What is an ERD?
ERD (Entity-Relationship Diagram) is a visual representation of the DB structure and gives us a visual representation on how our different entities (tables) relate to each other.
We will be using https://www.lucidchart.com/ to create our RDBMS ERD design.
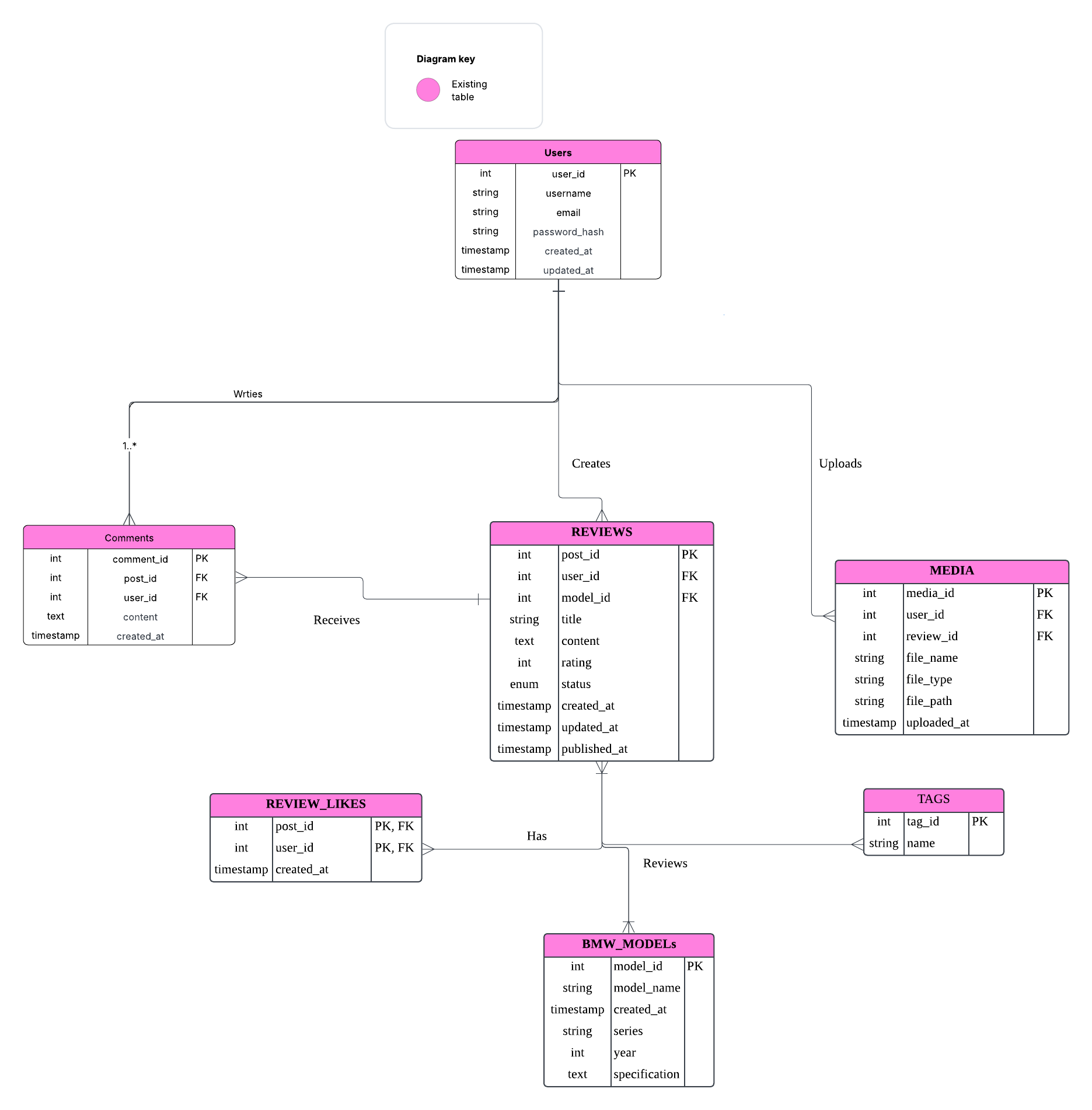
- Entities (Tables):
- Rectangles represent entities/tables
- Each entity contains its attributes (columns)
- PK means Primary Key
- FK means Foreign Key
- Relationships:
- Lines between entities show how they’re related
- Key Relationships shown:
- One user can create MANY posts
- one post can have MANY comments
- Posts & categories have a many-to-many relationship
- Users can like MANY posts
How does ERD help us?
