이 논문 왜 봐야해?
- model-based planning은 아래의 장점들을 지님
- data efficiency 증가
학습한 dynamics로, 다양한 task나 환경에 transfer 할 수 있음(우리 domain을 생각해보면, 학습시 없었던 센서 배치의 로봇에 알고리즘을 탑재시켜도, zero-shot으로 적응하거나, 적은 fine-tuning으로 주행 가능할 수 있음)
- BUT! model-based planning 분야에서 극복해야할 문제
- model의 부정확도로 인한 Error 누적
- 미래의 결과에 대한 다양한 정보를 모두 담지 못하는 문제
- unseen state 혹은 잘 학습되어지지 않은 state에 대한 -> uncertainty를 가지지 않는다는 문제
- 이 논문은, Model-based planning의 해결해야할 위 과제들을 개선
이 논문의 한계점?
- 오랜 시간 범위에 걸쳐 planning하는 것은, 지나치게 계산 비용이 많이 듦.
Abstract
- 이 논문 기여
- 기여 1:
image based task에서, latent space만을 가지고 planning을 진행했는데 실험 결과가 좋음.- latent space: 고차원의 정보를 잘 함축하여, dynamics model를 잘 학습한 space.
- dynamics model?
- s_t와 at가 주어졌을 때, r_t 와 s_t+1 를 예측하는 모델
- latent state와 action이 주어졌을 때, 다음 latent state와 reward를 예측하는 모델
- 이미지 공간에서의 예측 방법과 비교할 때,
- latent space는 작은 메모리 공간을 가지기 때문에 -> 병렬적으로 수천 개의 궤적을 상상하는 것이 가능
- dynamics model?
- latent space: 고차원의 정보를 잘 함축하여, dynamics model를 잘 학습한 space.
- 기여 2:
Recurrent State Space Model위 model-based planning의 극복과제 1번, 2번, 3번을 개선.- transition model(st-1,at-1 인풋)의 output(st) 출력 형태를, deterministic과 stochastic 하게 했을 떄의 장점만을 취한 방법론 RSSM을 제안.
- st를 only deterministic 하게 유추했을 때의 단점
- 아래 이유로 (특히 schocastic 환경에서) 최적의 해를 찾지 못할 수 있음.
- model이 multiple feature을 잡아낼 수 없음.
- 한번 부정확한 모델이 만들어졌으면, 그걸 너무 믿어버림.
- 아래 이유로 (특히 schocastic 환경에서) 최적의 해를 찾지 못할 수 있음.
- st를 only stochastic 하게 유추했을 때의 단점
- multiple time steps의 정보를 다 장기 기억하고 있기 어려움.
- 결론: RSSM은
확률적인 dynamics를 배울 수 있으면서도, 이로 인해 장기 기억 손실로 인해 학습이 망가지는 것을 막아, 좋은 성능 확보 가능
- 기여 3:
"Latent overshooting"- model은 multi-step에 대한 prediction을 통해, 환경을 배우는 능력을 키웁니다.(dynamics model을 더 잘 학습합니다.)
Latent space planning
- 해당 논문은
- policy network 안써요.
- value network 안써요.
