nnU-Net : Self-adapting Framework for U-Net-Based Medical Image Segmentation
Computer Vision
1. Introduction
CNN 기반의 segmentation 기법은 좋은 성능을 내기 위한 특수한 네트워크 구조 및 다양한 훈련 기법을 요구한다. 하지만 이러한 요소 없이 다른 종류의 다양한 데이터셋에 대해 일반적인 결과를 산출할 수 있는 알고리즘이 필요하다. U-Net은 네트워크 구조를 조금씩 수정하여 특정 문제에 과적합하도록 한다. 하지만 본 논문은 네트워크 구조 외에 다른 방면에서 더 영향력이 있다고 제안한다. nnU-Net 또한 'No New U-Net'의 줄임말로, 이전의 U-Net과 모델 구조에 대해서는 다른게 없다고 말하고 있는 것을 알 수 있다.
2. Methods
2.1. Network architectures
위에서 말했듯, 네트워크 구조 외의 다른 면에 초점을 맞추므로 네트워크는 U-Net과 크게 다르지 않다. 다른 점이 있다면 U-Net에서 활성화 함수로 ReLU 함수를 사용했다면 nnU-Net은 Leaky ReLU 를 사용하여 weight가 음수의 값을 갖는 부분에서도 어느정도 살렸고, U-Net에서 batch normalization을 사용했다면 nnU-Net은 instance normalization을 사용하여, batch 단위가 아닌 이미지 단위로 normalize를 하여 각 이미지 고유 정보를 잃는 것을 방지하였다.
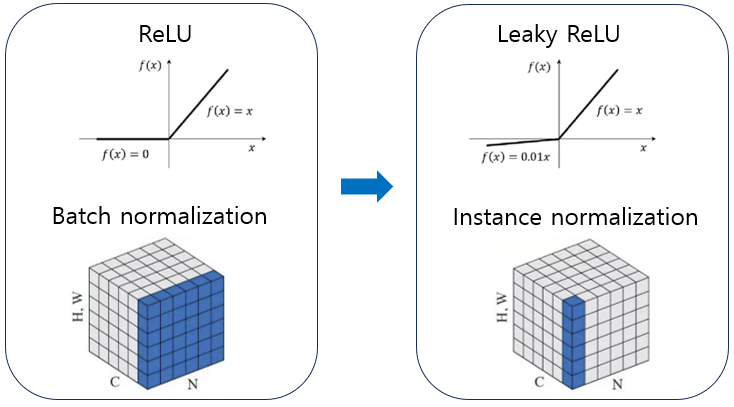
MRI, CT와 같은 이미지들은 3차원으로 구성되어 있는데, 각 slice로 저장된 2차원 이미지 여러장을 합친 꼴과 같다. 이러한 측면에서 instance normalization을 통해 각 이미지 고유 정보를 가져가는 것이 어쩌면 medical image segmentation에 더 적합하다고 생각된다.
2D U-Net
2D U-Net의 경우 z축에 대한 중요한 정보를 고려하지 않을 수 있으므로 3차원인 medical image를 segmentation하기에는 적합하지 않지만, 데이터셋이 anisotropic하다면 충분히 사용할 가치가 있다.
3D U-Net
3D U-Net이야말로 medical image segmentation에 적합한 모델이지만, GPU 메모리의 한계로 인해 이미지를 패치 단위로 나누어 모델에 입력하게 된다. 이는 큰 이미지의 경우 Field of View의 한계로 모든 context 정보를 못 모을 수 있다.
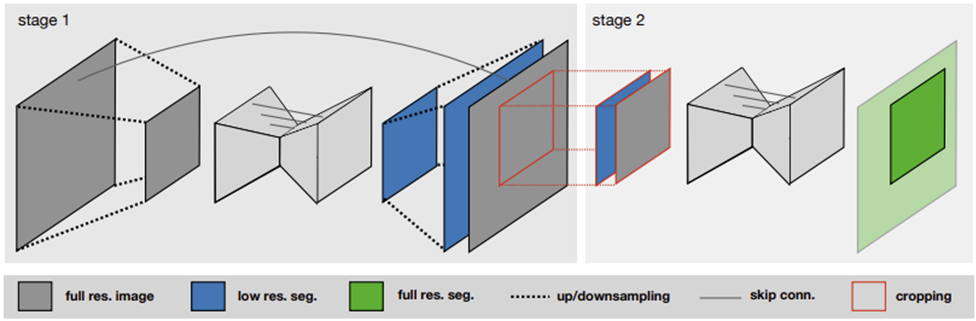
U-Net cascade
이 모델은 이러한 3D U-Net의 단점을 보완하기 위해 제안되었다. U-Net을 통과해서 얻은 segmentation map을 ground-truth segmentation map에 one-hot encoding 형태로 두 번째 U-Net에 통과시켜 최종 output을 얻어낸다.