It helps us visualize the DB structure and understand relationships between tables. We can plan our queries & data access patterns and makes it convenient to communicate the DB design with our team members and identify potential issues before implementation.
Logic behind our ERD design for FindMyBMW Review section
When we think about reviews, the core are creators and their content. This will lead us to 2 of our most fundamental entities: USERS and REVIEWS.
USERS and REVIEWS have a direct relationship, in which 1 user can create MANY posts.
Now, if we put in more thought and think about how readers interact with reviews. Readers don’t passively consume content - they engage in it. This brings us to our first layer of interaction features:
- COMMENTS: We allow users to comment on posts. This creates 2 relationships. (a) A user can write many comments (2) A post can receive many comments
Next, we need to think about content organization. When we visit any review, we notice that content is organized in multiple ways to help readers find what they’re looking for.
- BMW_MODELS: These are classifications on certain models such as BMW i5, BMW M4 …
We made these as a one-to-one relationship with REVIEWS because each review is for 1 specific model
- TAGS: These are more specific labels for things like “Great Performance”, “Fuel Efficient”, “Family Friendly”
Tags is many-to-many relationship as 1 review can belong to multiple categories (a post could be both “Fuel Efficient” and “Family Friendly”). Also, 1 category can contain MANY posts. Similarly, 1 post can have multiple tags, and 1 tag can be used on many posts.
For enhanced user engagement, we added social features:
- REVIEW_LIKES: Allows users to like posts
Finally, we considered content management with the MEDIA table. Modern reviews aren’t just text- they include images as well. The MEDIA table connects to USERS (who uploaded the files) and can be referenced in POSTS
Each table has carefully chosen fields:
- Timestamps (created_at, updated_at) for tracking chronological information
- Status fields (like in POSTS) to manage content workflow (draft → published → archived)
- Appropriate data types (VARCHAR for usernames, TEXT for longer content)
- review_id to directly link media to specific reviews → This helps organize photos for each car review
- Foreign keys to maintain data integrity
How does this structure help in specific features such as filtering reviews by model year or series?
- Filtering & Searching
The BMW_MODELS table structure allows us to have sophisticated querying. For instance, to find all reviews for BMW i5 from 2024. we can apply the following SQP query
SELECT r.*, b.*
FROM REVIEWS r
JOIN BMW_MODELS b ON r.model_id = b.model_id
WHERE b.series = 'i5'
AND b.year = 2024;- Statistical Analysis
With this structure we can gain insights about models and user engagement
-- Average rating by model and year
SELECT
b.model_name,
b.year,
AVG(r.rating) as avg_rating,
COUNT(r.review_id) as review_count
FROM BMW_MODELS b
LEFT JOIN REVIEWS r ON b.model_id = r.model_id
GROUP BY b.model_name, b.year;How can we maintain data integrity while supporting growth?
- Referential Integrity
- Every review must reference a VALID BMW model (enforced by foreign key model_id)
- If a BMW model is detected, we can prevent deletion if reviews exist (ON DELETE RESTRICT) or cascade the deletion (ON DELETE CASCADE)
- Comments can’t exit without their parent review (enforced by review_id foreign key)
ALTER TABLE REVIEWS
ADD CONSTRAINT fk_review_model
FOREIGN KEY (model_id)
REFERENCES BMW_MODELS(model_id)
ON DELETE RESTRICT;- Future Growth Capabilities
We can add new features which can be easily accomodated.
