이 논문 왜 봐야해?
- model-based planning은 아래의 장점들을 지님
- data efficiency 증가
학습한 dynamics로, 다양한 task나 환경에 transfer 할 수 있음(우리 domain을 생각해보면, 학습시 없었던 센서 배치의 로봇에 알고리즘을 탑재시켜도, zero-shot으로 적응하거나, 적은 fine-tuning으로 주행 가능할 수 있음)
- BUT! model-based planning 분야에서 극복해야할 문제
- model의 부정확도로 인한 Error 누적
- 다양한 미래의 결과에 대한 정보를 모두 담지 못하는 문제
- unseen 혹은 잘 학습되어지지 않은 state에 대한 uncertainty를 가지지 않는다는 문제
- 위 문제들을 극복하기 위해, 기존 연구들은 PlaNet(https://velog.io/@jk01019/PlaNetLearning-Latent-Dynamics-for-Planning-from-Pixels) 와 같은 방법론으로 개선했었음
- PlaNet을 더 개선
- planet은 actor을 쓰지 않았는데, dreamer처럼 actor network을 쓰면 아래와 같은 장점
- gaussian distribution 분포로 action을 출력하면서도, 미분 가능한 policy(action) model 도입
- gaussian distribution 분포로 action을 출력하면서도, 미분 가능한 policy(action) model 도입
- planet은 critic을 쓰지 않았는데, dreamer처럼 critic network를 쓰면 아래와 같은 장점
- critic이 없으면, 정해진 길이의 imagination을 하는 것만 가능하고, 이는 shortsighted optimization하려하는 경향을 보임
Learning long-horizon behaviors by latent imagination- Dreamer은 exponentially weighted value function을 통해 구현.
- planet은 actor을 쓰지 않았는데, dreamer처럼 actor network을 쓰면 아래와 같은 장점
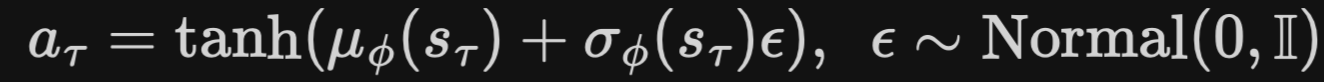
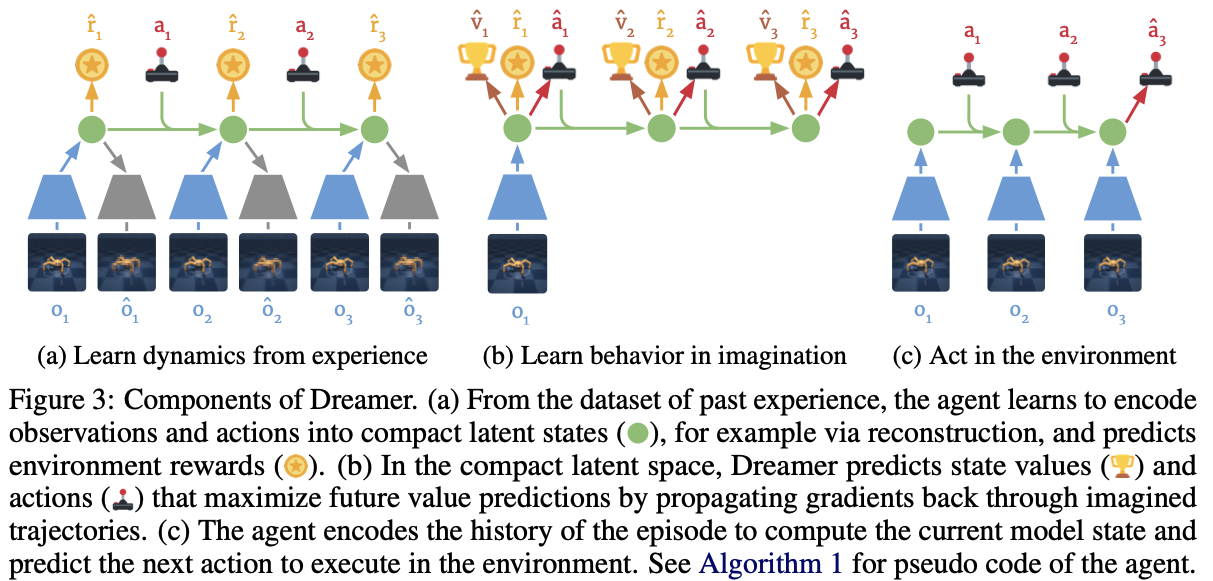
Introduction
- 지능형 에이전트는 내가 경험하지 않은 상황에 마주하더라도, 과거의 경험을 기반으로 세워진 모델을 기반으로, 새 환경에 적응할 수 있습니다.
