강화학습
1.Multi-task Deep Reinforcement Learning with PopArt

강화학습 커뮤니티는 인간의 성능을 능가할 수 있는 알고리즘을 개발하는 데 큰 발전을 이루었습니다. 이러한 알고리즘들은 대부분 한 번에 한 가지의 작업을 학습하며, 새로운 작업마다 새로운 에이전트 인스턴스를 학습해야 합니다.이는 학습 알고리즘은 일반적이지만 각 해결책은
2.Aggressive Q-Learning with Ensembles: Achieving Both High Sample Efficiency and High Asymptotic Performance
최근 모델-프리 기반의 심층 강화학습(DRL)에서의 발전은 간단한 모델-프리 방법이 고차원 연속 제어 작업에서 매우 효과적일 수 있다는 것을 보여줍니다. 특히, Truncated Quantile Critics (TQC)는 비평자의 분포 표현을 사용하여 MuJoCo 벤치
3.Learning values across many orders of magnitude
Abstract Introduction
4.Observe and Look Further: Achieving Consistent Performance on Atari
심층 강화 학습(Reinforcement Learning, RL) 분야에서의 중요한 발전에도 불구하고, 현재의 알고리즘들은 아타리 2600 게임과 같은 다양한 과제 집합에 대해 일관적으로 인간 수준의 정책을 학습하는 데 실패하고 있습니다. 우리는 모든 게임에서 우수한
