
프론트엔드라는 개념이 자리잡기 전, 과거 브라우저는 서버에서 HTML/CSS 파일을 내려주면 이를 그대로 렌더링 하고, JavaScript 스크립트를 부착한 간단한 웹사이트를 띄워주는 역할만 수행했다.
하지만 프론트엔드/백엔드의 업무가 구분되었고, 프론트엔드는 UI를 렌더링하기 위해 필요한 데이터를 받아서 이 데이터를 기반으로 클라이언트에서 직접 UI를 렌더링하는 CSR(Client Side Rendering)이 대세가 되었다. (물론 SSR와 병행하는 next가 대세가 된 거 같기도..)
데이터 가공.. 누가할래..?

이전에 작성한 [짧은 생각] 같은 데이터, 다른 모습에서도 언급했던 것처럼, 데이터는 그것을 소비하는 주체에 따라 모습을 달리해야한다. 여기서 한 가지 문제점이 생기는데, 일반적으로 서버에서 내려주는 데이터의 형태와 UI를 렌더링하기 위한 최적의 데이터의 형태가 😱 항상 일치하지는 않는다는 점이다.
따라서 데이터를 UI에 맞게 한 번 가공할 필요가 있는데, 프론트에서 가공해서 쓰면 더 유연하잖아 vs 서버에서 가공해서 주면 더 안전하고 좋잖아 처럼 서버와 프론트의 의견이 나뉠 수 있다.
🔥🔥 그래서, 이 데이터 가공은 누가 할 것인가? 가 이 글의 주제이다.
결론부터 이야기하면, 서비스의 규모가 커질수록 프론트엔드의 몫이라고 생각한다. [짧은 생각] 같은 데이터, 다른 모습에서 사용했던 velog의
추천 포스트를 예시로 이야기를 풀어가보자
// react
function RecommendedPostList() {
const [postList, setPostList] = useState([])
useEffect(() => {
async function fetchPost() {
const res = await API.getRecommendedPostList()
setPostList(res.data.post.recommended_posts)
}
fetchPost()
