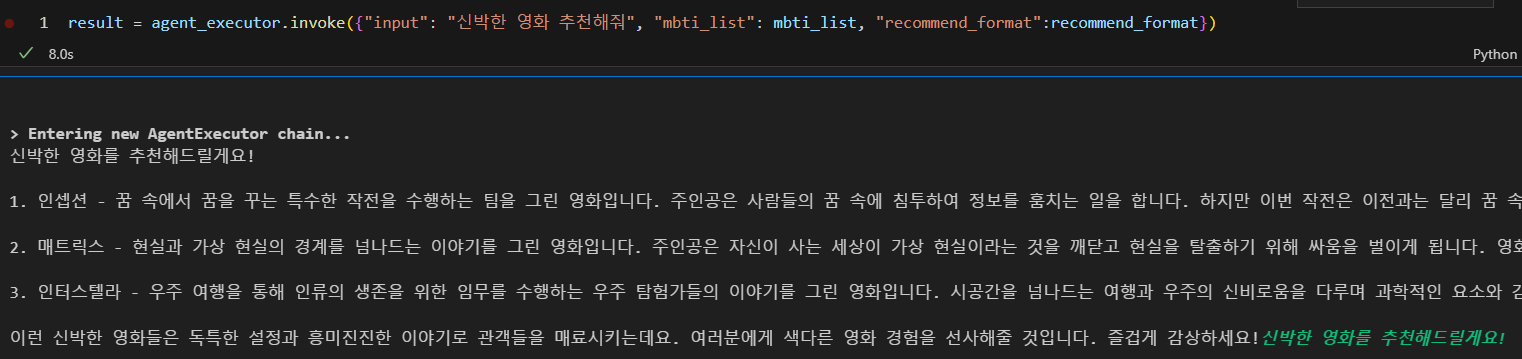
- tool을 호출하지 않고도 동작
Further Steps
RAG over csv data
RAG
- 크롤링한 데이터/ 한국어 임베딩 모델 사용
from langchain.document_loaders import CSVLoader
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.vectorstores import Chroma
embedding_function = SentenceTransformerEmbeddings(model_name="jhgan/ko-sroberta-multitask")
loader = CSVLoader('./data/daum_movie/data.csv', encoding='cp949')
documents = loader.load()
db = Chroma.from_documents(documents, embedding_function)
query = "음악 영화"
docs = db.similarity_search(query)
print(docs[0].page_content)관람가: 전체관람가
제목: 크레센도
평점: 10
예매율: 0.60%
개봉일: 2023-12-20
줄거리: “예술성, 테크닉, 기교, 드라마, 짜릿함. 그는 피아노 연주의 극치를 보여주었다!” 반 클라이번 국제 피아노 콩쿠르에 참여하기 위해 모인 세계 음악계의 유망주 30명. 갖은 역경, 희생, 좌절을 딛고 무대에 오른 젊은 피아니스트들이 하나 둘 탈락하는 가운데, 참여자들은 한 천재의 등장을 목도하게 된다. 그는 평범한 또래 소년과 같이 수수한 18살 피아니스트 임윤찬. 하지만 그의 연주가 시작되자마자 현장은 깊은 전율로 가득 차기 시작하는데… K-클래식 대표주자 ‘임윤찬’의 역사적인 우승 현장을 마주하다. 음악 팬들을 열광하게 할 12월, 단 하나뿐인 월드클래스 클래식 음악 영화!- 넷플릭스 데이터/ 영어 임베딩 모델 사용
from langchain.document_loaders import CSVLoader
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.vectorstores import Chroma
embedding_function = SentenceTransformerEmbeddings(model_name="BAAI/bge-small-en-v1.5")
loader = CSVLoader('./data/netflix/netflix_titles.csv')
documents = loader.load()
db = Chroma.from_documents(documents, embedding_function)
query = "Korean kitchen show"
docs = db.similarity_search(query)
print(docs[0].page_content)show_id: s6458
type: TV Show
title: Chef & My Fridge
director:
cast: Seong-joo Kim, Jung-hwan Ahn
country: South Korea
date_added: August 4, 2017
release_year: 2017
rating: TV-PG
duration: 2 Seasons
listed_in: International TV Shows, Korean TV Shows, Reality TV
description: The best chefs of Korea go head-to-head to create impromptu dishes that feature ingredients found inside the guest stars' very own refrigerators.- 내용 관한 질문에 대해서는 어느정도 잘 처리해 주지만, 평점 몇점 이상, 예매율 높은 영화 이런 내용적으로 추론해야 하는 질문은 잘 대답하지 못함.
Metadata 처리
- csv파일에 정보가 많을 수록 비용과 context length 오류가 자주 발생한다.
- 이를 효과적으로 처리하기 위해 metadata화 시켜 수치적인 데이터는 그대로 놔 두고 줄거리 같은 것들만 임베딩하여 처리
Self-Querying
- 내용적인 쿼리에는 결과가 괜찮았기 때문에 semantic한 문제가 아니라 다른 방법이 필요하다는 판단, self-querying 시도.
- Self-querying이란
- tmdb 데이터/ 영어 임베딩 모델 사용
- 사용해 봤지만 제대로 다루지 못하고 있음.. 이에 대해서는 다음 게시물에 올릴 예정
한계점
- 여전히 csv파일에 대한 만족할 만한 성능이 나오지 않음
- 여전히 context length 문제 발생
- Chain of Table에 대해서 시도해볼 예정
Reference

라이브데이터 Developer