5. Temporal Difference Learning for Model Predictive Control
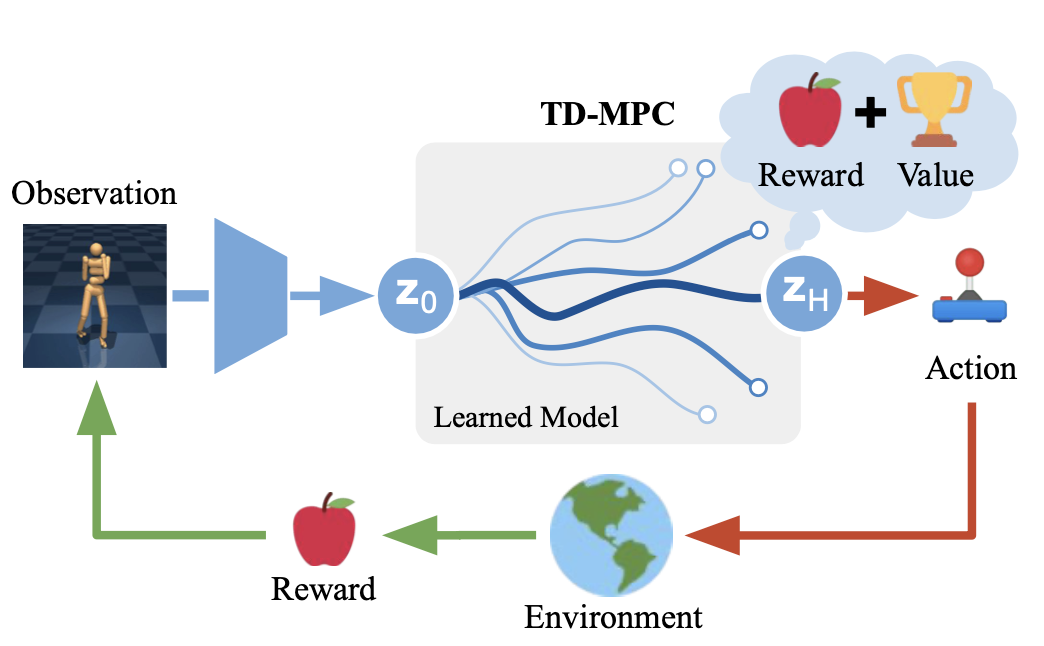
Data-driven Model Predictive Control > model-free모델 학습을 통한 개선된 샘플 효율성(sample efficiency)의 잠재성계획(planning)을 위한 계산 예산(computational budget)이 증가함에 따라 더 나
6.on-policy vs off-policy
on_policy: 학습하는 policy와 행동한 policy가 반드시 같아야만 학습이 가능한 강화학습 알고리즘off-policy: 학습하는 policy와 행동한 policyrk 반드시 같지 않아도 학습 가능한 알고리즘
7.soft actor critic 설명 및 네트워크 구조
작성 중
8.I2Q: A Fully Decentralized Q-Learning Algorithm

independent Q-learning이 decentralized training에 많이 쓰이지만, 아래의 이유로 수렴이 보장되지 않음아래의 이유로 transition probabilities가 non-stationary(통계적 특성이, 시간의 흐름이 따라 변함)다른
9.Estimating Q(s, s′) with Deep Deterministic Dynamics Gradients
