
📣 개인적인 생각이 가득한 글입니당.
서비스(프로그램)는 데이터를 생성(C), 조회(R), 변경(U), 삭제(D)하면서 사용자에게 특정한 경험을 제공한다. 우리가 IT서비스라고 부르는 것들을 단순하게 정의하자면 데이터를 처리하는 고유한 로직과 그로 인해 생성된 데이터의 집합체라 할 수 있지 않을까?
서비스 내에서 웹 프론트엔드의 역할은 인간(사용자)과 기계(서버) 사이에서 오고가는 데이터의 형태를 각자가 이해할 수 있는 형태로 가공해주는 파이프라인이다. 사용자와 서버를 이어주는 통역사라고 볼 수 있다.
서비스를 구성하는 데이터는 서버에서 사용자까지 이동하면서(혹은 그 반대) 데이터를 소비하는 주체에 따라 그 모습을 달리한다. 여기서 말하는 주체는 사용자부터 프론트엔드/백엔드의 비즈니스 로직, 데이터베이스, 더 나아가서는 저장장치까지 생각할 수 있다.
velog의 추천 포스트를 예시로 좀 더 자세히 알아보자.
⚠ 데이터가 오간다고 표현했지만, 실제 데이터의 CRUD는 모두 서버에서 이루어진다. 클라이언트에서 다루는 데이터는 서버 DB에 존재하는 실제 영속 데이터의 그림자일 뿐 엄밀히 말해서 실제 DB에 저장된 데이터 그 자체가 아니다. 다만 편의를 위해 이 글에서 이 점은 논외로 한다!
기계를 위한 형태

이게 뭐야.. 넘어가자..
비즈니스 로직을 위한 형태
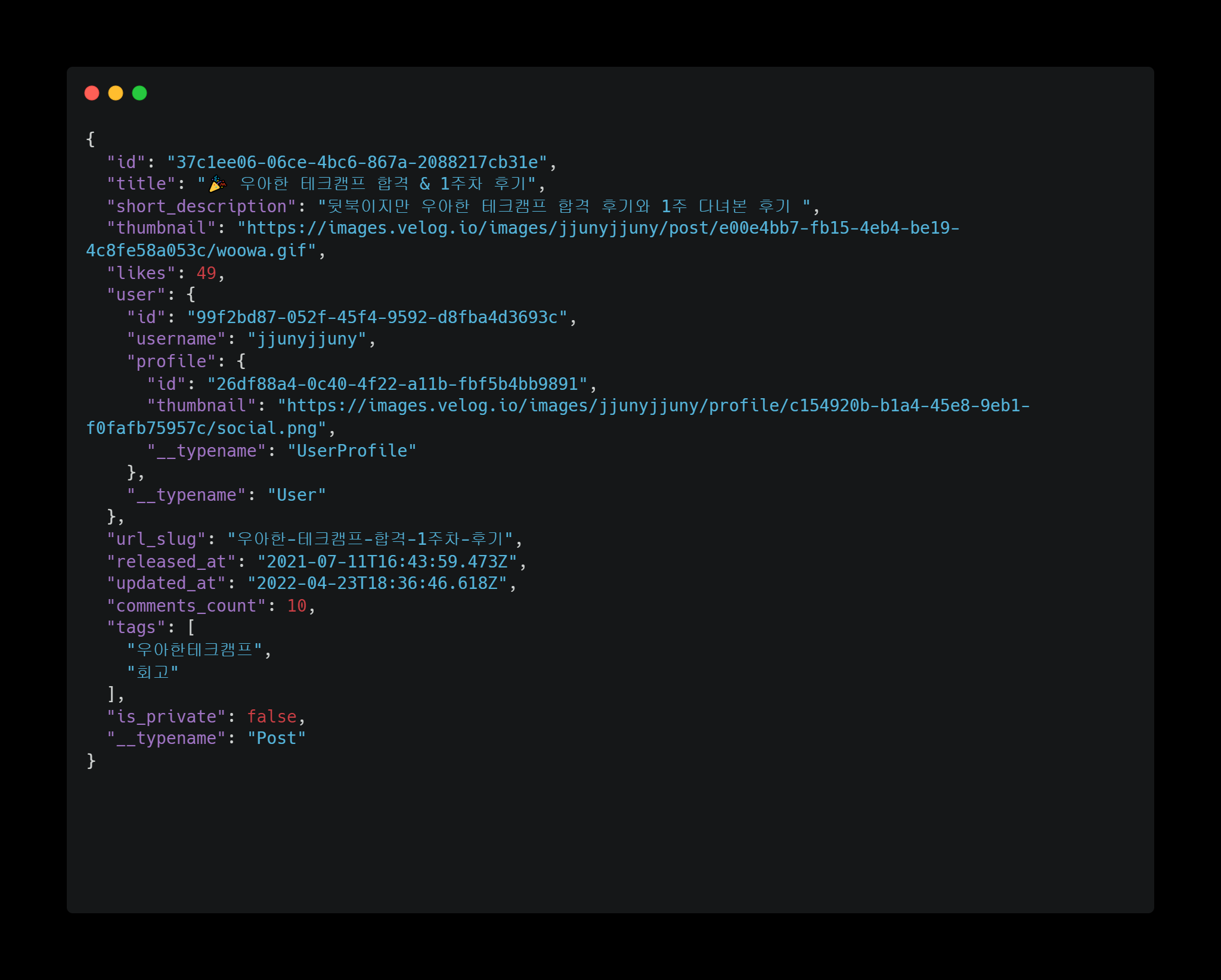
또는 개발자를 위한 형태