}, [])
return (
<Wrapper>
{postList.length === 0
?
<div>텅텅</div>
))
:
postList.map((post) => (
<RecommendedPost post={post} />
}
</Wrapper>
)
}
function RecommendedPost({ post }) {
const { thumbnail, title, short_description, released_at, comments_count, user, likes } = post
return (
<Wrapper>
<Thumbnail src={thumbnail} />
<Title>{title}</Title>
<Description>{short_description}</Description>
<CreatedDate>{formatDate(released_at)}</CreatedDate>
<CommentsCount>{comments_count}</CommentsCount>
<Writer writer={user} />
<Like>{likes}</Like>
</Wrapper>
)
}
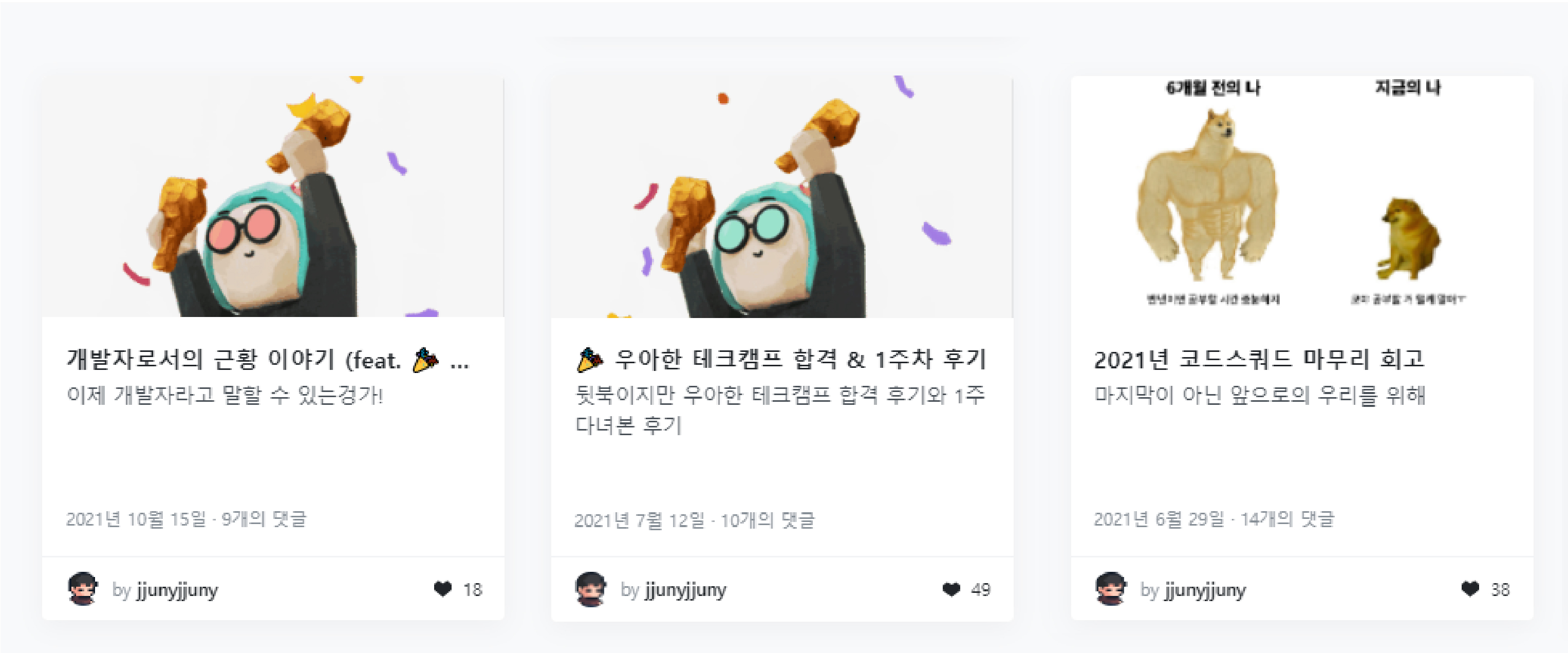
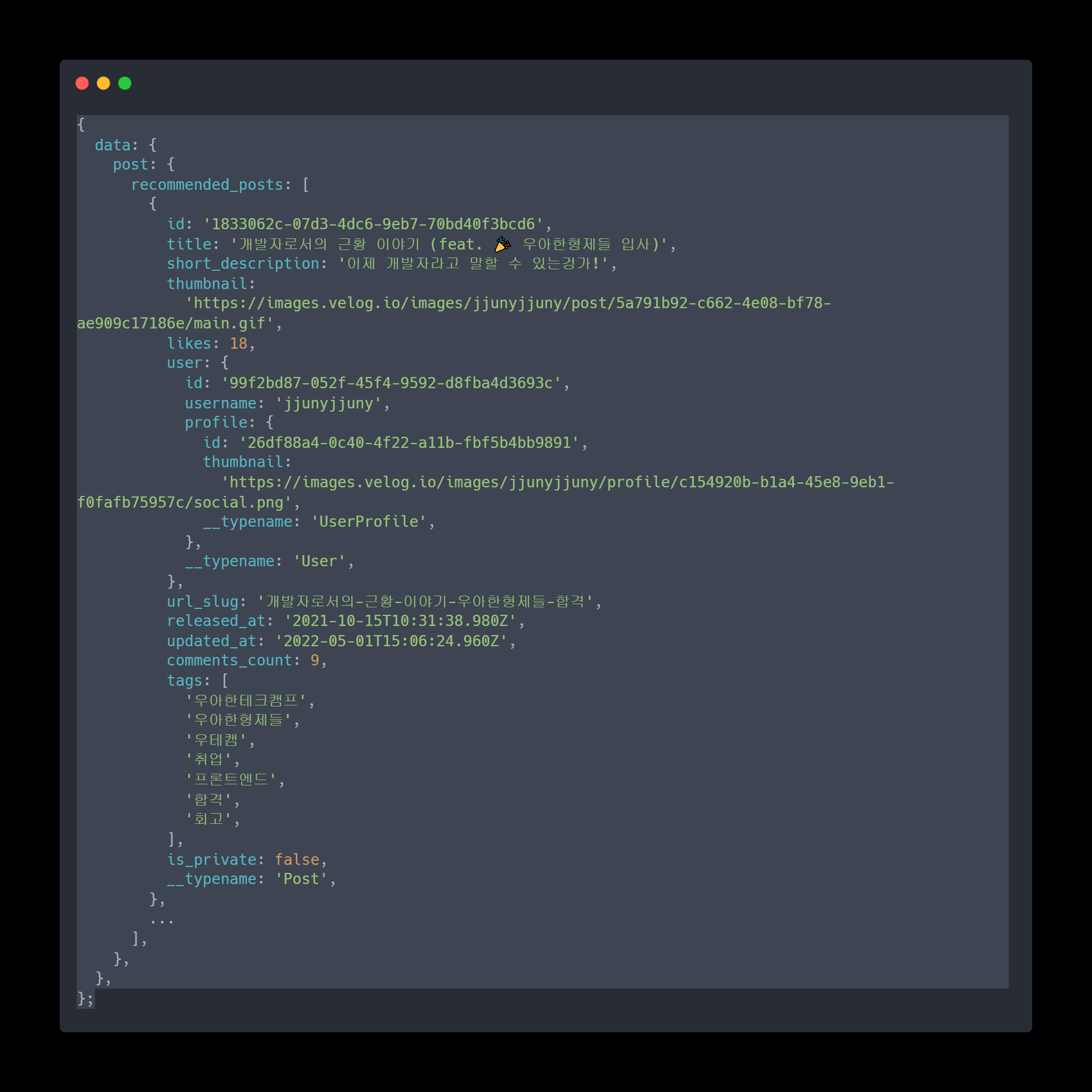
추천 포스트 리스트 API의 응답값 / 응답값을 기반으로 UI를 렌더링하는 React code(구체적인 마크업/스타일링은 생략한다) / 그리고 그 결과 UI다.
이 세가지를 비교해보았을 때 몇 가지 문제점이 보인다.
- 응답값에 불필요한 필드가 있다.
updated_at,tags,url_slug등..- 물론 실제 비즈니스 로직을 본 건 아니라서 사용될지 모르겠지만, 슬쩍봐선 불필요하다.
- 백과 프론트의 변수 명명법이 다르다
- 필드명이 스네이크_케이스로 내려왔지만, 프론트엔드는 주로 파스칼/카멜케이스를 사용한다.
- 같은 데이터도 달리 표현할 수 있다
