부스팅(Boosting) 이란?
머신러닝에서 부스팅은 오차를 줄이기 위해 사용되는 학습 방법. 앙상블 기법 중 하나로 약한 모델 여러개를 결합하여 성능을 높이는 알고리즘.
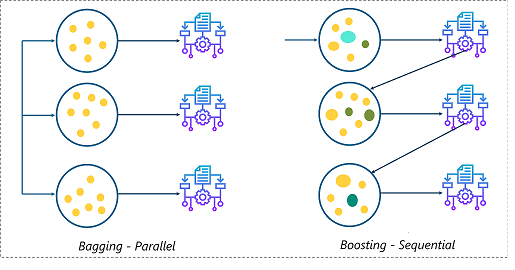
배깅과의 다른 점은 배깅이 여러 데이터셋으로 나눠 학습을 한다면 (동시, 병렬 학습)
부스팅은 데이터셋 모델이 뒤의 데이터셋을 정해주고 앞의 모델들을 보완해 나가며 학습시켜 나간다. (순차, 직렬 학습)
때문에 시간이 보다 오래 걸리고 해석이 어렵다는 단점이 있다.
부스팅의 종류
1. XGBoost
특징
- eXtreme Gradient Boosting의 약자
- 손실 함수가 최대한 감소하도록 하는 분할점(split point)를 찾는 모델.
- Regression, Classification 모두 지원
- 트리부스팅 방식에 경사하강법을 통해 최적화
*경사하강법 : 접선의 경사(기울기)가 0이되는(cost값이 최소가 되는) 지점을 미분을 통해 찾는 방법
장점
- 병렬 처리로 인한 GBM(Gradient Boosting Machine)대비 빠른 수행시간
- 과적합 규제(Regularization)
- 표준 GBM의 경우 과적합 규제 기능이 없으나 XGBoost는 자체 과적합 규제 기능이 있어 강한 내구성을 지님
- 분류, 회귀 모두 뛰어난 예측 성능 발휘
- 조기 종료 기능
- 다양한 하이퍼 파라미터(86개) 제공 및 Customizing 용이
단점
- GBM대비 성능은 우수하나 학습 시간이 느림
- 제공하는 하이퍼 파라미터가 많아 튜닝이 오래 걸림
- 작은 데이터 사용 시 과적합(overfitting) 가능성이 있음
(XGBoost가 충분히 좋은 성능을 내기 위해선 많은 데이터가 필요하다는 의미) - 다른 앙상블 계열 알고리즘과 같이 해석이 어려움
2. LightGBM
특징
XGBoost의 장점은 계승하고 단점은 보완하는 방식으로 개발된 부스팅 모델로 GOSS(Gredient-based One-side Sampling) 방식으로 데이터 개수를 내부적으로 줄여서 계산하여 모델링 시간을 단축시켰다.
* GOSS : Gredient의 크기를 기반으로 샘플링하여 큰 Gredient를 갖는 데이터는 남기고, 작은 Gredient 데이터 개체들에서 무작위 샘플링을 진행 방식
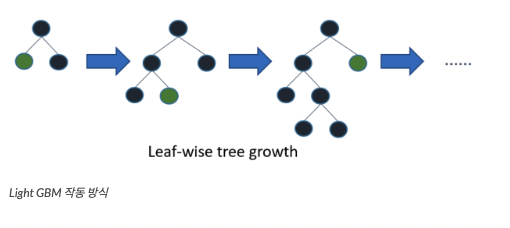
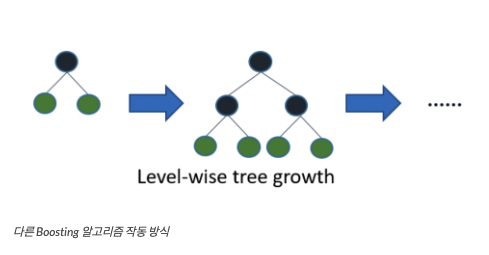
다른 알고리즘이 일반적으로 균형 트리 분할(Level-wise)방식을 사용하는 반면 LightGBM은 리프 중심 트리 분할(Leaf-wise) 방식을 사용한다.
* 리프 중심 트리 분할(leaf-wise)
트리의 균형을 맞추지 않고 최대 손실값을 가지는 리프 노드를 지속적으로 분할하며 확장하여 비대칭적 트리를 생성한다.
장점
- 학습을 반복할수록 예측 오류 손실을 최소화할 수 있다
- XGBoost 대비 학습 시간이 짧다
- 메모리 사용량도 상대적으로 작다
단점
- 파라미터 조정 실패 시 과적합 가능성이 존재한다
- 작은 데이터 사용 시 과적합 발생이 쉽다
3. CatBoost
특징
2017년 개발된 범주형 데이터 처리에 특화된 오픈 소스 소프트웨어 라이브러리
Cat(egorical)
장점
- GBM의 한계점이던 과적합 문제를 해결함
- GBM 계열 XGBoost, LightGBM의 학습 속도 저하 문제 개선
- 하이퍼 파라미터 튜닝을 알고리즘 내부에서 처리
단점
- 결측치가 많은 데이터셋에는 부적합
- 수치형 변수가 많을 경우 학습에 시간이 소요됨

농구를 좋아하는 데이터 분석가 지망생