1. Abstract & Introduction
Transformer 기반의 구조는 번역과 같은 시퀀스 모델에서 최고의 성능을 보여줬지만, image captiong과 같은 multi-modal task에서는 아직 충분한 연구가 수행되지 않았다.
본 논문은 image captioning task를 수행하기 위한 Meshed-memory Transformer 모델을 제안한다.
모델의 구조는 우선 encoder 부분에서 개의 이미지 영역과 그들의 관계가 multi-level로 인코딩 되도록 하는데, 이런 구조 덕분에 low-level, high-level 모든 관계를 고려할 수 있게 된다. Decoder 또한 low / high-level 한 시각적 관계를 모두 탐험하는 multi-layer 구조로 되어 문장을 생성해낸다.
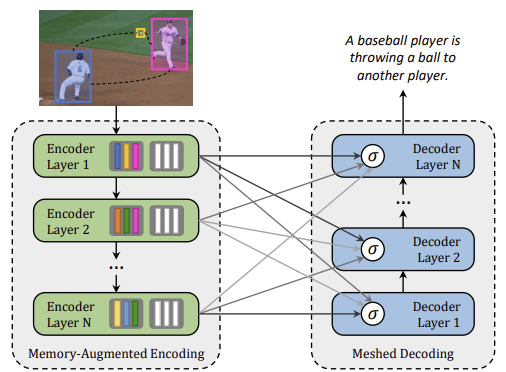
2. Method (Meshed-Memory Transformer)
모델은 encoder, decoder 모듈로 나눠서 볼 수 있고, 두 모듈 모두 여러 개의 attention layer가 쌓여있는 구조이다.
Intra-modal, 단어와 이미지 간의 cross-modal 모두 recurrence가 아닌 scaled dot-product attention 연산을 수행한다.
위의 연산은 Transformer 구조가 처음 제안된 'Attention is all you need (NeurIPS 2017)' 논문에서 제안된 수식이고, 는 각각 query, key, value로 입력 시퀀스를 임베딩 벡터로 변환하여 만들어진 벡터들이다.
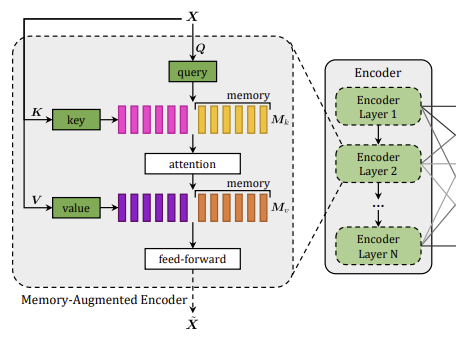
2.1. Memory-augmented encoder
이미지 내에서 뽑은 이미지 영역 집합 가 있을 때, self-attention을 통해 encoding 정보 를 얻을 수 있다.
는 학습 가능한 가중행렬이고, 이 가중행렬을 통해 input feature인 를 투영시켜 를 얻는다.
Self-attention을 통해 input feature 간의 관계를 encoding하게 된다.
하지만 self-attention만으로 '사전 지식'까지는 encoding할 수 없다. 예를 들어, 사람과 야구공이 input feature로 뽑혔을 때, 사람은 player, game 등으로 추리할 수 있지만, 컴퓨터는 그런 사전 지식이 없다.
2.1.1. Memory-augmented attention
이러한 self-attention의 한계를 극복하기 위해 본 논문은 memory-augmented attention을 제안한다. Memory-augment, 말 그대로 메모리를 증강하는 방법으로, key와 value에 사전 정보를 encoding 할 수 있는 slot을 추가하여 확장하는 것이다.
위 수식에서 는 학습 가능한 가중 행렬이고, key와 value는 이 행렬들을 각각 concatenate하여 확장된다.
이렇게 구성된 query, key, value로 self-attention 수행 시, 에 아직 임베딩 되지 않는 사전 지식을 가져올 수 있다.
는 각 encoder head 마다 다르게 구성된다.
2.1.2. Encoding layer
Memory-augmented attention 연산을 통해 나온 출력값은 두 개의 Feed forward layer를 통과한다. 또한, 기존의 transformer 구조와 같이 self-attention layer, feed forward layer 모두 residual connection과 layer normalization을 적용한다.
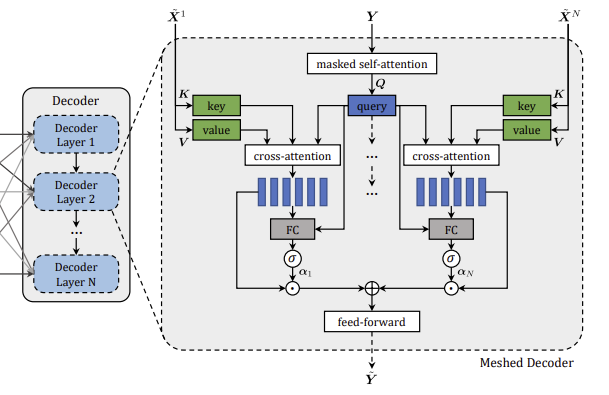
2.2. Meshed Decoder
디코더는 encoding된 이미지 영역과 이전 시점에 생성된 단어 모두에 conditioning되어 다음 단어를 예측한다. 인코더를 통해 이미지의 multi-level representation을 얻었는데, 본 논문은 meshed attention 연산을 제안하여 기존의 Transformer에서 제안된 cross-attention 연산과 다르게 단어를 생성하기 위해 모든 encoding layer를 고려하게 된다.
2.2.1. Meshed cross-attention
개의 encoder layer에서 나온 출력값 에 대해, 디코더의 입력 시퀀스 벡터 와 이 모든 들 간의 cross-attention 연산을 수행한다. 그 후, 각 cross-attention 결과와 같은 크기의 가중 행렬 를 통해 cross-attention 결과를 조정한 후 더하여 출력값을 얻는다.
2.2.2. Architecture of decoding layer
이전에 Transformer에서 소개된 내용과 마찬가지로, 본 논문 또한 masked self-attention을 통해 다음 단어를 이전 시점에서 예측된 단어들에만 의존하여 예측할 수 있도록 한다. Masked self-attention을 통해 얻은 query와 encoder layer에서 얻은 개의 key, value 간의 cross-attention을 수행한다.
Decoder layer 또한 encoder layer와 마찬가지로 feed forward layer, 각 component마다 residual connection, layer normalization을 적용한다.
2.3. Training Details
본 논문은 우선 단어 수준의 cross-entropy loss로 모델을 pre-training한 후, 강화학습을 통해 시퀀스 생성을 fine-tuning한다.
강화학습 적용 시, beam search를 이용해 각 시퀀스마다 확률이 가장 높은 개의 후보 단어들을 샘플링 하여, 이들을 통해 보상 평균을 계산해서 안정적이게 업데이트 하도록 한다. 보상으로는 CIDEr-D score를 사용한다.
최종적으로 한 샘플에 대한 gradient는 다음과 같이 계산된다.