- This ability requires building representations of the world from past experience that enable generalization to novel situations.
- 세계 모델은 미래에 대한 예측을 할 수 있습니다.
- 이미지 공간에서의 예측과 비교할 때, 잠재 상태는 작은 메모리 공간을 가지며, 이는 병렬적으로 수천 개의 궤적을 상상하는 것을 가능하게 합니다.
- 효과적인 잠재 동역학 모델을 학습하는 것은 딥러닝과
latent dynamics models의 발전을 통해 가능해지고 있습니다. - 하지만, Planet과 같은 과거 방법들은 model error에 대한 강인성을 구현하기 위해,
derivative-free optimization에 의존하였지,neural network dynamics가 제공하는 해석적인 gradients를 이용하지 않았습니다.
- Dreamer의 새로운 액터 크리틱 알고리즘은 상상 지평선을 넘어서는 보상을 고려하면서 신경망 동역학을 효율적으로 활용합니다.
- 이를 위해, 우리는 학습된 latent space에서 상태 가치와 행동을 예측합니다.
- In comparison to actor critic algorithms that learn online or by experience replay,
world models can interpolate past experienceandoffer analytic gradients of multi-step returnsfor efficient policy optimization.
- 이 논문의 주요 기여는 다음과 같이 요약됩니다:
Learning long-horizon behaviors by latent imagination모델 기반 에이전트는 유한한 상상 지평선을 사용할 경우 단기적일 수 있습니다.우리는 행동과 상태 가치를 모두 예측함으로써 이 제한을 해결합니다.- 잠재 공간에서 순전히 상상에 의해 학습하면, 잠재 동역학을 통해 분석적 가치 그래디언트를 역전파하여 정책을 효율적으로 학습할 수 있습니다.