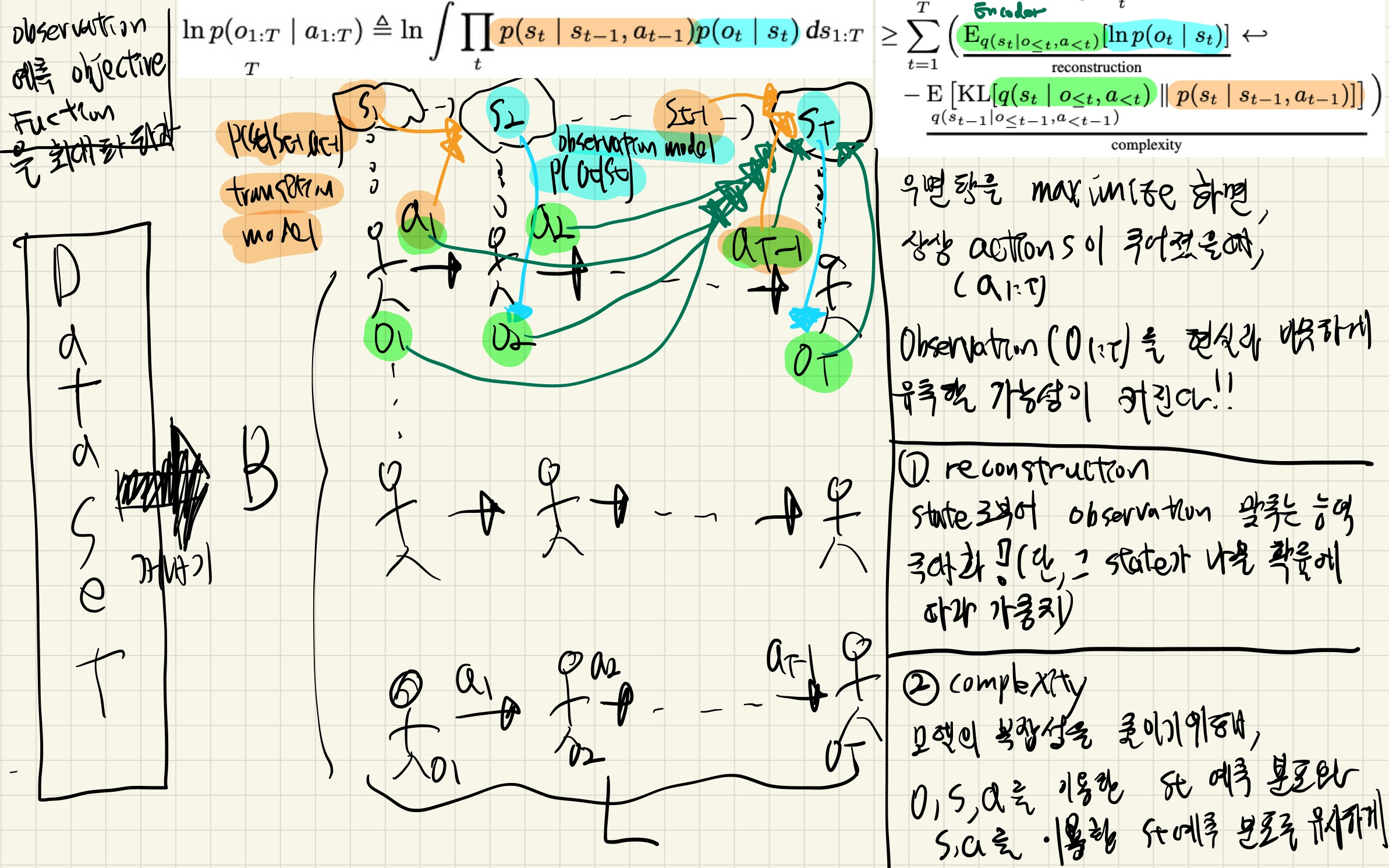
Overall Algorithm
- 처음에는, Random action으로 움직여서 data S를 만듦
- model 학습한다.
- batch_size * seq_len 데이터 꺼내서
equation3을 최대화 하는 방향으로 학습하는 과정을 C번 반복- 아래
Training objective (equation3)그림 을 보면, 잘 이해할 수 있으니 지금 이해 못해도 괜찮다.
- 아래
- batch_size * seq_len 데이터 꺼내서
- action은 (환경에서의 유의미한 변화를 만들기 위해) R step 움직여서 데이터셋에 추가
- 아래
planning algorithm그림의 출력값을 기반으로 움직이면서 모아짐. - 아래 그림을 보면, 잘 이해할 수 있으니 지금 이해 못해도 괜찮다.
- 아래
- 그 후. 다시 위 model 학습으로 돌아간다. (이걸 반복)

각 모델 간략 소개
Transition model
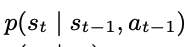
- feed forward NN
- output: state에 대한, Gaussian mean과 variance
Reward Model
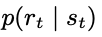
- feed forward NN
- output: reward에 대한, Gausian mean과 unit variance
Observation model
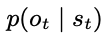
- deconvolutional NN
- output: observation에 대한, Gaussian mean과 identity covariance
variational encoder (=state belief model = Representation encoder)
- Variational AutoEncoder(VAE)
- Variational: https://velog.io/@jk01019/Variational-뜻
- 복잡한 데이터를 간단한 형태로 압축하고, 그 압축된 정보로부터 다시 원래의 데이터를 복원하는 기술
- encoder / decoder로 이루어짐
데이터의 압축과 복원과정에서 볼확실성을 다룬다는 것이 핵심encoder가 데이터를 압출할 때, 그 압축한 데이터의 (불)확실한 정도까지 함께 고려- 인코더는 평균과 로그 분산 2가지를 출력함 (이 2가지는 latent representation = z을 형성)
- 로그 분산이 크다는건, 불확실성이 높다는 뜻.
