SQL이 실행되는 과정
SQL과 옵티마이저에 대해 읽고 오자.
옵티마이저의 종류
옵티마이저는 규칙기반과 (Rule-Based Optimizer, RBO)와
비용기반 (Cost-Based Optimizer, CBO)로 나뉜다.
RBO는 미리 정해진 일정 규칙에 의거해 옵티마이징을 한다.
규칙들에는 우선순위가 있으며 상황에 따라 변동되지 않는다.
반면 CBO는 그때그때 비용을 일부 계산해서 가장 낮은 실행계획을 실행하도록 한다.
옵티마이저 모드
옵티마이저가 동작하는 모드는 5가지가 있다.
1. RULE
RBO 모드를 사용할 때 선택한다.
2. ALL_ROWS
쿼리 최종 결과집합을 끝까지 Fetch하는 것을 전제로
시스템 리소스를 가장 적게 사용하는 실행계획을 선택한다.
대부분의 DBMS에서는 이 전체 처리속도 최적화가 기본값이다.
3. FIRST_ROWS
앞의 n개 row만 본다는 가정하에 최초 응답속도를 최적화한다.
이렇게 했는데 막상 사용자가 다 fetch 한다면 더 많은 리소스를 사용하고 속도도 느려질 수 있다.
다만 SQL에 DML 문장을 사용하거나 SELECT에 집합 연산, for update가 있을 경우에
이게 일부 데이터만 가공할 수 없다보니 자동적으로 ALL_ROWS로 작동한다.
FIRST_ROWS는 비용과 규칙을 혼합한 형태의 옵티마이저 모드다.
얼마만큼을 Fetch 할 지 지정하지 않았으므로 정확한 비용을 예측할 수가 없고,
따라서 옵티마이저는 내부적으로 정해진 규칙을 사용한다.
4. FIRST_ROWS_N
FIRST_ROWS와 비슷하게, 첫 N개 로우만 반환하는 것을 전제로 했을 때 가장 빠른 응답 속도를 낼 수 있는 실행 계획을 선택한다.
세션에서 옵티마이저 모드를 변경할 때는 1, 10, 100, 1000개의 다른 모드를 쓸 수 있다.
alter session set optimizer_mode = first_rows_100;
select 에서 힌트를 쓰면 파라미터를 이용하여 정밀하게 조정할 수 있다.
select /*+ first_rows(100 */ * from t where ...;
FIRST_ROWS_N은 FIRST_ROWS와 다르게 완전히 CBO로 동작한다.
FIRST_ROWS가 RBO로 동작하는 이유는 얼마만큼을 Fetch 할 지 지정하지 않았으므로
정확한 비용을 예측할 수가 없기 때문에 일반적인 상황을 가정한 규칙을 사용하기 때문이다.
FIRST_ROWS_N은 반환할 로우의 수가 정해져 있기 때문에 칼럼 히스토그램 등을 이용해 충분히 비용을 예측할 수 있다.
5. CHOOSE
액세스하는 테이블 중 적어도 하나에 통계정보가 있다면 ALL_ROWS,
어느 테이블에도 없으면 RBO를 선택한다.
10g 버전부터는 RBO를 지원하지 않게 때문에, all_rows가 기본으로 설정되어 있다.
통계정보가 없는 테이블은 동적 샘플링이 일어난다.
동적 샘플링: 힌트는 통계정보가 존재하지 않은 Table에 대한 정확한 selectivity와 cardinality의 추정치를 결정하여 성능을 향상시키는 기능.
ALL_ROWS와 FIRST_ROWS의 차이
앞서 말했듯, ALL_ROWS와 FIRST_ROWS의 최적화 방법은 다르다.
사용자가 몇 개를 원할 지에 따라 최적화 방식이 달라지기 때문이다.
예를 들어 칼럼이 a, b, c, d ...가 있는 테이블 A에서 a, b가 인덱스일 때
select * from A where c >= 5000 order by a, b;의 결과는 전체를 반환할 것이냐 일부만 반환할 것이냐에 따라 다르다.
