이전까지 제안된 방식들은 객체 인식 task를 해결하기 위해 non-maximal suppression (NMS) 나 spatial anchors 와 같은 사전 지식을 모델에 인코딩해야 했다. 본 논문은 이러한 사전 지식이나 특별한 라이브러리 없이 Transformer 모델을 이용하여 모든 객체들을 한 번에 예측하는 end-to-end 방법을 제안한다.
DETR architecture
DETR의 모델 구조는 아래 그림처럼 정말 간단하다.
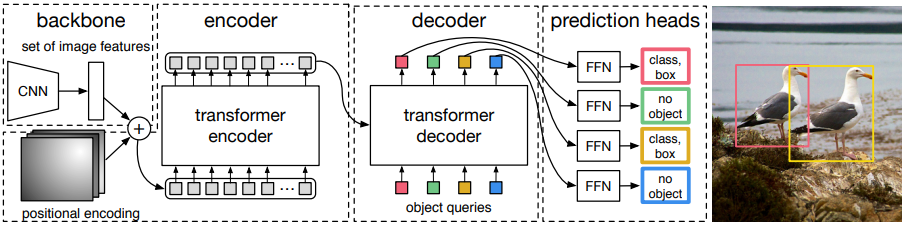
1. Backbone
우선 입력 이미지에 대해 CNN으로 구성된 backbone network 를 통해 더 낮은 해상도의 feature map을 획득한다. 여기서 backbone으로 ResNet을 사용한다. 이미지의 차원이 이라면 backbone network를 통과하여 인 activation map을 얻도록 설정한다.
2. Encoder & Decoder
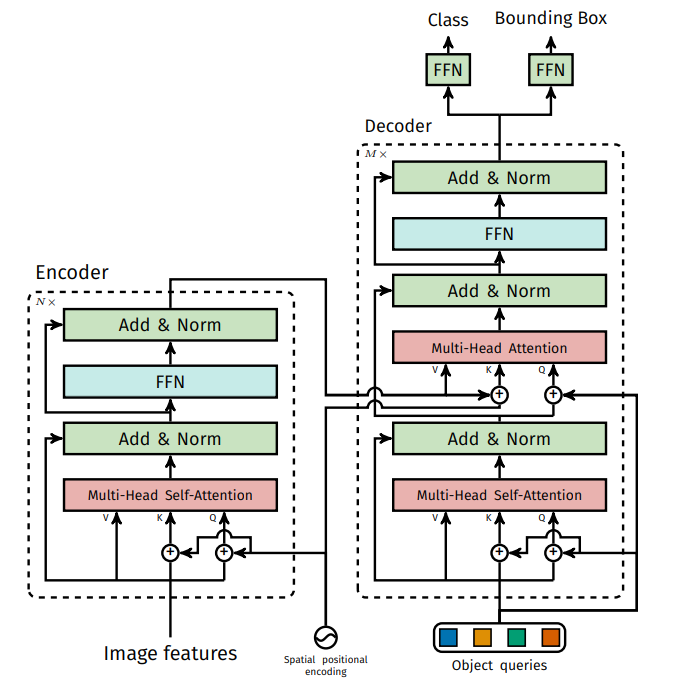
2.1. Encoder
Backbone network를 통과해서 얻은 activation map은 컨볼루션을 통해 채널의 차원 수를 줄여 새로운 activation map으로 만든다. Transformer의 encoder는 1차원의 고정된 사이즈의 벡터를 입력으로 받으므로 이 activation map을 flatten하여 위치 정보와 함께 입력으로 넣어주게 된다. Encoder의 구조는 ViT에서 소개했듯이 normalization layer, Multi-head self-attention layer, 그리고 feed-forward neural network layer로 구성되어 있다.
2.2. Decoder
Decoder의 입력으로는 객체 class 수보다 많은 N 개의 object query가 들어간다. Encoder의 입력과 마찬가지로 1차원의 고정된 사이즈의 벡터 N 개를 입력하게 되면 self-attention, 그리고 encoder의 출력과 decoder의 입력 간의 cross-attention을 수행하여 모델이 모든 객체들 간의 전체적인 관계를 알 수 있고, 이미지 전체를 사용할 수 있게 된다.
3. Prediction feed-forward networks (FFNs)
모델의 최종 출력은 MLP로 구성된 FFN을 통해 이뤄진다. 첫 번째 FFN은 입력 이미지에 대해 예측된 bounding box의 중점 과 너비, 그리고 폭을 예측하고, 두 번째 FFN은 softmax 함수를 통해 객체의 레이블을 출력한다. 그 어떤 객체도 인식되지 않았을 때를 위해 class를 추가한다.
4. Loss function
DETR은 auxiliary loss를 사용하여 모델의 파라미터를 최적화한다. Transformer의 decoder layer는 보통 6개로 구성되어 있다. 이렇게 deep한 구조는 학습이 어려울 수 있으므로, 각 decoder에서 출력한 값들에 대한 loss를 모두 계산하여 학습할 수 있도록 한다. 즉, 각 decoder layer에서 FFN이 class와 bounding box를 예측하면서 parameter를 공유한다.