- reparameterization trick
- 인코더는 각 데이터 포인트에 대해 고유한 latent vector을 생성하는 대신, 각 변수가 어떤 분포를 따르는지를 정의
- 목적:
O_1~O_t+a_1 ~ a_t_1을 이용해서, 어떻게s_t를 생성하는지에 대한 딥러닝 네트워크 - CNN(observation 압축을 위한)과 feed forward로 이루어짐
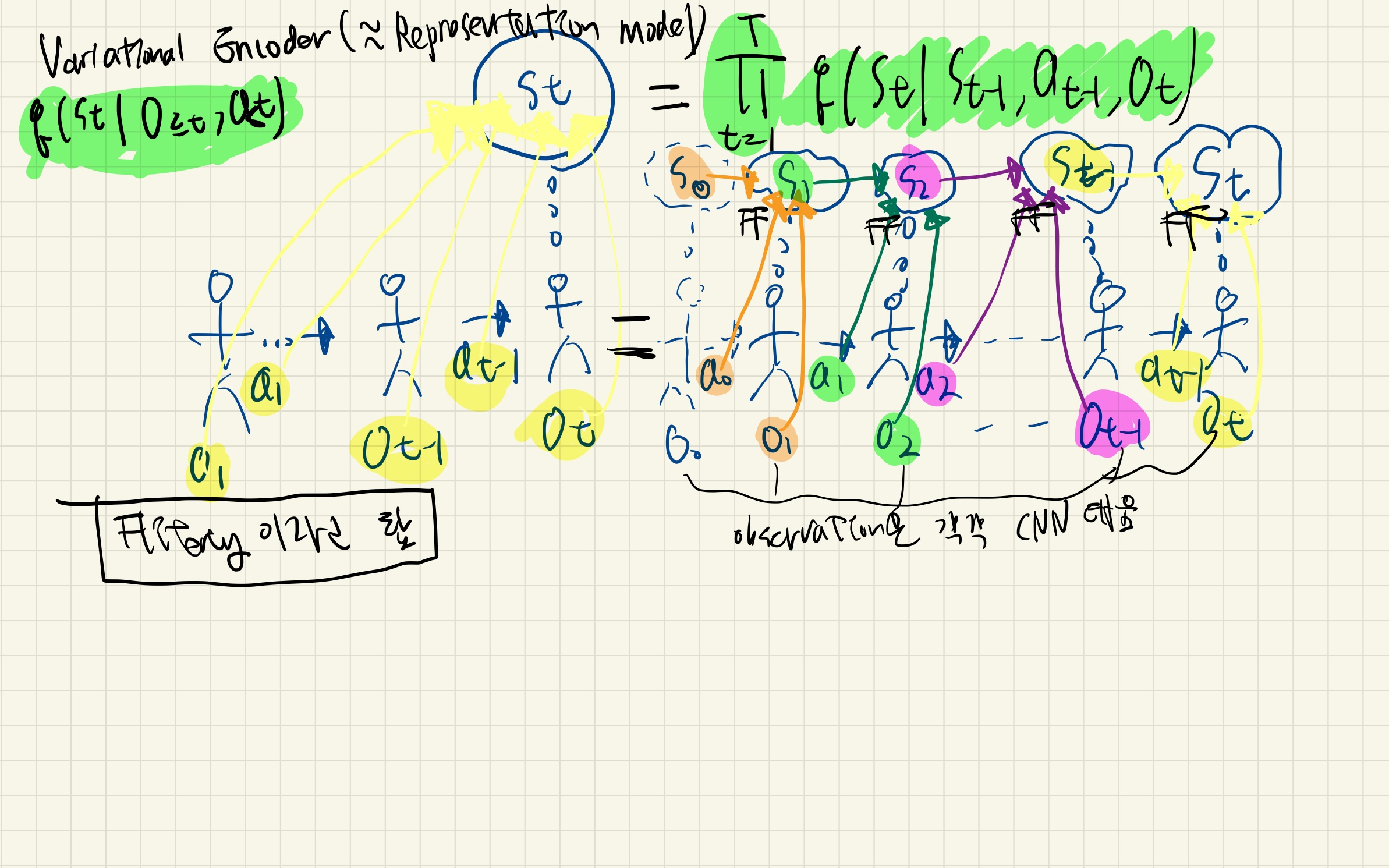
- 기존의 연구들과 다르게,
state posterior을 오직 바로 이전의 observation과 action의 곱으로 가정.- 이를 filtering이라고 부름
- 이해해보기
- Posterior: https://velog.io/@jk01019/Posterior-뜻
agent가 가지는 현재 상태에 대한 확신이 오직 바로 이전에에이전트가 관찰한 것과그가 취한 행동에만 기반한다고 가정
- Posterior: https://velog.io/@jk01019/Posterior-뜻
위 filtering 가정을 통해, 우리는 variational encoding 과정을 수행합니다.