user/writerreleased_at/createdDate
- 바로 쓰일 수 없는 값이 있다
released_at은 UTC 표기법으로 되어 있는데,yyyy년 mm월 dd일의 형태로 변환해주어야한다.
- 기존 데이터를 기반으로 연산한 새로운 데이터가 필요할 수 있다.
- 혹시나
recommended_posts가 비어있을 때 다른 UI를 표시하려면recommended_posts.length === 0와 같은 로직이 추가되어야 한다.isEmpty같은boolean값이 있다면 더 깔끔해질 것이다. title과short_description을 합쳐야한다거나,likes와comments_count의 비율을 보여준다거나 하는 기획이 추가된다면, 그 연산 결과가 필요하다.
- 혹시나
1번 문제의 경우 사용하지 않으면 그만이지만, 나머지 2~4의 경우 추가적인 가공 로직이 필요하다. 그리고 보통 이 추가적인 가공 로직을 컴포넌트 내부에서 작성하곤 한다. 따라서
- 컴포넌트의 관심사에 맞지 않는 불필요한 비즈니스 로직이 생기며
- 유지보수가 어려운 코드가 된다
왜 이런 일이 발생하는걸까?
프론트엔드 입장에서는 처음부터 이상적인 데이터를 내려주면 안 되나 싶을 수 있다. 아마 백엔드 개발자와 함께 작은 사이드 프로젝트를 진행해봤다면 이 응답값은 이러저러하게 바꿔서 내려주실 수 있나요?와 같은 요청을 해본 경험이 있을 것이다. 그리고 착한 백엔드 개발자분들은 웬만하면 받아들여주셨을 것이다.. ( 감사합니다..👍 )
이게 가능한 이유는 서비스가 작을수록 서버와 클라이언트가 1:1 관계를 가지기 때문이다. 해당 API를 호출하는 클라이언트가 나뿐이라서, 더 나아가서 그 페이지 뿐이라서 서버가 클라이언트에 맞춤형 응답을 내려준다해도 큰 문제가 없음을 의미한다. 이 경우 어느쪽이든 보통 좀 더 여유가 있는 사람이 가공작업을 맡아도 프로젝트에 무리가 없다.
하지만 프로젝트가 점차 커지면 얘기가 달라진다.
