최근에 아산병원에서 MRI 이미지를 이용하여 간암을 분할하는 task를 수행하게 되어 segmentation 논문들을 읽고있다. 오늘은 그 중 한 획을 그엇던 U-Net에 대해 리뷰해볼까 한다.
1. Introduction
U-Net은 이전에 제안됐던 FCN (Fully Convolutional Network) 네트워크 구조를 수정하고 확장한 모델이다. 그 결과 FCN 모델보다 더 적은 데이터로 학습해도 더 정확한 결과를 산출할 수 있었다고 한다.

U-Net이 제안한 method는 총 세 가지이다.
- FCN은 downsampling에서만 feature channel 수를 늘렸다면, U-Net은 upsampling에서도 feature channel의 수를 확대하여 네트워크가 네트워크가 더 높은 해상도를 가진 layer에 위치 정보를 전달할 수 있게 하였다.
- 적은 수의 훈련 데이터가 주어져도, data augmentation 기법을 통해 모델이 좋은 결과를 낼 수 있도록 하였다.
- Weighted loss 라는 새로운 loss term을 통해 객체를 분할할 때, 맞닿는 두 개의 object의 경계선이 더 잘 표현될 수 있도록 하였다.
2. Network
U-Net의 네트워크 구조는 다음과 같다.
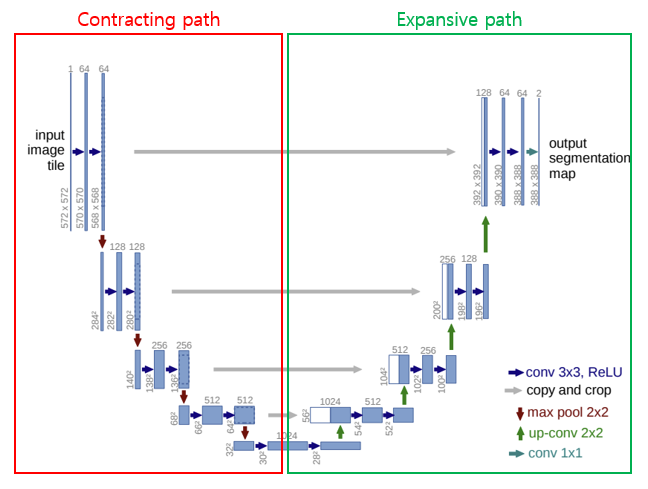
Contracting path는 이미지의 해상도를 줄이면서 feature channel의 수를 늘려가고, Expansive path는 이미지의 해상도를 늘려가며 feature channel의 수를 줄여가는 방식으로 진행된다.
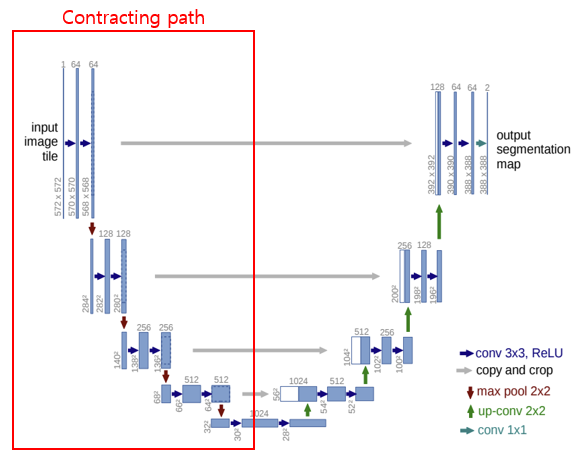
2.1. Contracting path
Contracting path는 각 layer마다 두 번의 convolution 연산과 ReLU 함수를 통해 비선형성을 추가한다. 그 후 max pooling을 통해 이미지의 해상도를 줄이게 된다. 각 downsampling마다 feature channel의 수는 2배가 된다.
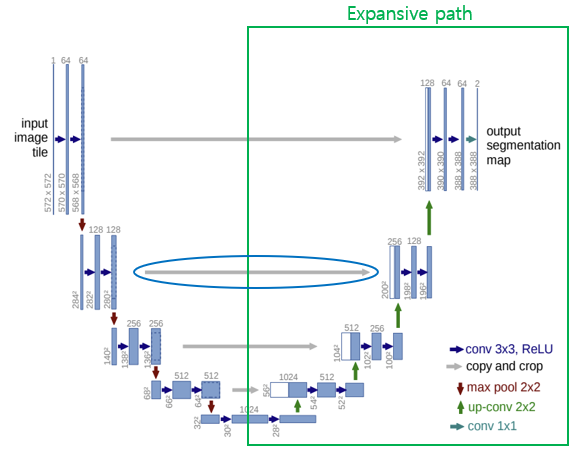
2.2. Expanding path
Expanding path에서는 up-convolution을 통해 upsampling을 진행한 후, 마찬가지로 두 번의 convolution 연산과 ReLU 함수를 통해 비선형성을 추가한다. 각 upsampling마다 feature channel의 수는 배가 된다.
하나의 특이한 구조는 아래 그림의 파란색 타원으로 표시된 부분을 보면, upsampling된 feature map과 contracting path에서 대응되는 feature map을 concatenate한다는 것이다. Feature map을 concatenate하는 이유는 downsampling 시 feature map의 크기가 작아져 위치 정보가 손실되고, upsampling 시 해상도가 올라가지만 원래의 세밀한 정보를 복원하지 못한다. 그래서 skip connection을 통해 global한 정보와 local한 정보를 합치는 것이라 보면 되겠다.
최종 output은 class 수만큼의 1x1 convolution filter와의 연산을 통해 segmentation map을 출력하게 된다.
3. Training
훈련 이미지를 통해 학습하기 위해, 저자는 입력 patch의 사이즈를 키우고 batch 사이즈를 줄여 overhead를 최소화 하고 GPU 메모리 사용을 최대화하였다.
또한, 높은 momentum 값을 설정하여 모델이 바로 전에 본 훈련 이미지를 통해 optimization step를 업데이트할 수 있도록 하였다.
마지막으로, weighted loss를 적용하여 더 나은 segmentation map을 출력할 수 있도록 하였다.
수식을 뜯어보면, 우선 는 각 픽셀의 위치를 나타내고, 는 해당 픽셀의 정답 클래스를 나타낸다.
는 softmax 함수로,
는 픽셀 위치 에서 번째 class의 activation 값이고, 는 모든 class의 activation 값으로 나누어 각 class에 대해 해당 픽셀이 어떤 class에 대응하는지 예측한 확률값을 나타내게 된다. 결국 는 정답 class에 대해 어느정도의 확률을 예측했는지 구한 꼴이 된다.
는 class 간의 균형을 위해 사전에 계산된 weight map이고, 수식은 다음과 같다.
위 수식에서 는 해당 픽셀의 중요도에 따라 사전에 계산해둔 weight 값이고, , 는 해당 픽셀과 제일 가까운 두 객체까지의 최단 거리이다. 이므로 만약 거리가 적으면 경계를 나누는데 중요한 픽셀이므로 가중치를 더 주고, 멀면 값이 작아져서 경계를 나누는데에 중요하지 않다 판단하게 된다.
3.1. Data augmentation
Data augmentation 기법은 학습에 사용할 훈련 데이터의 수가 적을 경우, 데이터의 약간의 변화를 주어 새로운 데이터를 만들어 훈련 데이터의 수를 늘리는데 사용한다. 저자는 탄성 변형 (elastic deformation)을 적용하여 데이터를 증강하였다. 탄성 변형의 예시는 아래 그림을 보면 이해가 될 것이다.


이해가 쏙쏙 잘되네요