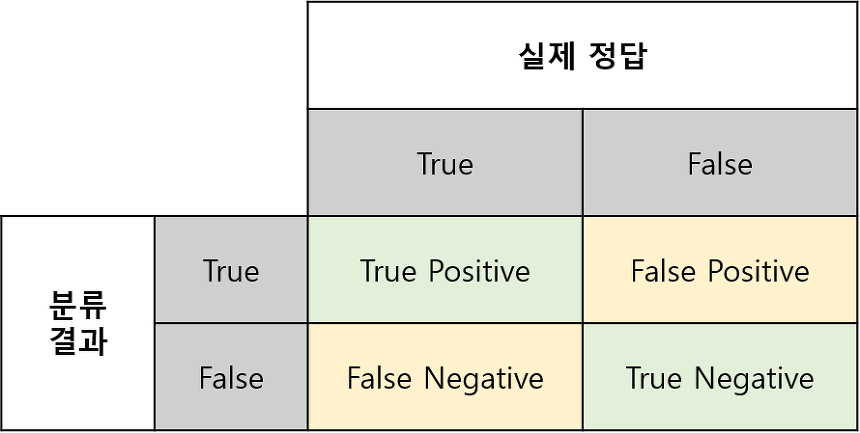
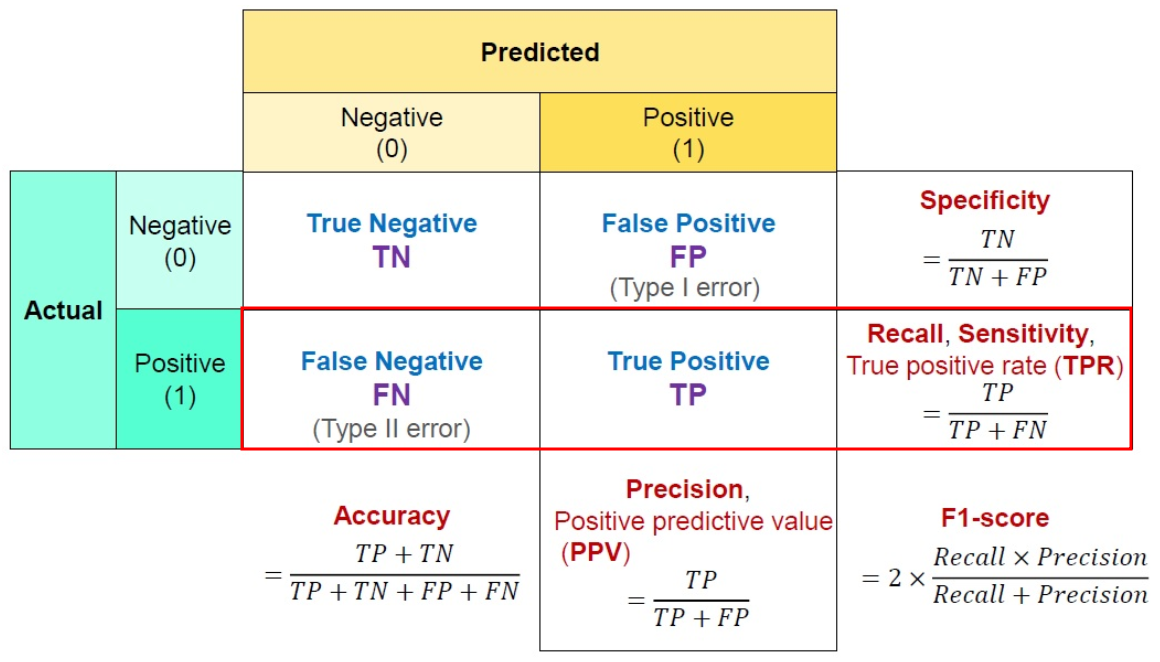
예측과 실제 값 사이의 관계를 행렬 형태로 표현한 것을 Confusion Matrix(혼돈 행렬 or 오차 행렬) 이라고 한다.