프로젝트가 커지면 서버는 도메인 단위로 코드를 관리해야할 필요성이 생긴다.
velog의 서비스 규모가 지금보다 더 커지고 다양해졌다고 가정해본다면, post 도메인 전담팀이 신설되어 관리될 것이다. 메인화면, 글쓰기에디터, 유저소통공간(가상) 등 여러 도메인에서 post와 관련된 여러 요청을 보낼 것이기 때문에 서버는 어느 한 도메인에 맞추지 않고 어떤 요청에도 유연하게 대응할 수 있는 구조를 갖추어야한다.
클라이언트의 모든 사소한 차이에 대응하는 API를 만들어 두는 것은 리소스 낭비고, 유지보수도 힘들어진다. 데이터를 좀 더 순수하게(?) 다룰 필요가 있다.
또한, 해당 데이터가 클라이언트에서 어떻게 렌더링 될 것인가는 서버의 관심사가 아니다. 서버는 데이터의 CRUD 관점에서 요청과 데이터를 처리하는 것에 집중한다.
⚠ 백엔드에 대한 깊은 지식을 기반으로 작성한 내용은 아니기 때문에 틀린 내용이 있을 수 있습니다. 지적바랍니다!
따라서 프론트엔드 입장에서, 해당 API를 여러 페이지에서 호출하는 경우 페이지마다 디자인/기획에 따라 미묘하게 필요한 데이터가 달라질 수 있다. 페이지를 만들다보면 어떤 추가적인 가공이 필요할지 모르기 때문에 그 때마다 서버에 요청하기보다 스스로 컨트롤 할 수 있는게 좋다.
그래서, 이 문제를 어떻게 해결하나!

이러한 문제점을 보완하기 위해 REST API 대신 GraphQL을 사용하기도 하지만, 이 글에서는 REST API의 응답값을 Class Instance로 변환해서 사용하는 방식과 , decode/encode 함수를 사용하는 방식을 소개하고자한다.
Class Instance로 변환하는 방식
// typescript로 작성되었습니다.
export class RecommendedPostList {
public get PostList(): RecommendedPost[] {
return this.postList
}
public get isEmpty(): boolean {
return postList.length === 0
}
constructor(init: RecommendedPostListResponse){
this.postList = init.data.post.recommended_posts.map(post => new RecommendedPost(post))
}
private readonly postList: RecommendedPost[]
}
export class RecommendedPost {
public get Id(): string {
return this.id
}
public get Title(): string {
return this.title
}
public get Description(): string {
return this.description
}
public get ThumbnailURL(): string {
return this.thumbnailURL
}
public get LikeCount(): number {
return this.likeCount
}
public get Writer(): Writer {
return this.writer
}
public get CreatedAt(): string {
return format(this.createdAt) // format된 값을 내려준다
}
public get CommentCount(): number {
return this.commentCount
}
constructor(init: RecommendedPostResponse) {
this.id = init.id
this.title = init.title
this.description = init.short_description
this.thumbnailURL = init.thumbnail
this.likeCount = init.likes
this.writer = new Writer(init.user) // Writer라는 class도 따로 만들었다고 가정
this.createdAt = init.released_at
this.commentCount = init.comments_count
}
private readonly id: string
private readonly title: string
private readonly description: string
private readonly thumbnailURL: string
private readonly likeCount: number
private readonly writer: Writer
private readonly createdAt: string
private readonly commentCount: number
}Model 역할에서 해당 instance에 데이터를 가공하는 책임을 위임함으로써 응집성있는 코드를 만들 수 있다. 이로써 컴포넌트는 데이터를 사용해서 UI를 렌더링하는데 View의 역할에 집중할 수 있다. 이 코드를 활용해서 위에서 예시로 들었던 컴포넌트 코드를 변경하면 아래와 같다.
...
function RecommendedPostList() {
const [postList, setPostList] = useState([])
useEffect(() => {
async function fetchPost() {
const res = await API.getRecommendedPostList()
const init = res.data.post.recommended_posts
setPostList(new RecommendedPostList(init)) // 응답값으로 인스턴스를 생성한다.
}
fetchPost()
}, [])
return (
<Wrapper>
{postList.IsEmpty // boolean값을 바로 가져올 수 있다.
?
<div>텅텅</div>
))
:
postList.map((post) => (
<RecommendedPost post={post} />
}
</Wrapper>
)
}
function RecommendedPost({ post } : {post: RecommendedPost}) {
return (
<Wrapper>
<Thumbnail src={post.ThumbnailURL} /> // 변수명에 URL이라는 명확성을 부여한다.