Training purely by imagination in a latent space lets us efficiently learn the policy by propagating analytic value gradients back through the latent dynamics.
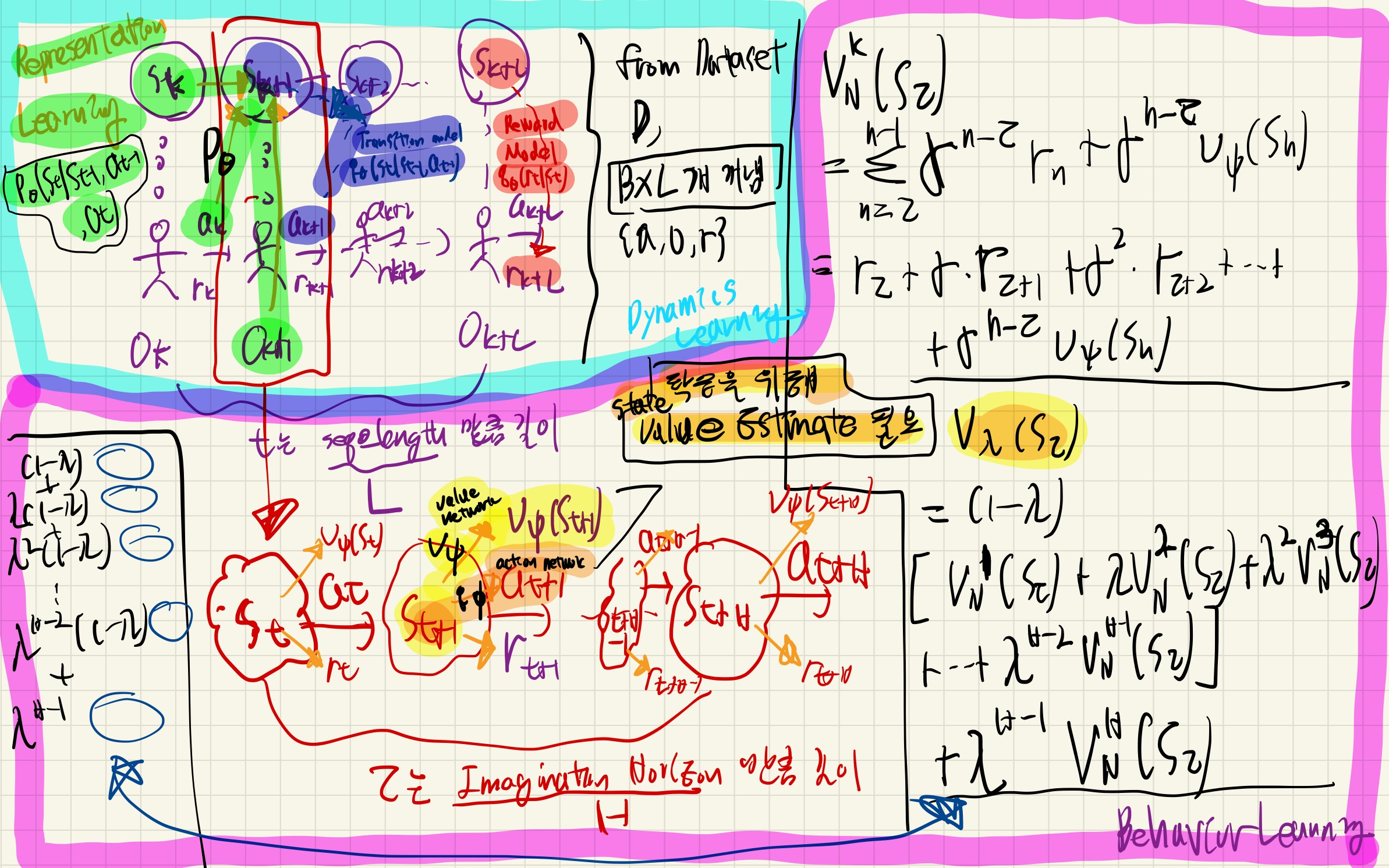
Method
Control with World Models
parameteric world model의 latent dynamics model은 아래 3가지로 구성
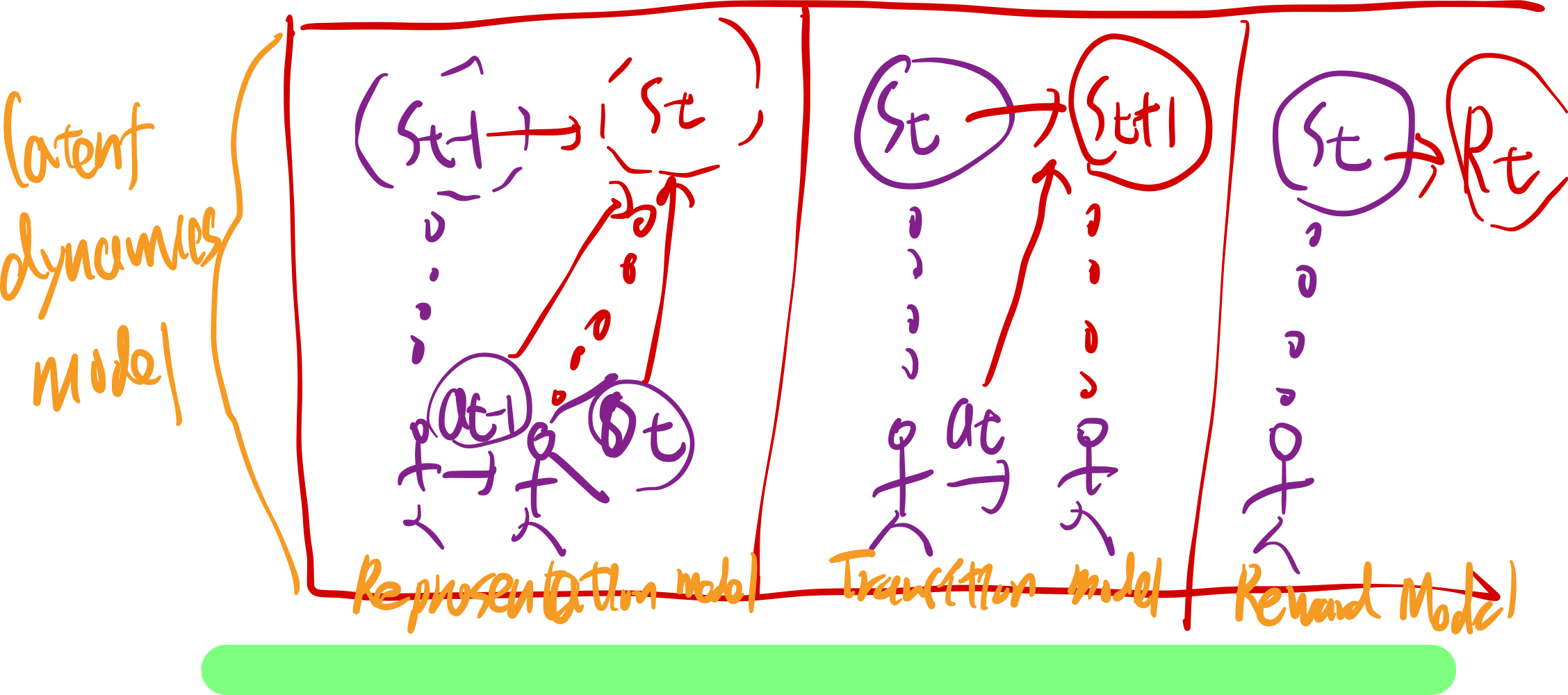
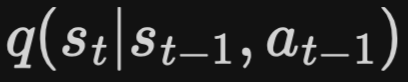
- Representation model

- planet의 variational encoder와 유사
- Transition model
- Reward model
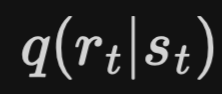