실제 velog 서버에서 브라우저에 내려준 추천 포스트 데이터의 JSON 형태 응답값이다. 한눈에 알아보긴 힘들지만 자세히 살펴보면 제목과 설명, 좋아요 수 등에 대한 정보가 담겨있다는 것을 알 수 있다. 우리가 비즈니스 코드를 작성하기 위해서는 이러한 형태의 데이터가 필요하고, 우리의 코드도 이 형태의 데이터를 사용한다.
인간(사용자)을 위한 형태
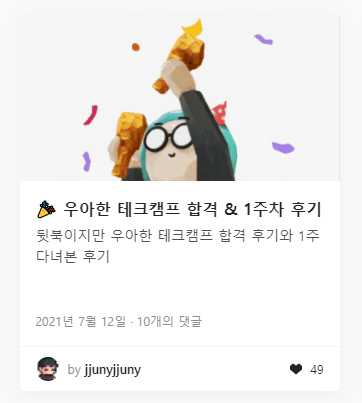
이 추천 포스트 카드 UI를 보았을 때, 사용자는
- 썸네일 이미지가 있다.
- 굵은 글씨가 아마도 이 글의 제목이다.
- 그 아래는 글씨는 서브 타이틀이거나 간략한 설명이다.
- 작성자는 누구고
- 그 외에 작성 일자, 댓글 수, 좋아요 수..
이러한 정보를 꽤나 직관적으로 파악할 수 있다. 왜냐하면 이 UI는 각 정보의 위계(설명보다 제목이 더 중요하다), 인간의 인지능력(보통 위에서 아래로, 좌에서 우로 시선이 흐르며 뭉쳐있는 것들끼리 연관짓는)등을 고려해 디자인되었기 때문이다.
추천 포스트 데이터는 저장장치에서 사용자에게 보여지기 까지 이 외에도 다양한 단계를 거치고, 그 때 마다 적절한 형태를 취할 것이다. 비록 형태는 다를지라도 본질적으로 가지고 있는 정보는 같다. 우리의 역할은 데이터의 흐름속에서 필요한 순간에 적절한 형태로 데이터를 가공하는 것이다.
물론 서버 => 사용자 방향 뿐아니라 그 반대로 마찬가지다. 사용자의 행동을 기계가 이해할 수 있는 형태로 가공해서 서버에 전송하는 것도 프론트엔드의 역할이다.