먼저 전체 결과를 본다는 가정 하에(일반적인 경우),
a가 테이블의 유일한 칼럼이라면 order by a로 정렬했을 때 index full scan 이 항상 좋은 선택이다.
하지만 그렇지 않을 경우 테이블의 상황에 따라 달라진다.
TABLE FULL SCAN 하고 나서 Sort operation을 하는 실행계획과
INDEX FULL SCAN 으로 ROW id 를 하나하나 접근하는 실행계획의 비용 차이를 계산한 뒤
둘 중 비용이 낮은 계획으로 진행한다.
TABLE FULL SCAN을 하면 Sort를 해야하지만(순서에 상관 없이 전체 스캔하므로)
Multiblock I/O를 진행할 수 있어 버퍼에 빨리 올릴 수 있고
INDEX FULL SCAN을 하면 Sort를 안 해도 되지만 Single Block I/O로 인한 속도 감소가 있다.
그래서 비용이 DB 버전이나 특정 상황에 따라 달라지며 비용을 따져봐야 한다.
아무튼, 전체 결과가 필요하다고 가정하면 둘을 비교하는 CBO로 동작할 수가 있다.
반면 FIRST_ROW의 경우 앞서 말했듯 몇 개를 볼 지 모르기 때문에 RBO로 동작할 수 밖에 없다.
전체를 다 보지 않고 앞의 일부만 본다면, 정렬보단 index로 몇 개 row만 접근해서 보는 게 더 나을 것이다. (인덱스는 이미 정렬이 되어 있기 때문에)
그래서 first_row 로 같은 쿼리를 날리면 무조건 INDEX FULL SCAN으로 동작한다.
설상가상 예시의 쿼리 같이 c >= 5000 같은 조건을 걸게 된다면 인덱스로 일일히 접근하면서 sal >= 5000인 부분을 찾는... => 최악의 경우 거의 전체를 찾게 되는 문제가 발생할 수 있다.
c의 분포가 아주 균등하게 되어 있다면, 내가 처음 10개를 보든 100개를 보든 테이블 전체를 스캔해야 하는 건 변하지가 않는다.
그래서 이 c가 5000인 row가 앞쪽에 몰려있거나, 사용자가 정말 소량의 결과만 필요하면서 ArraySize가 작을 때 이점이 있을 것이다.
자세한 것은 오라클 커뮤니티에 올라온 게시글을 참조하라.
옵티마이저에 영향을 미치는 요소
- SQL과 연산자 형태
- 인덱스, IOT, 클러스터링, 파티셔닝, MV 등 옵티마이징 팩터
- 제약 (PK, FK, Not Null, Check)
- 옵티마이저 힌트
- 통계 정보
- 옵티마이저 관련 파라미터
- 버전
옵티마이저의 한계
- 옵티마이징 팩터의 부족
- 통계정보의 부정확성 및 히스토그램의 한계
- 바인드 변수 사용 시 균등분포 가정
- 결합 선택도 산정의 어려움
- 규칙에 의존하는 CBO
- 하드웨어 성능
통계정보를 이용한 비용계산 원리
CBO는 실행계획 계산을 위해 아래의 통계 정보를 계산한다.
| 통계 유형 | 세부 통계 항목 |
|---|---|
| 테이블 통계 | 전체 레코드 수, 총 블록 수, 빈 블록 수, 한 행당 평균 크기 등 |
| 인덱스 통계 | 인덱스 높이, 리프 블록 수, 클러스터링 팩터, 인덱스 레코드 수 등 |
| 칼럼 통계 | 값의 수, 최저 값, 최고 값, 밀도, null값 개수, 칼럼 히스토그램 등 |
| 시스템 통계 | CPU 속도, 평균 I/O 속도, 초당 I/O 처리량 등 |
선택도
선택도 (Selectivity)는 테이블의 전체 로우 수 대비 쿼리가 선택될 것으로 예상되는 로우의 수의 비율이다.