- True : 예측한 것이 정답
- False : 예측한 것이 오답
- Positive : 모델이 Positive라고 예측
예) 암 진단 시 암이라고 진단 - Negative : 모델이 Negative라고 예측
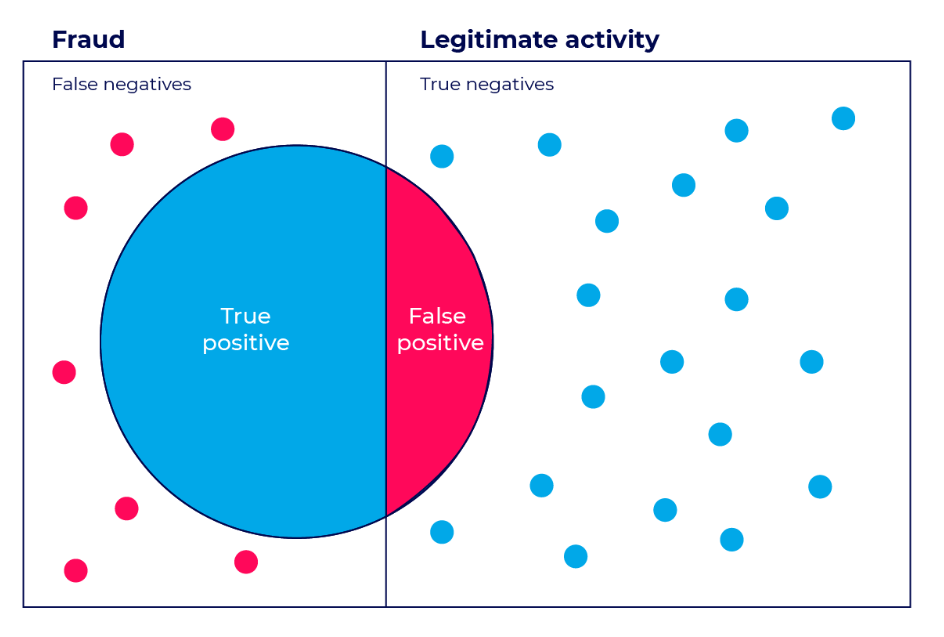
- TP(True Positive) : 모델이 Positive라고 예측한 것이 정답. 즉, 실제 값은 Positive
- FP(False Positive) : 모델이 Positive라고 예측한 것이 오답. 즉, 실제 값은 Negative → 1종 오류
- FN(False Negative) : 모델이 Negative라고 예측한 것이 오답. 즉, 실제 값은 Positive → 2종 오류
- TN(True Negative) : 모델이 Negative라고 예측한 것이 정답. 즉, 실제 값은 Negative
이런 오차행렬에서 머신러닝 모델의 성능을 평가하는 여러 지표를 도출할 수 있다
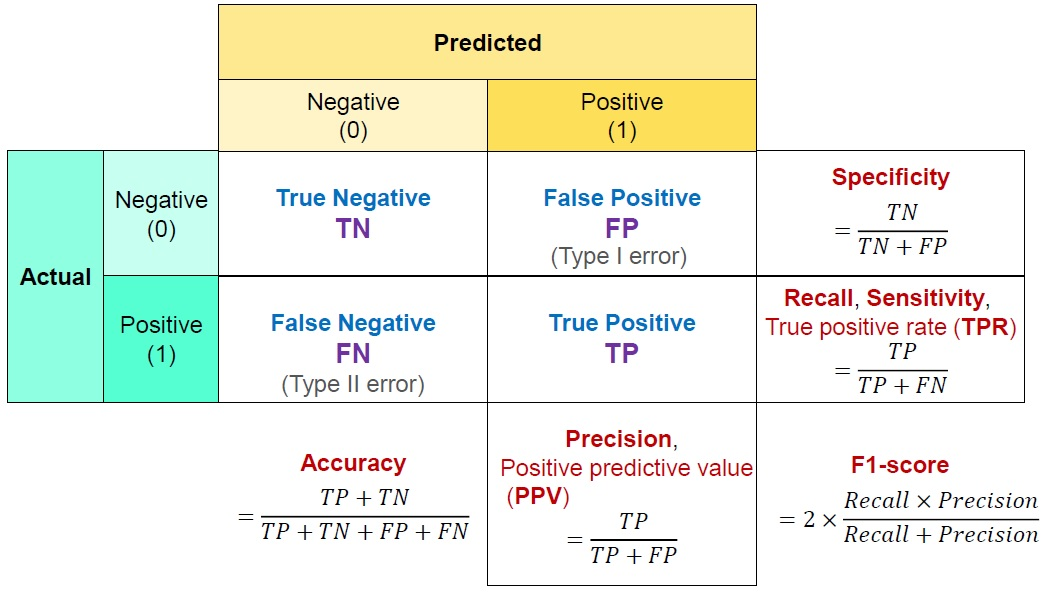