Dynamic adaption
GPU를 최대한 활용하여 모델이 입력 이미지의 공간 정보를 충분히 담아내기 위해 입력 patch의 크기, 층 별 pooling 횟수를 잘 설정해야 한다. 또한 네트워크의 수용능력에 따라 batch size 조절이 필요하다. 본 논문은 이러한 hyperparameter를 자동적으로 결정될 수 있도록 한다.

3D U-Net의 경우 입력 이미지가 지정된 patch size보다 작다면, 입력 이미지의 median shape로 patch size를 줄이고, 최종 처리되는 voxel의 수가 기존의 patch size와 batch size로 진행했을 때와 같도록 batch size를 늘리게 된다.
2.2. Preprocessing
다음은 모델에 데이터를 입력하기 전에 진행하는 전처리 과정에 대해 설명한다.
Cropping
모든 입력 데이터셋에 대해 픽셀 값이 0이 아닌 영역을 crop한 후 진행한다.
Resampling
모든 입력 데이터셋에 median voxel spacing을 통한 resampling을 진행하여 네트워크가 공간 정보를 학습할 수 있도록 설정한다. Resampling 과정을 통해 생기는 빈 voxel 값은 interpolation을 통해 채우게 된다.
Normalization
정규화 기법으로는 Z-score normalization을 사용하여, 모든 voxel의 intensity 값의 평균과 표준편차를 기반으로 데이터를 정규화한다.
2.3. Training procedure
Loss function
Loss function은 U-Net에서 소개된 cross entropy loss와 함께 dice loss를 합쳐 학습하게 된다.
여기서 는 총 클래스의 수, 는 총 픽셀 수, 는 softmax output, 는 ground-truth segmentation map에 softmax output을 기반으로 one-hot encoding을 적용한 값이다.
Cross entropy의 경우 각 픽셀마다 weight를 주면서 픽셀 단위의 분류를 돕고, dice loss의 경우 두 segmentation map의 겹치는 정도를 전체적인 segmentation의 품질을 올리게 된다.
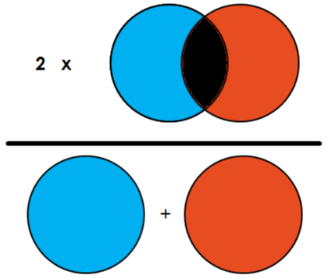
Dice loss의 경우 예측된 segmentation map과 ground truth segmentation map의 겹쳐지는 정도를 계산하고, dice score가 클수록 예측을 잘 했다고 할 수 있다. 하지만 loss function의 경우 loss 값을 최소화하는 방향으로 학습해야 하므로, dice score는 1에 가까워지도록, dice loss는 를 통해 0게 가까워지도록 만든다.
Data augmentation
Data augmentation은 rotation, scaling, elastic deformation, gamma correction, mirroring 등의 기법을 사용했고, 훈련 도중에 실시간으로 적용된다.
U-Net cascade의 경우 강한 상호작용을 방지하기 위해 2번째 stage 전에 무작위로 연결 요소를 제거한다. 이는 같은 클래스로 분류된 픽셀 덩어리에서 일부러 연결 요소를 제거하여 훈련 데이터의 다양성을 증가하는 것이다.
2.4. Inference
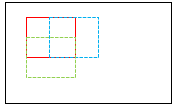
각 patch에 대한 output 값에 대해, 경계 영역이 네트워크의 정확도를 떨어뜨리는 경향을 고려해서 경계에 가까운 영역보다 중앙에 가까운 영역에 가중치를 더 높게 준다. 또한 patch는 이전 패치의 절반 영역이 겹치도록 하여 다음 patch를 설정한다. 이렇게 함으로서 이전 patch에서 경계 영역에 있던 픽셀이 다음 patch에서 중앙 영역에 오게 되면서 모든 픽셀이 모델 학습에 고려되도록 한다.