부등호(=) 조건으로 찾는다면 선택도는 칼럼의 distinct value(구분되는 개수) 분의 1이다.
예를 들어 어떤 칼럼이 값이 100가지가 있는데 그 칼럼에 대해 특정 값을 찾고자 한다면 선택도는 1/100이다.
범위로 검색한다면 조건절에서 요청한 값 범위 / 전체 값 범위이다.
단 위의 식은 히스토그램이 없거나, 도수분포 히스토그램을 사용한 경우이다.
카디날러티
카디날러티 (Cardinality) 는 쿼리의 결과로 출력될 것으로 예상되는 로우의 수이며,
이는 테이블 전체 로우 수 * 선택도와 같다.
예를 들어 select * from 사원 where 부서 = :부서라는 쿼리가 있고
각 부서가 10개로 구분된다고 할 때 (Distinct Value)
선택도는 0.1이고 (1/10) 전체 로우가 1000개라고 하면 카디날러티는 100이 된다. (1000 * 1/10)
select * from 사원 where 부서 = :부서 and 직급 = :직급;
직급의 도메인이 {부장, 과장, 대리, 사원}이면
Distinct Value 개수가 4이므로 선택도는 0.25(=1/4)다.
따라서 위 쿼리의 카디널리티는 25(=1000 × 0.1 × 0.25)로 계산된다.
선택도는 불특정 로우가 조건을 만족할 확률이라고 할 수 있다.
히스토그램
미리 저장된 히스토그램 정보가 있으면, 옵티마이저는 그것을 사용해 더 정확하게 카디널리티를 구할 수 있다.
특히, 분포가 균일하지 않은 칼럼으로 조회할 때 효과를 발휘한다.
히스토그램의 유형
- 도수분포 히스토그램
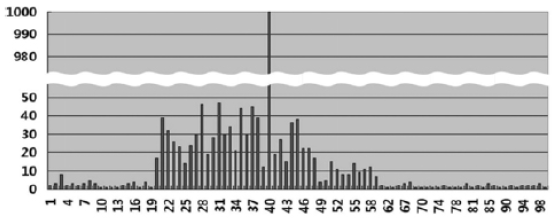
칼럼이 가진 값의 종류 수가 적을 때 사용되며 값마다 하나의 버킷을 할당할 수 있다.
- 높이균형 히스토그램
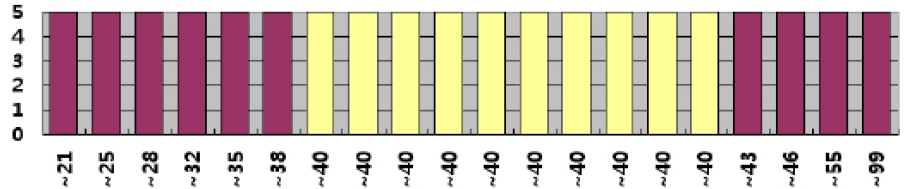
칼럼이 가진 값의 종류가 너무 많아서 값에다 일일히 버킷을 할당할 수 없을 때 사용한다.
오라클은 버킷의 수를 254개까지 할당할 수 있다.
이 때는 레코드 수 / 할당 가능한 버킷 수만큼 잘라서 버킷에 담아 보관하는데, 이를 빈도수라고 한다.
높이균형 히스토그램에선 말 그대로 각 버킷의 높이가 같다.
대신, 빈도 수가 많은 값에 대해서는 두 개 이상의 버킷이 할당되기 때문에,
특정 값으로 대표되는 버킷의 수가 많아질 수 있다.
칼럼 개수의 높이 대신 이 버킷의 개수의 비중으로 통계를 낸다.
예시는 나이라는 칼럼을 높이균형 히스토그램으로 나타낸 것이다.
값의 수는 89개이며 (89개의 다른 나이가 있다는 뜻)
총 레코드 수는 2000개이다.