Learning Behaviors by Latent Imagenation
그 외 model
- action model
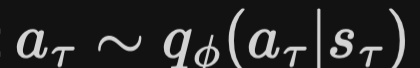
- objective function:
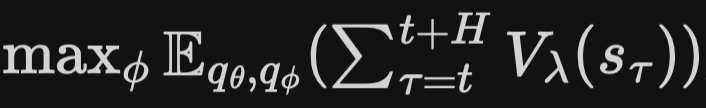 최대화
최대화
- value model
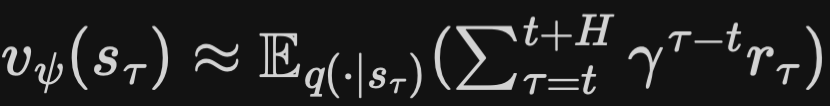
- objective function:
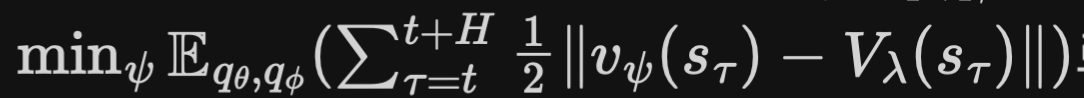
최소화
전체 방법론 소개

Dynamics Learning & Behavior Learning
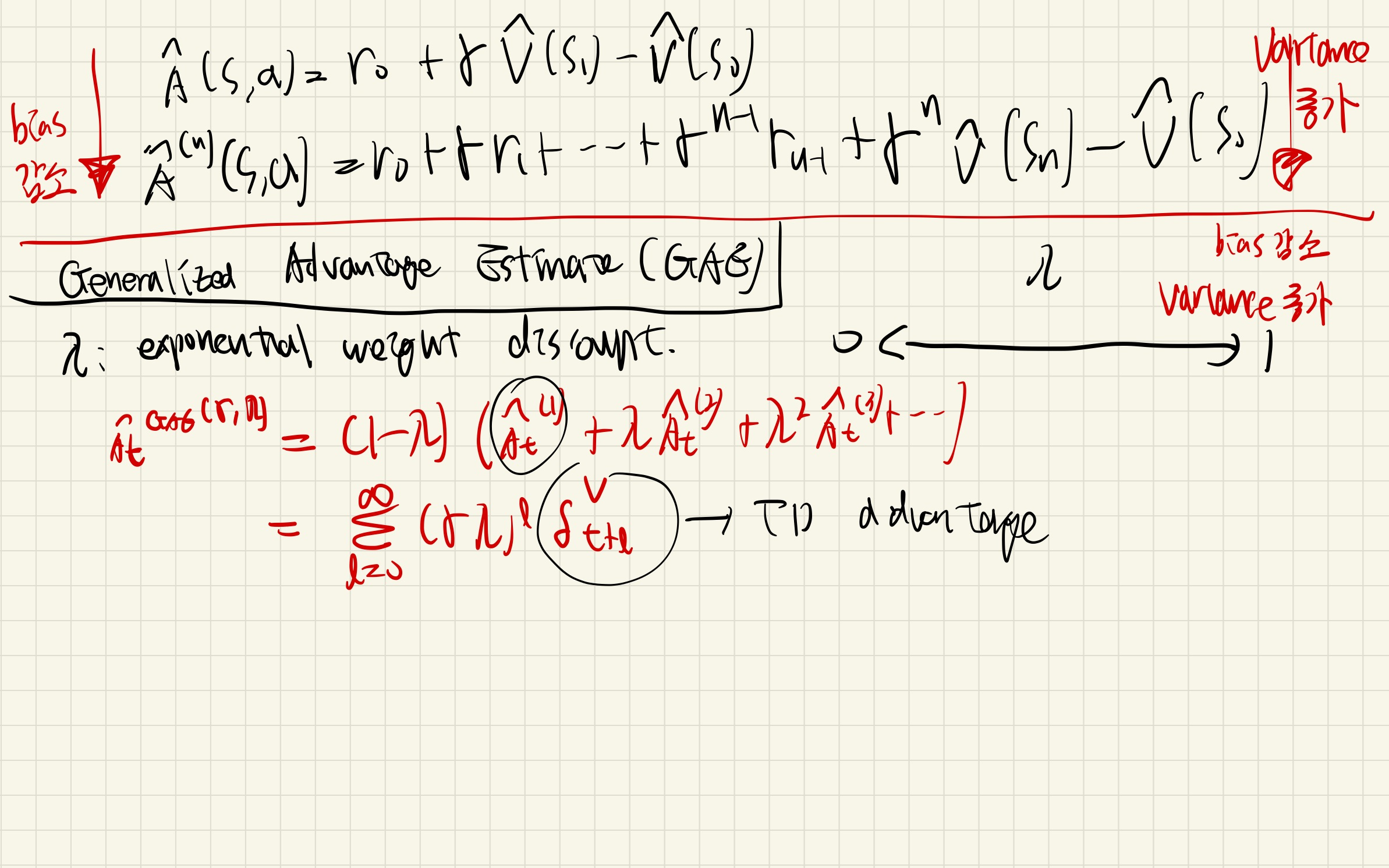
Environment Interaction
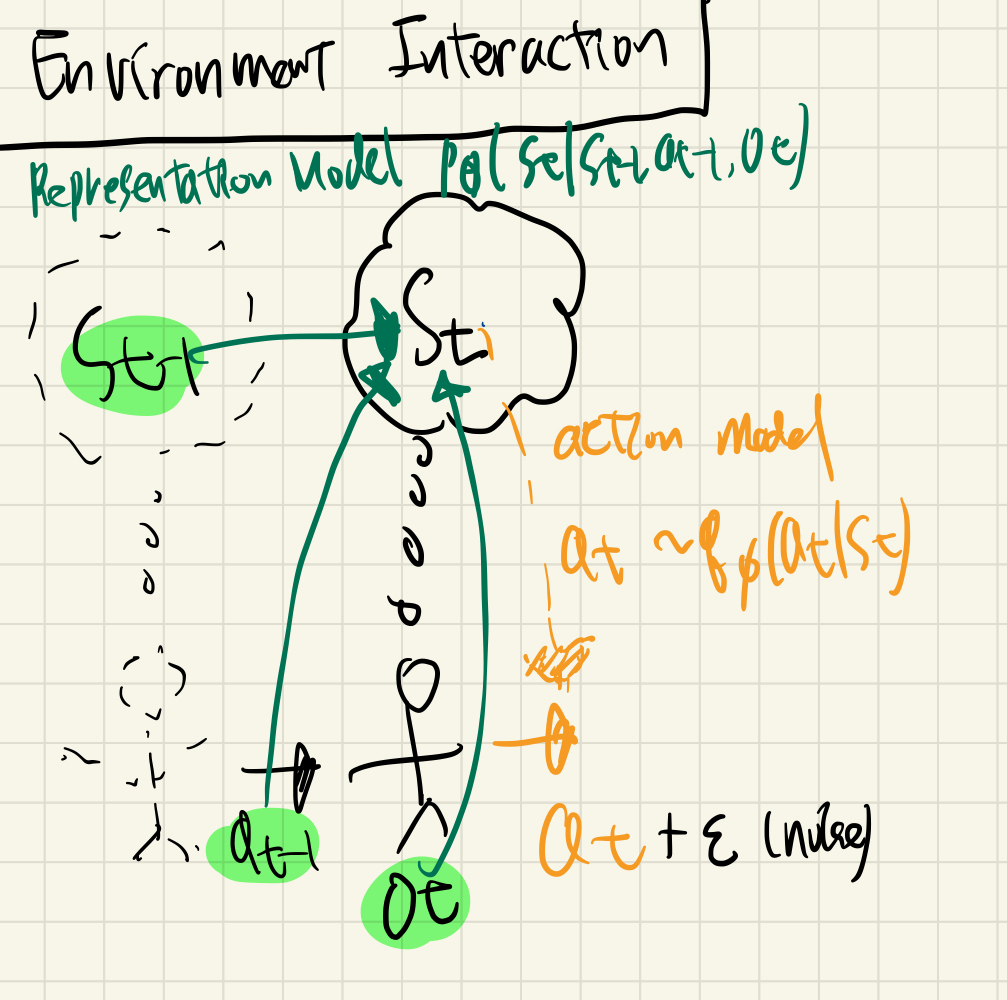

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.