그림들 기존 actions 중 Q값이 큰 action을 선택하여 이동 states 중 Q값이 큰 state를 선택하여 이동(바로 이동할 수 없으니, inverse dynamics를 이용하여 action 도출) Abstract value function Q(s
10.[강화학습] Stationary & Markovian
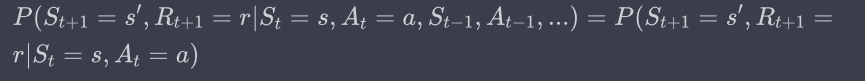
강화학습의 기본 가정환경이 stationary하고 Markovian 하다.어떤 상태에서의 보상이나 다음 상태의 확률 분포는 시간이 지나도 변하지 않습니다.deterministic 하다고 부를 수도 있습니다.Markov 특성을 가진 환경에서는 현재 상태만이 미래의 상태와
11.discrete-tfxl-coma
\_get_valuesget_actions_inferenceget_actions_learningget_actor_lossget_return_estimateget_temperature_lossMLPGaussianActor 대신, MLPDiscreteActor 을 씀MLP
12.Masked Autoencoding for Scalable and Generalizable Decision Making
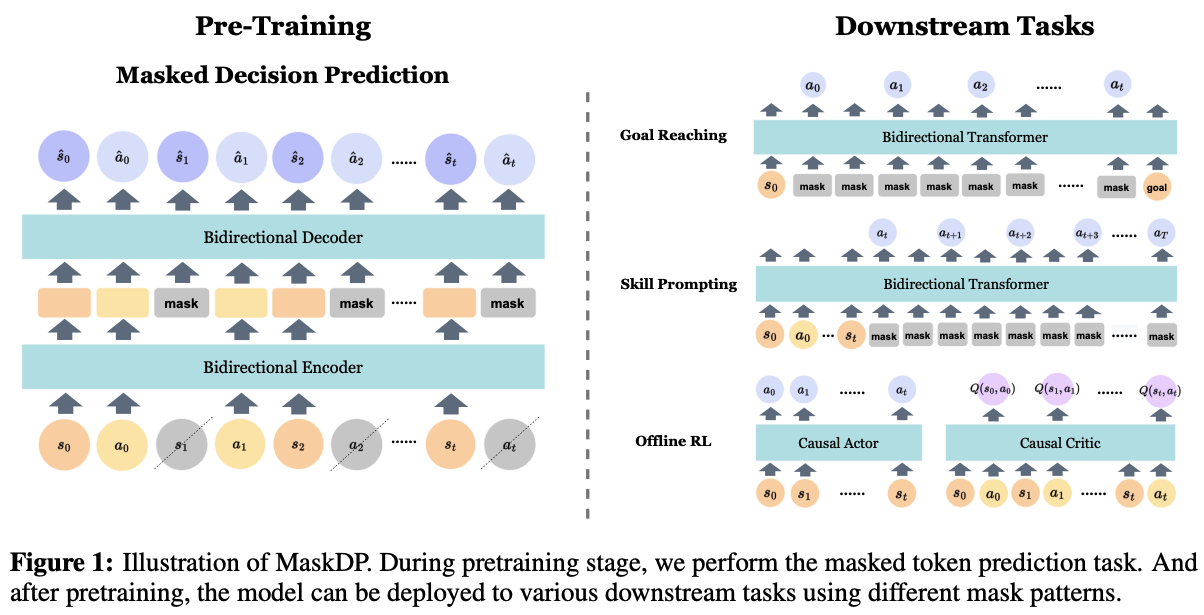
목적: 뛰어난 적응력과 효율성을 지닌 강화 학습 알고리즘을 만들기 위해, 다양한 순차 데이터(st, at, .. 조합)을 이용해 사전 훈련masked decision prediction(MaskDP)목적zeroshot 전이 능력 향상처음 마주하는 환경에서도 에이전트가