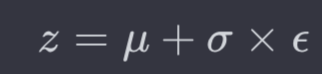
Training objective (equation3)
- 아래 그림은, 과제 1:
"actions 를 기반으로 행동했을 때 예측한 observations"이 "실제 observations"와 같아질 확률을 최대화하는 목표를 풀기 위한, objective function 을 구하는 과정- 아래 그림 수식의 좌변을 의미합니다.
- 이 과정은, 아래 2단계를 계속 반복하는 과정입니다.
- s_t-1 과 a_t-1로 s_t를 맞춘 후,
- s_t로 o_t를 맞추는 과정
- 결국 이 과정은, lower_bound 조건 2가지를 최대화하는 방향으로 학습하면 된다. (lower bound를 최대화하면, 자연스럽게 과제도 해결될 것이다.)
- 조건 1: state가 주어졌을 때 observation 잘 맞추는 방향으로 (재구성 잘하기)
- 즉,
observation model을 supervised learning으로 학습!
- 즉,
- 조건 2:
variational encoder(o,s,a 이용, 전체 시간)을 이용해서 예측한 state 확률 분포와,transition model(s, a 이용, 바로 전 시간만)을 이용해서 예측한 state 확률 분포를 유사하게 가져가는 방향으로 (복잡성 낮추기) + mutual information 극대화하기- 즉,
encoder와transition model을 유사하게 학습!
- 즉,
- 조건 1: state가 주어졌을 때 observation 잘 맞추는 방향으로 (재구성 잘하기)
- 참고로 과제 2:
actions 를 기반으로 행동했을 때 예측한 reward가, 실제 reward와 같아질 확률을 최대화하는 목표를 풀기 위한, objective function도 똑같이 구하면 된다.- 이 과제2를 통해
reward model이 학습된다.
- 이 과제2를 통해
확률적인 변수를 다루는 대신에, 변수를 결정론적인 형태로 변환하여 샘플링 과정을 최적화할 수 있도록(reparameterized trick)하여latent variable 분포에 대한 평균을 구하는 것은- inference와 training을 위한 효율적인 Objective function(
non-linear latent variable model의 파라미터를 최적화하기 위한 목적 함수)을 제공gradient ascent를 이용하여 최적화할 수 있으므로 효율적이라는 뜻.
- inference와 training을 위한 효율적인 Objective function(
Planning Algorithm
- 맨 처음 action candidates들은 random하게 선택!
- output에 gaussian noise 추가.

- 매 step에 대해 다시 초기화시켜, local minimum에 빠지는 것을 방지
- 모든 연산은 enviromnet가 개입되어 있지 않은 latent state 상에서 이루어지므로 병렬적으로 이루어질 수 있음.
Recurrent State Space Model (RSSM)
잠깐 복습: transition model
- feed forward NN
- output: reward에 대한, Gausian mean과 unit variance
본론
- 위 transition model을, deterministic과 stochastic 하게 만드는 방법들의 장점만 취한 RSSM 제안
- st output이, only deterministic일 때 단점
- 아래 이유로 (특히 schocastic 환경에서) 최적의 해를 찾지 못할 수 있음.
- model이 multiple feature을 잡아낼 수 없음.
- 한번 부정확한 모델이 만들어졌음애도, 그걸 너무 믿어버림
- 아래 이유로 (특히 schocastic 환경에서) 최적의 해를 찾지 못할 수 있음.
- st output이, only stochastic일 때 단점
- multiple time steps의 정보를 다 장기 기억하고 있기 어렵다.