여기에 20개의 버킷을 할당하면 89보다 작으므로 자동으로 높이균형 히스토그램을 사용할 수 있다.
예시에선 한 버킷의 빈도수는 (레코드 수 = 2000) / (할당 버킷 수 = 20) = 100, 즉 버킷 하나에 100개가 들어가게 된다.
칼럼이 가지는 값들을 정렬해서 앞에서부터 100개씩 잘라서 버킷에 담을 수 있는 것이다.
그리고 그 최대값이 그 버킷을 대표하게 된다.
버킷 하나가 차지하는 분포는 (1 / 버킷 수) * 100이다.
예시에선 (1/20) * 100 = 5%이다.
높이균형 히스토그램에는 ENDPOINT_NUMBER와 ENDPOINT_VALUE가 존재하는데
각각 버킷 번호와 버킷이 담당하는 가장 큰 값을 의미한다.
ENDPOINT_NUMBER가 0인 경우엔 ENDPOINT_VALUE는 칼럼의 최소값을 의미한다.
즉 버킷 번호는 1번부터 매겨진다고 할 수 있다.
다음은 위 테이블의 ENDPOINT_NUMBER와 ENDPOINT_VALUE이다.

ENDPOINT_NUMBER가 6에서 16으로 건너뛴 이유는 Popular Value (버킷이 두 개 이상인 값)를 압축했기 때문이다.
버킷 7부터 16까지 총 10개가 다 40으로 대표되는 버킷들이기 때문에 굳이 7, 8, ... 16까지 반복해서 적지 않아도 된다.
이 예시에선 나머지 버킷들은 다 1개 씩, 각 버킷에는 값이 100개 씩 할당이 됐고,
popular value인 40살만 10개, 총 1000개가 할당이 됐다.
popular value 인 경우 선택도는 (조건절 값의 버킷 개수) / (총 버킷 개수)이다.
나이가 39, 40살인 조건을 걸어서 찾으려고 하면 선택도는 10/20 = 0.5이다.
카디날러티는 1000일 것이다.
40살이 아닌 non popular value의 경우에는 선택도는 density라고 따로 부르는 값을 사용한다.
null이 아닌 총 레코드 수 = , 모든 non popular value의 빈도수 = 라고 할 때
density는 이다.
바인드 변수를 사용하는 경우
바인드 변수의 부작용에서도 말했듯 바인드 변수를 사용하면 히스토그램을 사용하지 못한다.
변수 바인딩은 최적화가 끝나고 나서 가장 최소의 비용이 들 것이라 예상되는 실행계획이 라이브러리 캐시에 적재가 된 다음 이를 변수만 바꿔서 재활용하는 것이기 때문에,
바인딩 된 쿼리에 대해 칼럼의 데이터 분포를 활용하지 못한다.
또한 실행계획들의 비용을 산출하는 것은 파싱이 일어난 후이다.
히스토그램이 만들어져 있더라도 쿼리에서 어떤 값으로 조건을 걸지 모른다면,
그걸 통해 선택도와 카디날러티를 계산할 수 없다.
그래서 바인딩 변수가 있을 때는 비용을 위해 선택도를 계산할 때 칼럼의 분포 자료를 이용하는 대신
평균적인 분포 자료를 따르고, 연산자에 따라 정해진 규칙을 따르게 된다.
비용
테이블 액세스 방법에 따라 비용이 다르게 산출된다.
아래는 I/O call 만 계산한다. (tree에서 대소를 비교하는 CPU 비용은 고려하지 않는다.)