13.SIMPLIFYING MODEL-BASED RL: LEARNING REPRESENTATIONS, LATENT-SPACE MODELS, AND POLICIES WITH ONE OBJECTIVE
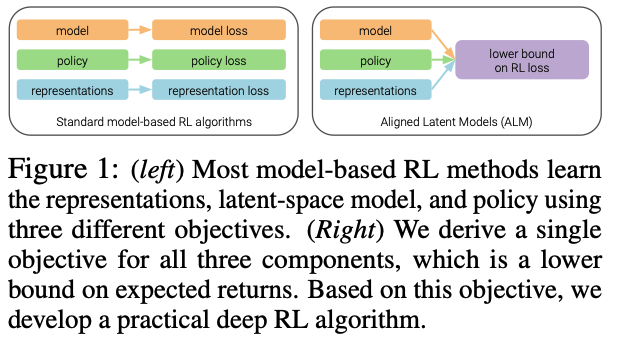
모델 기반 알고리즘의 세 구성 요소인 표현, 모델, 정책 의 개념강화 학습에서 에이전트가 환경으로부터 얻은 원시 데이터(관측값)를 처리하고 이해하는 방법이는 복잡한 데이터를 더 간단하고, 학습에 유용한 형태로 변환하는 과정모델은 에이전트가 환경의 다음 상태와 가능한 보
14.[dreamer] DREAM TO CONTROL: LEARNING BEHAVIORS BY LATENT IMAGINATION
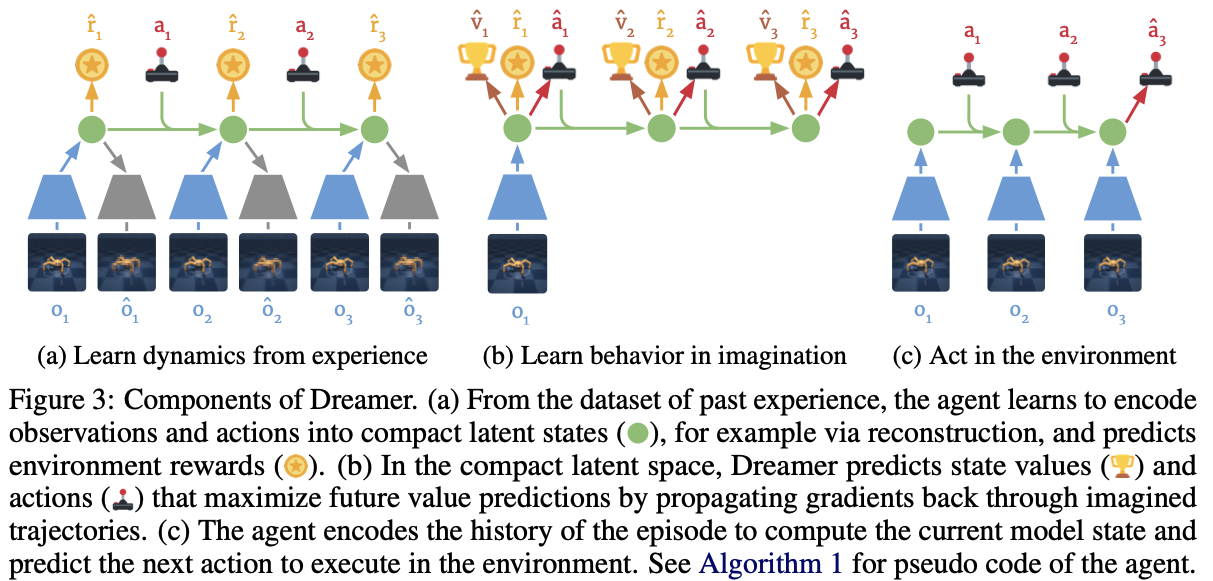
test
15.[dreamer-v2] MASTERING ATARI WITH DISCRETE WORLD MODELS
https://arxiv.org/pdf/2010.02193.pdf
16.bayes 정리 & bayesian modeling
"베이즈 정리"는 확률에 관한 중요한 규칙으로, 이미 알고 있는 정보를 바탕으로 새로운 사건의 확률을 추정하는 데 사용베이즈 정리는 기본적으로 '이미 알고 있는 정보(사전 확률)'와 '새로운 증거'를 결합하여 '새로운 사건의 확률(사후 확률)'을 계산하는 방법을 제공합