- 결론:
확률적인 dynamics를 배울 수 있으면서도, 이로 인해 장기 기억 손실로 인해 학습이 망가지는 것을 막아, 좋은 성능 확보 가능
- st output이, only deterministic일 때 단점
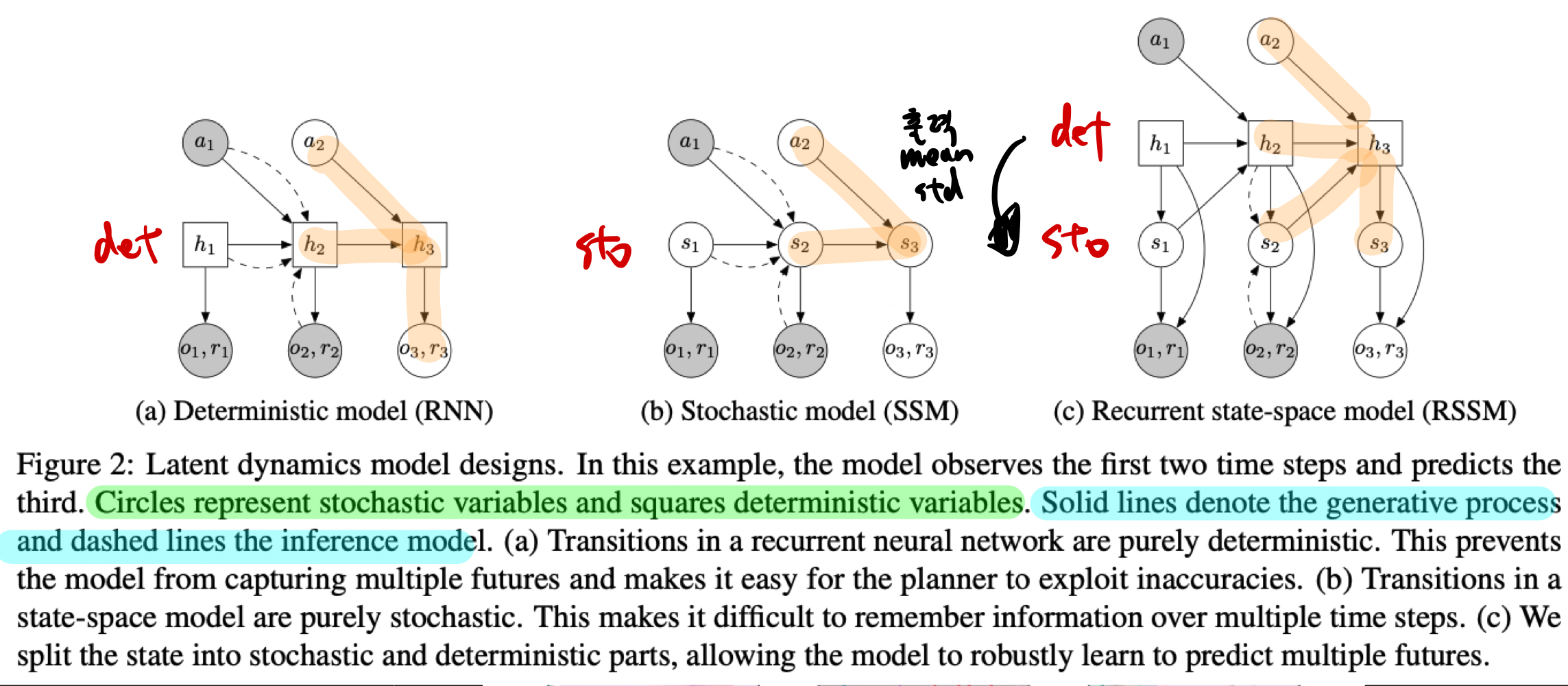
- 위 각 그림에, 4가지 model들을 하나씩 의미부여해보면 이해하기 쉬울 것이다.
참고: generative process (실선)
- 눈코입 -> 얼굴 생성
- 데이터가 어떻게 만들어지는지, (데이터 생성 원리 학습)
참고: inference model (점선)
- 얼굴 -> 눈코입 생성
- 데이터로부터 무엇을 알아낼 수 있는지
- 데이터의 의미와 원인과 패턴 파악
Latent Overshooting
잠깐 복습: Training Objective
본론: Latent overshooting
- 기존의 방법으로는 아래 transition model 이 오직 한 step에 대해서만 reconstruction loss와 complexity loss를 계산했었음.