1. Accuracy (정확도)
-
Accuracy = TP + TN / TP + TN + FP + FN
전체 문제 중에서 정답을 맞춘 비율 -
주의 사항 1
이진 분류의 경우 데이터의 구성에 따라 ML(Machine Learning) 모델의 성능을 왜곡할 수 있기 때문에 정확도 수치 하나만 가지고 성능을 평가하지 않음 -
주의 사항 2
정확도 평가 지표는 불균형한 레이블 데이터 세트에서는 성능 수치로 사용돼서는 안됨 -
scikit-learn에서 확인하는 방법
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)2. Precision (정밀도)
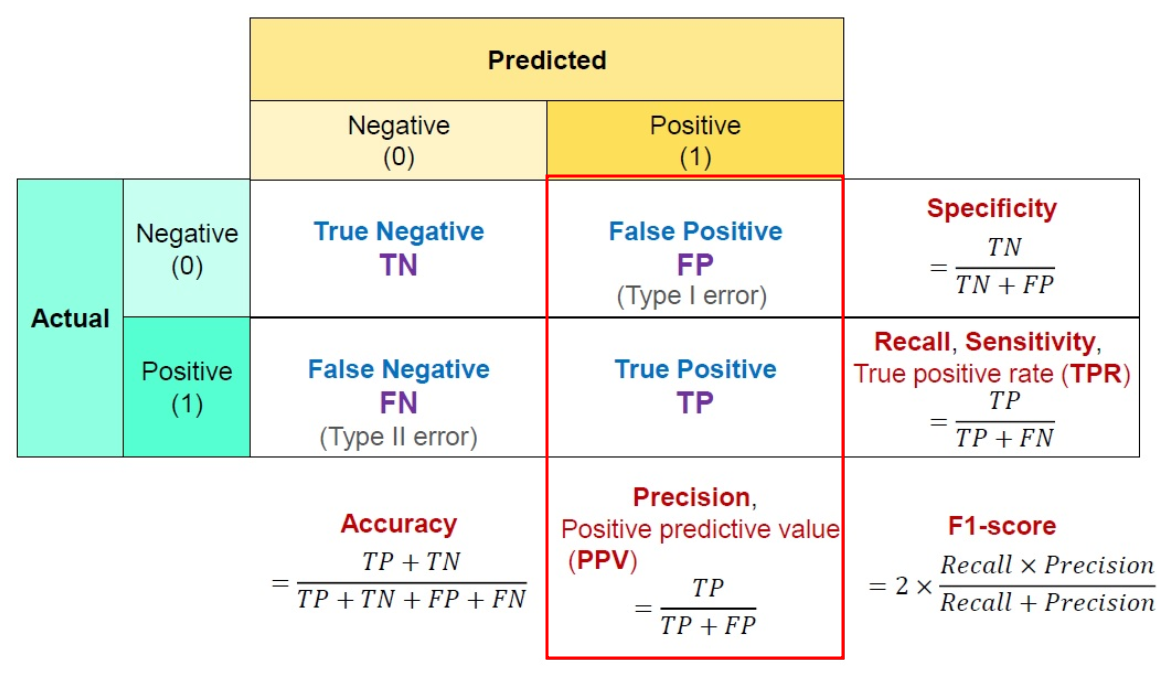
-
Precision = TP(True Positive) / (TP(True Positive) + FP(False positive))
-
정밀도는 True라고 분류한 것들 중에서 실제로 True인 것의 비율이다.