A. Adding New BMW Models
- The BMW_MODELS table can handle new series or types
- We could add columns like:
ALTER TABLE BMW_MODELS
ADD COLUMN body_type VARCHAR(50),
ADD COLUMN electric BOOLEAN;B. Enhanced Review Features:
- We could also add subcategories for ratings such as rate by “Performance” ,”Comfort”, “Value” …
CREATE TABLE RATING_CATEGORIES (
category_id INT PRIMARY KEY,
name VARCHAR(50) -- e.g., 'Performance', 'Comfort', 'Value'
);
CREATE TABLE REVIEW_DETAILED_RATINGS (
review_id INT,
category_id INT,
rating INT,
PRIMARY KEY (review_id, category_id),
FOREIGN KEY (review_id) REFERENCES REVIEWS(review_id),
FOREIGN KEY (category_id) REFERENCES RATING_CATEGORIES(category_id)
);C. Social Features Expansion:
- We can add additional features like: (1) Review Sharing (2) Expert Reviewer Badges
CREATE TABLE REVIEWER_EXPERTISE (
user_id INT,
expertise_level VARCHAR(50),
verified_date TIMESTAMP,
verification_proof TEXT,
PRIMARY KEY (user_id),
FOREIGN KEY (user_id) REFERENCES USERS(user_id)
);How is this structure for performance?
The structure allows for efficient indexing:
-- For faster model searches
CREATE INDEX idx_bmw_models_year_series
ON BMW_MODELS(year, series);
-- For quick rating lookups
CREATE INDEX idx_reviews_rating
ON REVIEWS(rating);Think of our DB like a massive library of BMW reviews. Without any organization system (indexes), finding a specific review would require looking through every single book (full table scan) - now imagine walking through every aisle, checking each book one by one. This is incredibly inefficient, especially as the library grows larger.
- Strategic Indexing
We can create indexes on frequently accessed columns.
CREATE INDEX idx_bmw_models_year_series ON BMW_MODELS(year, series);
This is like creating a card catalog in our library, organized by year and series. Now, when someone wants to find all 2024 i5 reviews, instead of checking every review, the DB can:
- Look up “2024” and “i5” in the index (like checking the card catalog)
- Jump directly to the relevant reviews (like going straight to the right shelf)
Without Index
EXPLAIN SELECT * FROM REVIEWS r
JOIN BMW_MODELS b ON r.model_id = b.model_id
WHERE b.year = 2024 AND b.series = 'i5';
-- This might scan all rows in both tablesWith Index
CREATE INDEX idx_bmw_models_year_series ON BMW_MODELS(year, series);
-- After creating the index
EXPLAIN SELECT * FROM REVIEWS r
JOIN BMW_MODELS b ON r.model_id = b.model_id
WHERE b.year = 2024 AND b.series = 'i5';
-- This uses the index to find matching rows immediately- Efficient Join Operations
Our one-to-one relationships between REVIEWS and BMW_MODELS is particularly efficient. When a user views a review, we need to fetch both the review content and the car details. Because each review is linked to exactly one model through model_id, the DB can quickly locate the matching records without scanning multiple possible matches.
-- This join operation is efficient because:
-- 1. model_id is the primary key in BMW_MODELS
-- 2. It's a foreign key in REVIEWS
-- 3. Each review has exactly one model
SELECT r.title, r.content, r.rating,
b.model_name, b.year, b.specifications
FROM REVIEWS r
JOIN BMW_MODELS b ON r.model_id = b.model_id
WHERE r.review_id = 123;Thus,
- Allows for strategic indexing on frequently searched columns
- Minimizes the number of joins needed for common operations
How does this help in data consistency?
The ‘enum’ status in REVIEWS helps maintain content quality:
ALTER TABLE REVIEWS
ADD CONSTRAINT valid_status
CHECK (status IN ('draft', 'pending', 'published', 'archived'));Takeaway
This structure is efficient in that
- Maintains clear ownership of content (every piece of content has user_id)
- Prevents orphaned records through foreign key constraints
- Allows for granular permissions and content moderation
- Supports complex queries without requiring table restructuring
- Enables easy addition of new features without breaking existing functionality