또한 5-fold cross validation 기법을 통해 얻은 5개의 네트워크를 앙상블하여 test case에 적용한다.
2.5. Postprocessing
학습 데이터에서 각 클래스가 몇 개의 연결성분으로 나타나는지 분석하여, 특정 클래스가 1개로 나타나면 (ex : 간 1개), 그것을 일반적인 성질로 간주한다. 만약 예측 결과 해당 클래스가 여러 개의 클래스로 분할되면, 가장 큰 연결 성분을 띄는 클래스를 제외하고 나머지 연결 성분을 지워 학습한다.
2.6. Ensembling
2D U-Net, 3D U-Net, U-Net cascade 모든 네트워크 중 2개를 조합해보면서 성능을 끌어올리고, 가장 좋은 결과를 내는 모델을 최종 모델로 선정한다.
3. Results
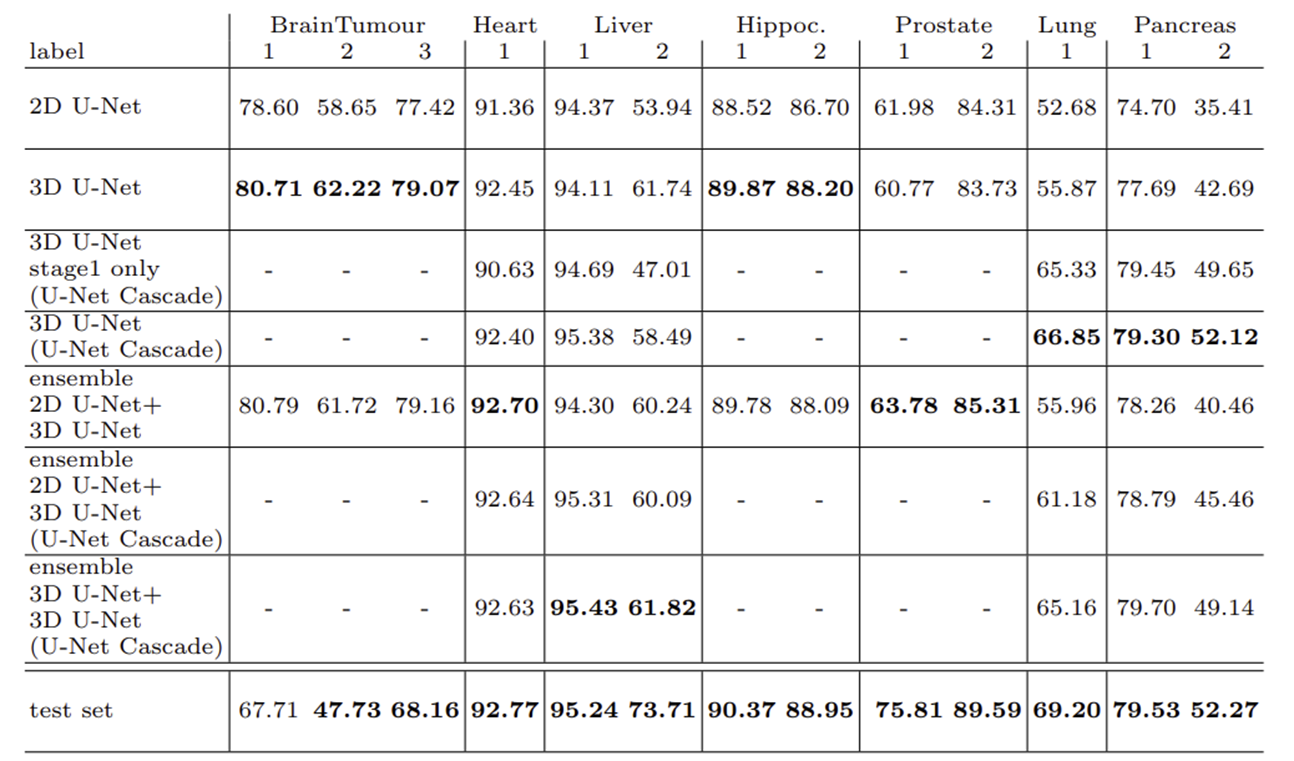
해당 대회 test step에서 보여진 각 문제에 대한 3개의 데이터셋에 대해, BrainTumour를 제외한 나머지 문제에서 최고의 점수를 보이는 것을 알 수 있다.

정말 신기하네요