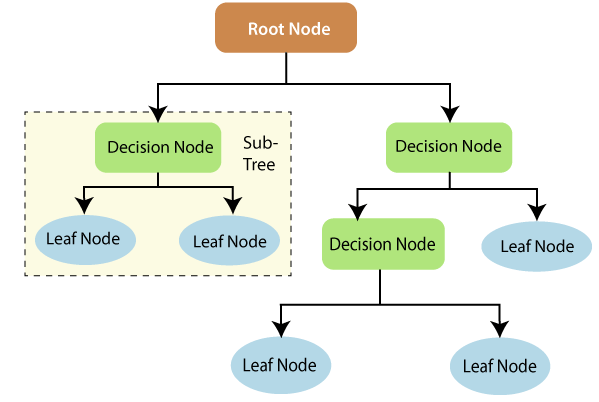
Decision Tree
- 분류, 회귀 작업 및 다중출력 작업도 가능한 다재다능한 머신러닝 방법론
- IF-THEN 룰에 기반해 해석이 용이함
- 일반적으로 예측 성능이 우수한 랜덤 포레스트 방법론의 기본 구조
- CART(Classification And Regression Tree) 훈련 알고리즘을 이용해 모델을 학습
- 나무가 커가는 것처럼 혹은 가지가 뻗어나가는 것처럼 분기해 나가는 방법
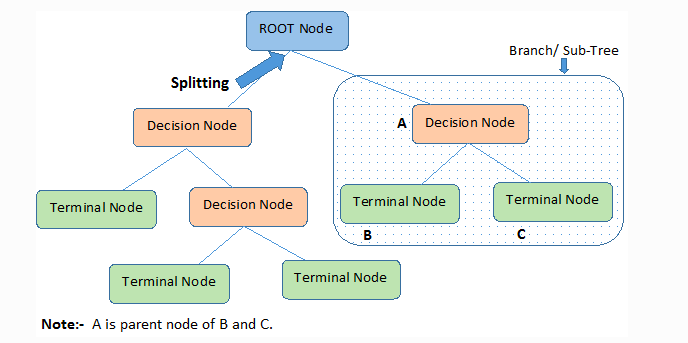
주요 용어
- 트리 분류의 최종 결과 노드를 나무의 잎 즉 Leaf Node라고 부른다
- 반대로 트리의 시작점은 뿌리 Loot Node라고 부른다
- 불순도(Gini index)는 한 노드에 속하는 샘플들의 클래스 비율을 이용해 특정 노드가 얼마나 잘 구분이 되었는지 측정하는 것
IF-THEN 룰

-
한 번에 한 개의 변수를 사용해 정확한 예측이 가능한 규칙들의 집합을 생성
-
if-then 형식으로 표현되는 규칙
(만약에 A라면 a’이다.) -
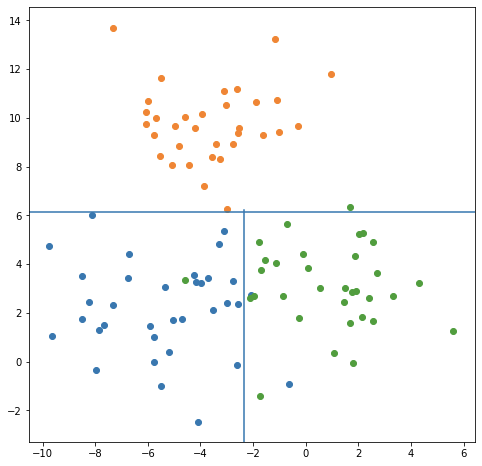
if-then 규칙은 데이터 공간 상에서 각 변수를 수직 분할한 것과 동일하다
(데이터 공간의 순도가 증가 되게끔 영역을 구분하는 방법) -
If-Then 규칙을 이용해 데이터 공간을 분할해서 분류나 예측을 하기 때문에 높은 해석력을 가진다
-
하지만 데이터의 작은 변화에 민감한 한계점이 있다
(Ensemble을 이용해 극복이 가능하다)
CART(Classification And Regression Tree) 알고리즘
-
불순도를 최소화하도록 최종 노드를 계속 이진 분할하는 방법론
-
이 과정은 최대 깊이가 되면 중지하거나 불순도를 줄이는 분할을 찾을 수 없을 때 멈추게 됨
-
훈련 데이터에 대한 제약 사항이 없어 과대 적합(Overfitting) 문제가 일어나기 쉽다
-
훈련에 제약을 두는 방법(Regularization)으로 과대 적합 문제를 해결할 수 있다
주요 파라미터
- max_depth : 트리의 최대 깊이 제어
- min_samples_split : 분할되기 위해 노드가 가져야 하는 최소 샘플 수
- min_samples_leaf : 리프 노드가 가지고 있어야 할 최소 샘플 수
- max_leaf_nodes : 리프 노드의 최대 수

농구를 좋아하는 데이터 분석가 지망생