17.PlaNet(Learning Latent Dynamics for Planning from Pixels)
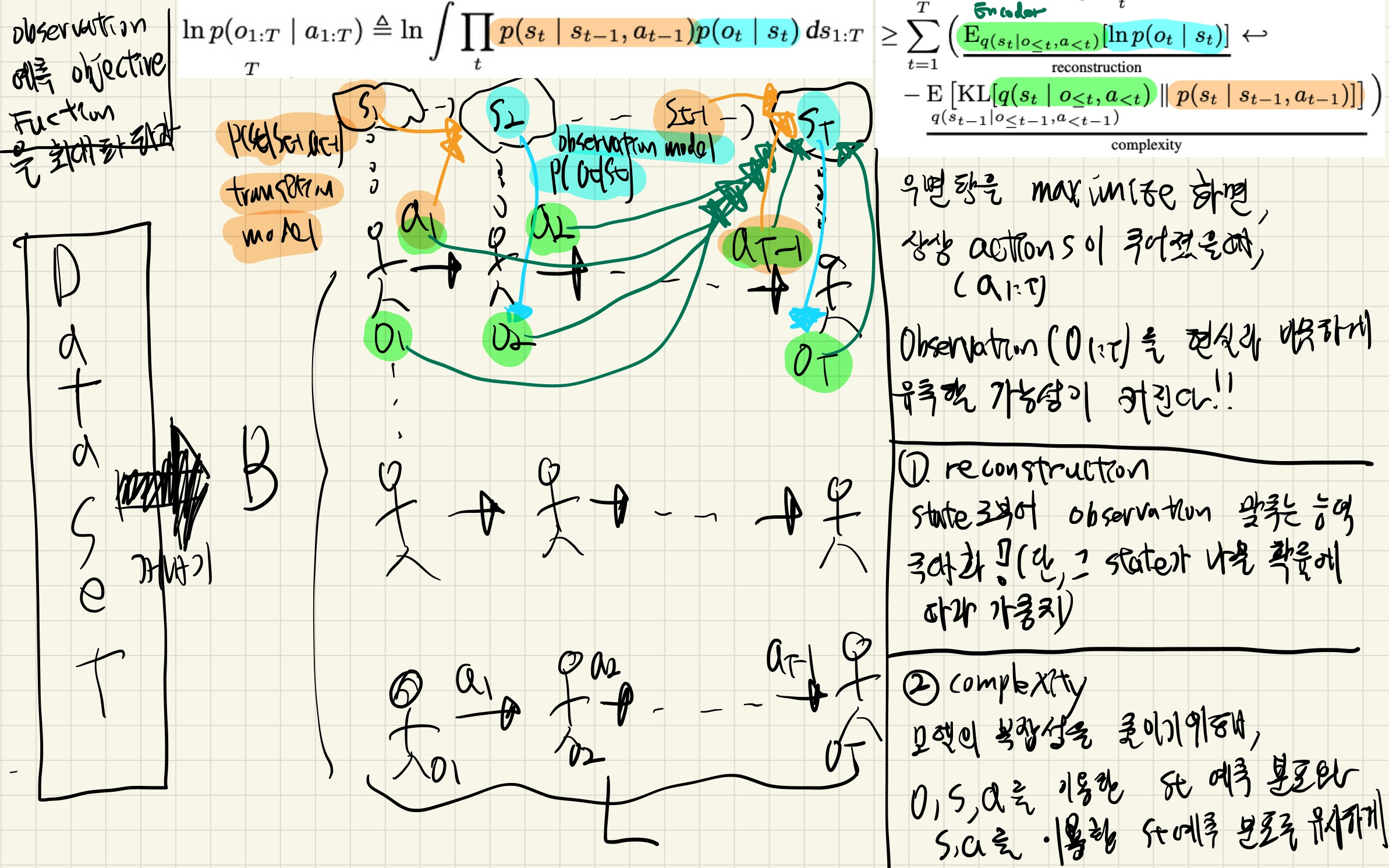
이 논문 기여기여 1: image based task에서, latent space만을 가지고 planning을 진행한다.latent space: dynamics를 잘 학습한 space이므로.dynamics: state 와 action이 주어졌을 때, 다음 state와
18.temporal difference learning
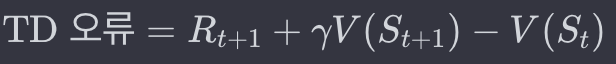
예측과 실제의 차이 (TD 오류): TD 오류는 현재 상태의 가치 예측과 다음 상태의 가치 예측 사이의 차이입니다. 이 오류는 학습 과정에서 가치 함수를 업데이트하는 데 사용됩니다.가치 함수의 업데이트: TD 학습은 예측 가치와 실제로 얻은 보상 및 다음 상태의 가치를
19.RLHF(RL with Human Feedback)
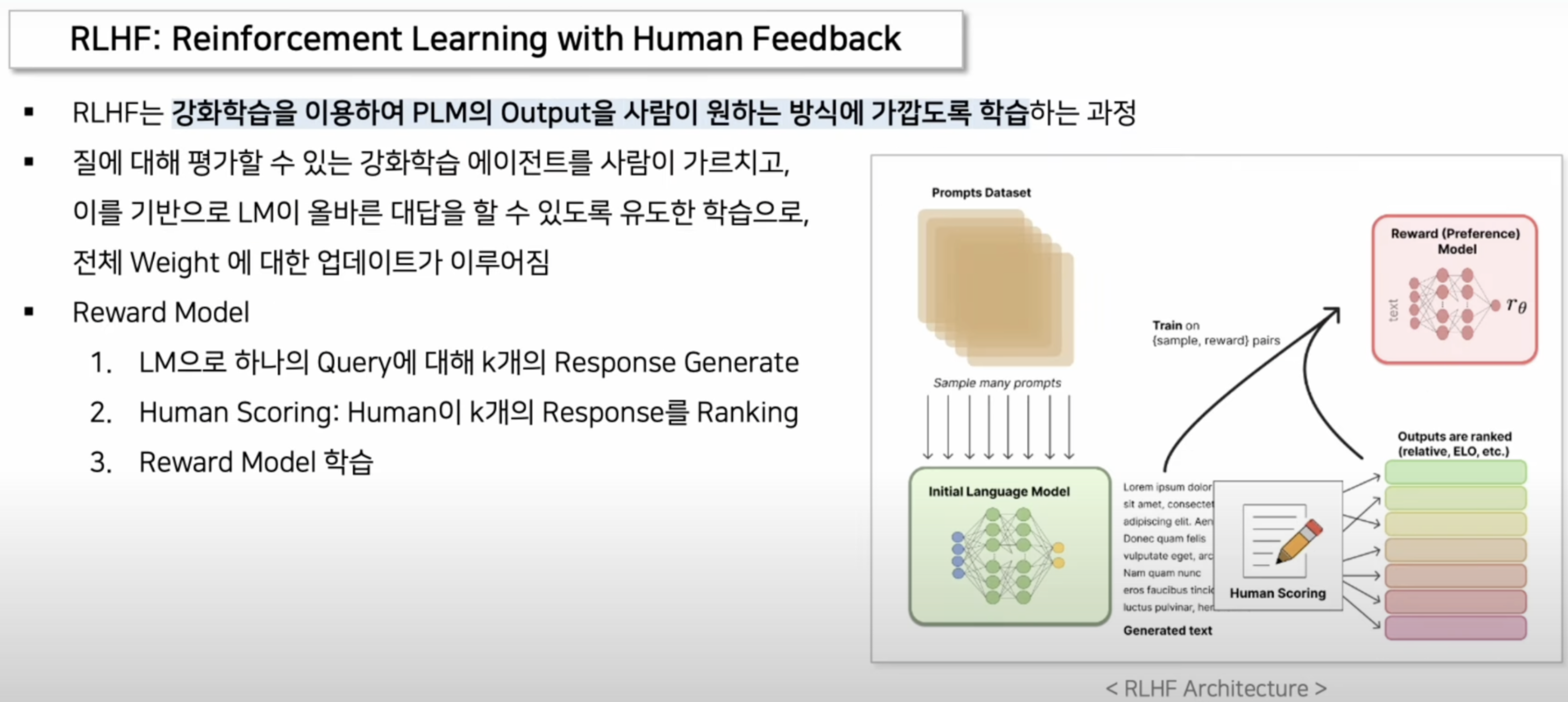
RLHF는 강화 학습을 이용하여 인간의 피드백을 통해 언어 모델의 출력을 사람이 원하는 방식에 가깝도록 학습하는 과정먼저, 대규모 텍스트 데이터를 사용하여 초기 언어 모델을 사전 학습이 모델은 다양한 입력 프롬프트에 대한 응답을 생성할 수 있습니다.모델이 생성한 여러