자연어처리(NLP, Natural Language Processing)는 GPT 계열이 텍스트로부터 바로 학습하는 방식 덕분에 많은 발전을 해왔다.
반대로 computer vision에서는 여전히 레이블이 정의되어있으면서도 방대한 양의 데이터셋이 확보가 되어야 학습할 수 있는 표준 방식을 사용하고 있다. 이 방식은 범위가 제한된 클래스 수로 설계되고, 정의된 클래스만 예측하므로 유연성이 크게 제한되며, zero-shot transfer 성능 역시 크게 떨어진다.
하지만 만약 이미지를 텍스트를 통해 표현하도록 모델을 학습할 수 있다면, 이는 좋은 대안이 될 수 있다. 본 논문은 어떤 caption이 어떤 이미지에 대응하는지 예측하는 간단한 pre-training task가 현재 SOTA인 이미지 표현 방식을 효율적이고 확장 가능하게 하는 방식임을 보여준다.
학습 후에는 자연어를 통해 시각적 개념을 창조하여, 최종적으로 만들고자 하는 모델에 zero-shot transfer 또한 가능하게 할 수 있다.
즉 CLIP은 label 없이 텍스트 입력만으로 이미지를 찾아내고자 한다.
데이터 수집은 인터넷 상에서 이미지 및 이에 대한 캡션을 모두 긁어서 얻게 된다.

그 후 text encoder를 통해 벡터 형태로 나타낸다면, 이 벡터가 이미지 입장에서 label이 될 수 있을 것이다.
즉, image encoder 및 text encoder를 통해 얻은 image vector 및 text vector 사이의 관계를 학습하는 것이 핵심이 될 것이다. 이 두 vector가 비슷한 위치로 mapping 된다면 해당 text가 해당 image의 label이 될 것이다.
학습 방식은 다음과 같다.
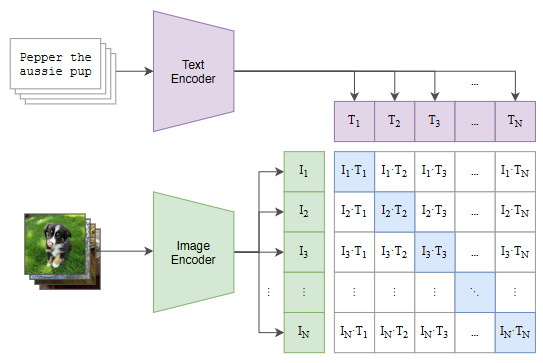
우선 image encoder는 ViT (Vision Transformer), text encoder는 Transformer를 사용해서 각 image vector, text vector를 얻어낸다. 그 후 두 vector의 cosine similarity를 사용해서 많은 vector들 중 한 객체를 표현하는 image와 text가 비슷한 위치에 mapping되도록 학습한다.
이후 학습 때 사용하지 않은 이미지를 학습된 image encoder에 통과시켜 벡터를 추출한 후, N 개의 text를 각각 text encoder에 통과시킨 벡터들과 cosine similarity를 계산하여 inference를 진행한다.
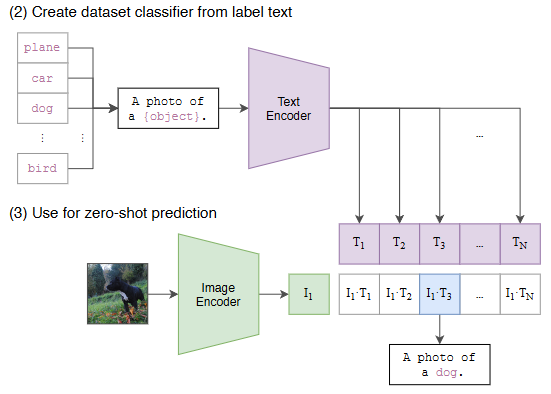
CLIP의 zero-shot transfer의 성능을 가장 직관적으로 나타낸 figure를 보면,

ImageNet에 있는 바나나 데이터로 학습했을 때 결과가 비슷하지만, 학습된 모델로 다른 데이터셋의 바나나에 적용하면 CLIP의 효력을 확실하게 볼 수 있다.
