- 예측과 실제의 차이 (TD 오류): TD 오류는 현재 상태의 가치 예측과 다음 상태의 가치 예측 사이의 차이입니다. 이 오류는 학습 과정에서 가치 함수를 업데이트하는 데 사용됩니다.
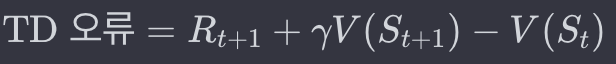
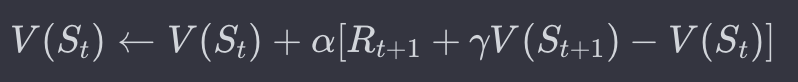
- 가치 함수의 업데이트: TD 학습은 예측 가치와 실제로 얻은 보상 및 다음 상태의 가치를 비교하여 현재 상태의 가치 함수를 업데이트합니다. 이 과정을 통해 에이전트는 보다 정확한 가치 예측을 할 수 있게 됩니다.

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.