-
PPV(Positive Predictive Value) 즉 Positive 정답률이라고도 불린다.
-
현실 사례
- 스팸 메일을 검출할 때 스팸 메일이 아닌데 스팸 메일로 판단해 차단하면 중요한 메일을 못 받을 수 있다.
- 스팸 메일을 검출할 때 스팸 메일이 아닌데 스팸 메일로 판단해 차단하면 중요한 메일을 못 받을 수 있다.
-
Precision이 낮다 : True가 아닌데 True라고 한 것이 많다
-
Precision이 (과도하게) 높다 : 아주 확실한 경우에만 참으로 예측했다
-
scikit-learn에서 확인하는 방법
from sklearn.metrics import precision_score
x_true = [1, 0, 0, 1, 1, 1, 0, 1, 1, 1]
x_guesses = [0, 1, 1, 1, 1, 0, 1, 0, 1, 0]
precision_score(x_true, x_guesses)3. Recall (재현율)
-
Recall = TP(True Positive) / (TP(True Positive) + FN(False Negative))
-
재현율은 실제 True인 것 중에서 True라고 예측한 것의 비율이다.
-
Sensitivity 혹은 Hit rate라고도 불린다
-
현실 사례
- 지진 지진이 나지 않았지만 지진이라고 예측해 대피명령을 한 것은 생명에 지장이 없지만 지진이 났는데 지진이 나지 않을 것이라고 예측해 대피명령이 없다면 생명이 위험하다
- 암 검출 시 실제로 암에 걸렸는데, 걸리지 않는다고 판단하는 것이 가장 위험하다
- 지진 지진이 나지 않았지만 지진이라고 예측해 대피명령을 한 것은 생명에 지장이 없지만 지진이 났는데 지진이 나지 않을 것이라고 예측해 대피명령이 없다면 생명이 위험하다
- Recall이 낮다 : True인데 못 찾은 것이 많다
- Recall이 (과도하게) 높다 : True로 예측한 것이 필요 이상으로 많다 ※ 모든 예측을 True로 하면 예측 성능과 상관 없이 Recall이 높게 나올 수 있다
- scikit-learn에서 확인하는 방법
from sklearn.metrics import recall_score
x_true = [1, 0, 0, 1, 1, 1, 0, 1, 1, 1]
x_guesses = [0, 1, 1, 1, 1, 0, 1, 0, 1, 0]
recall_score(x_true, x_guesses)Presicion이나 Recall은 모두 True라고 예측한 것과 관련이 있으나, 관점이 다르다고 볼 수 있다.
4. F1-score
Precision과 Recall은 상호보완적이기 때문에, Recall을 올리면 Precision이 내려가고, Precision을 올리면 Recall이 내려갈 수 밖에 없다.
이를 보완하기 위해 생겨난 것이 Recall과 Precision의 조화평균인 F1 score이다.
※ 조화평균이란?
조화평균은 '역수의 산술평균의 역수'이다. 역수의 차원에서 평균을 구하고, 다시 역수를 취해 원래 차원의 값으로 돌아오는 것이라고 한다..
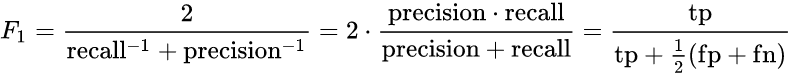
-
Precision과 Recall의 조화평균으로 0.0~ 1.0 사이의 값을 가진다.
-
값이 1에 가까울수록 좋은 모델이다.
-
scikit-learn에서 확인하는 방법
from sklearn.metrics import f1_score
pred = pipe.predict(X_test)
f1_score(y_test, pred)이미지 출처 :
1. https://sumniya.tistory.com/26
2. https://velog.io/@hajeongjj/Eval-Metrics
3. https://www.appsflyer.com/blog/mobile-fraud/click-flooding-detection-false-positive-challenge/