<Title>{post.Title}</Title>
<Description>{post.Description}</Description>
<CreatedDate>{post.CreatedAt}</CreatedDate> // format로직을 컴포넌트에서 사용하지 않는다.
<CommentsCount>{post.commentCount}</CommentsCount> // 스네이크 케이스를 사용하지 않는다.
<Writer writer={post.Writer} /> // 클라이언트에서 사용하는 변수명과 일치시킬 수 있다.
<Like>{post.likeCount}</Like>
</Wrapper>
)
}이처럼 리터럴 객체를 Class Instance로 변환하는 작업을 좀 더 쉽게 도와주는 라이브러리로
class-transformer가 있다. 좀 더 관심이 간다면 찾아보도록 하자.
decode/encode function을 사용하는 방식
Class Instance방식과 크게 다르지 않다. 결국 서버의 응답값이 컴포넌트 코드에 도달하기 전 전처리 로직을 끼워넣을 뿐이다.
interface RecommendedPost {
id: string
title: string
description: string
thumbnailURL: string
likeCount: number
writer: Writer
createdAt: string
commentCount: number
}
const decodeRecommendedPost = (init: RecommendedPostResponse) => ({
id: init.id
title: init.title
description: init.short_description
thumbnailURL: init.thumbnail
likeCount: init.likes
writer: decodeWriter(init.user)
createdAt: format(this.createdAt)
commentCount: init.comments_count
})
interface RecommendedPostList {
postList: RecommendedPost[]
isEmpty: boolean
}
const decodeRecommendedListPost = (init: RecommendedPostListResponse) => ({
postList: init.data.post.recommended_posts.map(decodeRecommendedPost)
isEmpty: init.data.post.recommended_posts.length === 0
})useEffect(() => {
async function fetchPost() {
const res = await API.getRecommendedPostList.then(decodeRecommendedListPost)
setPostList(res)
}
fetchPost()
}, [])encode는 반대로 post, put 요청처럼 서버의 형태로 다시 변경해야할 일이 있을 때 반대로 가공하는 로직을 만들어서 추가하면 된다. 이 decode/encode 로직은 API 래퍼를 만들어서 일괄적용하도록 만들면 유용하다!
Class Instance 방식을 사용할지, decode/encode 방식을 사용할지 선택하는 건 개발자의 몫이다. 상황에 따라 적절히 사용하자. React-Query와 조합해서 사용할 때 Class Instance 방식에 이슈가 있다고 해서 decode/encode 방식을 채택했는데, 정확한 이유를 아직 이해하지 못 했다..
마치며..
길게 작성된 코드에 비해 효과가 미비해보일 수 있다. 하지만 이렇게 API <-> 컴포넌트 사이에 데이터 가공 로직을 끼워넣었을 때 누릴 수 있는 이점이 하나 더 있는데, 바로
- API가 미완성일지라도 레이아웃 작업을 진행할 수 있으며
- 서버의 변경에 빠르게 대응할 수 있다는 것이다.
서버의 API 응답 스키마가 확정되지 않았더라도 클라이언트에서 사용할 데이터의 인터페이스를 우선 정의하고 그에 맞게 레이아웃 작업을 진행해두면, 향후 API에서 예상과 다른 응답값이 내려왔을지라도 데이터 가공 레이어에서 미리 정의해두었던 클라이언트 인터페이스에 맞게 변경시켜주면 클라이언트 코드를 수정할 필요가 없어진다!
클라이언트의 컴포넌트 코드는 depth가 깊기 때문에 서버의 응답 스키마가 변경되었을 때, 그에 맞게 변경하는데는 많은 리소스가 든다. 하지만 위 방식은 데이터 가공 레이어만 변경하면 이후 로직은 변경할 필요가 없다!
물론, 상황에 따라 컴포넌트 코드를 수정해야할 일이 생기긴 하지만 데이터 가공 레이어가 있고 없고는 유지보수에 큰 영향을 미친다.
하지만 API 응답값이 변경되어 생기는 문제를 예방하기엔 이 방법만으로는 부족하다. 대응은 용이하겠지만, 런타임에러가 발생하는 건 막을 수 없다. 따라서 다음 글에서는 프론트엔드에서 데이터를 런타임에 검증하는 방법에 대해 이야기해보겠다.



글쓰세요