- 본 눈문에서는 transition model이 multi-step에 대한 update를 하는 latent overshooting을 사용
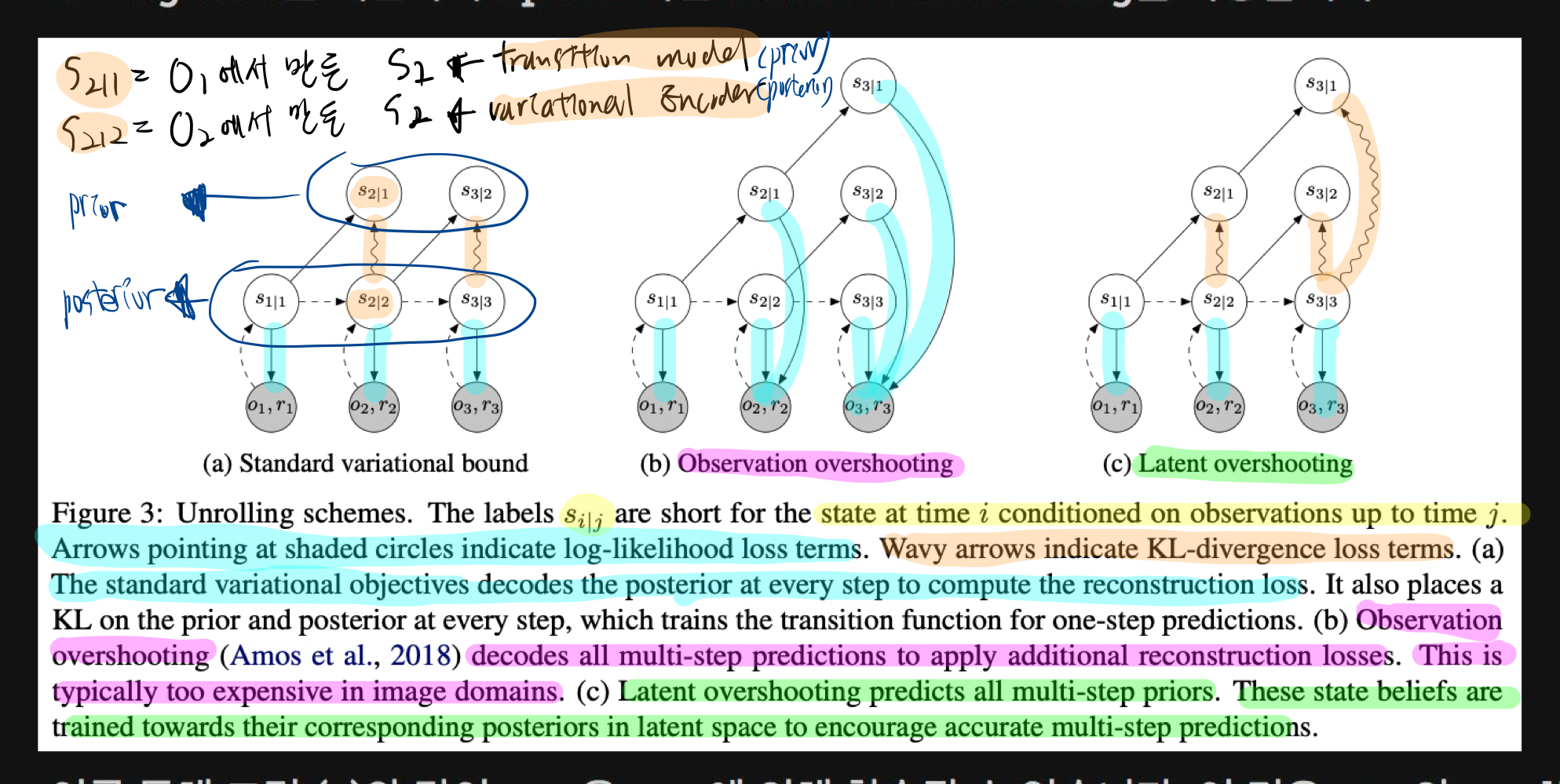
- 위 방법은 RSSM과 결합했을 때는 그렇게 성능이 향상되진 않았습니다.
- 하지만, 다른 알고리즘들과 결합했을 때는 성능이 올랐습니다.

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.