4.1. Object detection set prediction loss
정답들로 구성된 집합을 , N 개의 예측으로 구성된 집합을 이라 하면, 두 집합 사이의 bipartite matching을 찾기 위해 N 개의 순열을 탐색한다.
최적의 match를 찾기 위해 본 논문은 Hungarian algorithm을 통해 효율적으로 계산한다.
4.2. Hungarian loss
Hungarian algorithm을 통해 얻은 최적의 match를 이용하여 loss 값을 계산하게 되는데, 수식은 아래와 같다.
4.2.1. Classification loss
여기서 는 정답 클래스, 는 예측된 클래스의 확률값이다. 여기서 정답 클래스의 확률을 1, 즉 100%로 예측하면 이므로 loss 값은 0이 되고, 정답 클래스의 확률을 0.01, 즉 1%로 예측하면 이 된다. 이렇게 되면 잘못된 예측해 대한 loss 값이 정답에 대한 loss 값보다 작아지므로 를 붙여주는 것이다.
4.2.2. Bounding box loss
Bounding box loss는 L1 loss 와 generalized IoU (GIoU) loss를 선형결합한 loss를 사용한다.
- L1 loss
L1 loss는 정답 bounding box의 꼭짓점 좌표 4개와 예측된 bounding box의 꼭짓점 좌표 4개의 차이를 계산하는 것이고, GIoU는 기존의 IoU에서 유용한 gradient를 제공하기 위해 사용된 것이다.
- GIoU (Generalized Intersection of Union)
IoU는 정답 bounding box와 예측된 bounding box가 얼마냐 겹쳐있는지를 나타내는 metric이다.
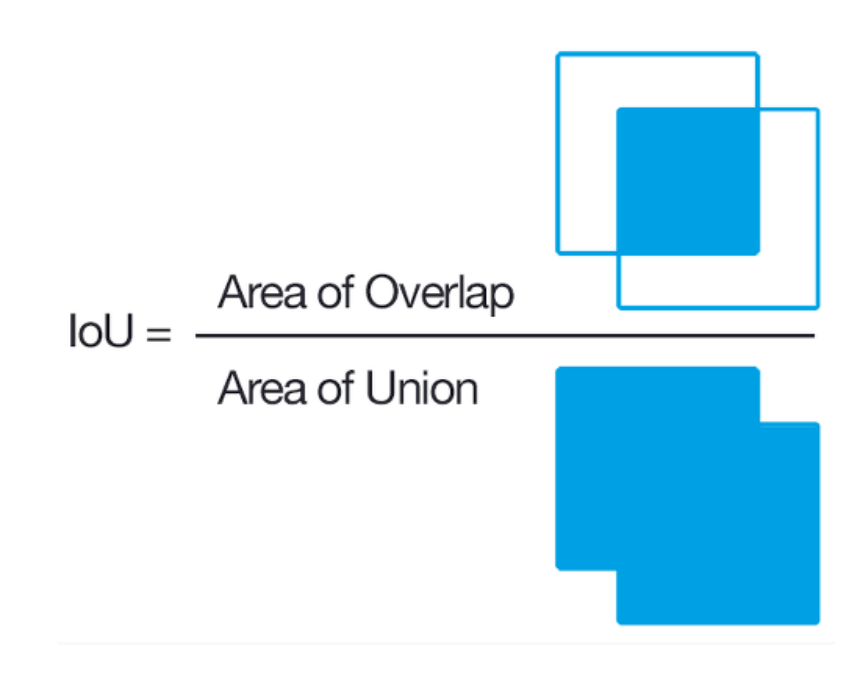
겹치는 부분이 클수록 IOU 값은 커질 것이고, 반대로 겹치는 부분이 작아질수록 IOU 값은 작아질 것이다. IOU의 최댓값은 1, 최솟값은 0이다.
GIOU는 기존의 IOU가 겹치지 않는 영역을 0으로 loss 값을 계산하는 것이 학습 과정에서 유용한 gradient를 제공하지 않는다고 판단하여, 겹치는 영역이 없는 경우에도 차이를 반영할 수 있도록 확장한 개념이다.(C는 두 bounding box A, B를 포함하는 최소한의 bounding box)
앞에 있는 는 정답 class와 일치하는 class에 대해서만 진행한다는 뜻이다. 즉, 정답 class와 일치한다면 해당 GIoU 값을 이용하고, 일치하지 않는다면 0을 곱하여 해당 GIoU 값을 무력화시킨다.
이 loss function을 이용해서 각 decoder layer에서 예측한 class와 bounding box를 정답 class와 bounding box와 비교하여 각 layer에서 얻은 loss 값을 모두 이용하여 모델의 parameter를 최적화하게 된다.

정말 유용한 글이에요!