Multi-modal
1.CLIP : Learning Transferable Visual Models From Natural Language Supervision

CLIP 이전에 제안된 computer vision 기술들은 사전에 정의된 클래스만 예측할 수 있도록 훈련을 진행한다. 이러한 제한된 형식은 추가 레이블에 대해서는 추론이 불가능하므로 유용성이 떨어진다고 볼 수 있다.하지만 만약 이미지를 나타내는 텍스트를 통해 모델을
2025년 7월 7일
2.Meshed-Memory Transformer for Image Captioning
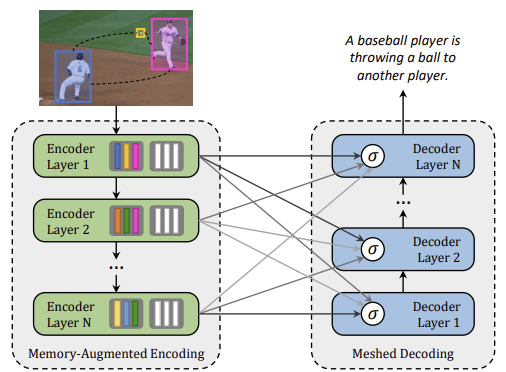
Transformer 기반의 구조는 번역과 같은 시퀀스 모델에서 최고의 성능을 보여줬지만, image captiong과 같은 multi-modal task에서는 아직 충분한 연구가 수행되지 않았다.본 논문은 image captioning task를 수행하기 위한 Mes
2025년 9월 20일