인덱스를 경유하는 경우
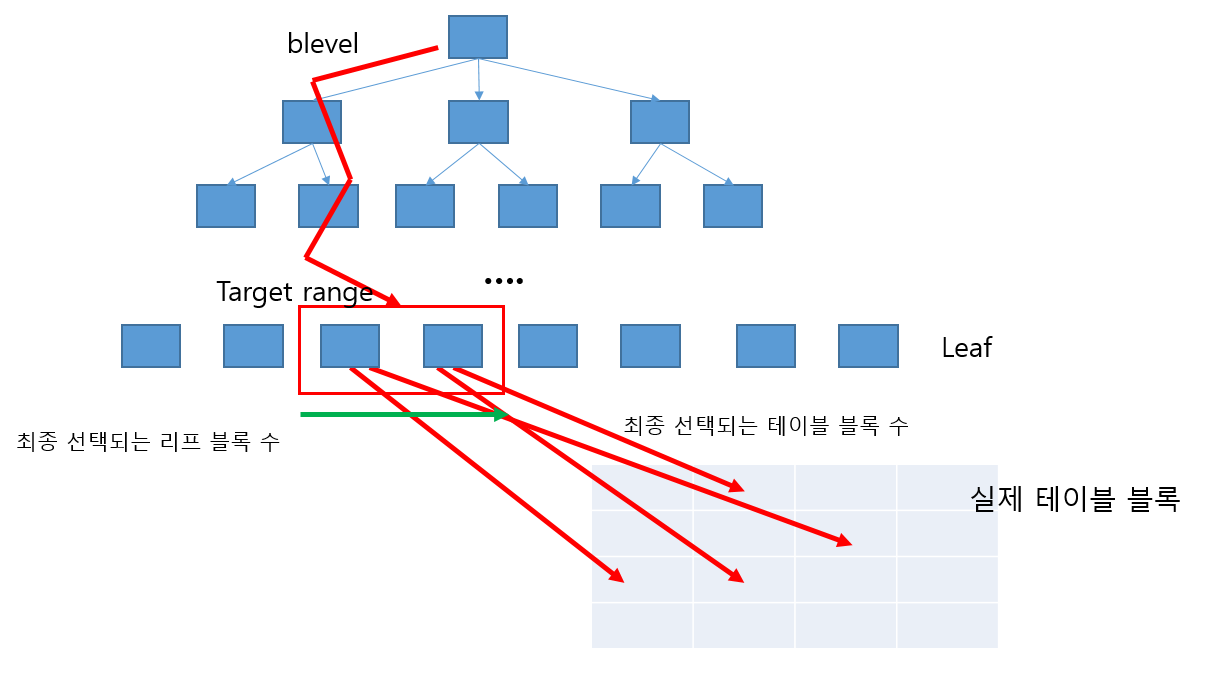
위 그림은 b+tree로 index range scan 을 했을 경우를 나타낸다.
blevel은 tree의 높이 (leaf까지의 branch 수)이다.
리프까지 몇 개의 인덱스 블록을 방문했는지(= 리프 블록 읽기를 위한 I/O call)를 나타낸다.
그 다음, 리프 블록들을 선택해야 한다.
DBMS가 최종적으로 읽어야 할 것으로 예상되는 리프 블록의 수는
전체 리프 블록 수 * 유효 인덱스 선택도 (= 전체 인덱스 레코드 중 조건절 범위 안에 들어갈 확률)이다.
인덱스 레코드는 대상 칼럼값의 범위를 각각 담고 있다.
어떤 칼럼값이 최소 1, 최대 100을 갖는다고 할 때 인덱스 레코드는
1~50, 51~100, 1~25, 26~50 등 다양할 것이다.
이중 어떤 조건절에 맞는 범위의 수의 비율(= 전체 대비 내가 방문할 것으로 예상되는 인덱스 로우의 비율 = 유효 인덱스 선택도)이 20%라고 하자.
그렇게 되면 해당 20%으로 접근한 리프 블록이 있고
나머지 80%로 접근 가능한 리프 블록들이 있다.
즉, 전체 리프 블록 중 20%는 내가 접근할 것으로 예상된다.
그래서, 내가 읽을 것으로 예상되는 리프 블록의 수는
리프 블록 수 * 유효 인덱스 선택도이다.
리프 블록에 도달했으면, 그 주소로 가서 블록을 읽어들여야 한다.
이때 그 주소들이 한 블록 안에 있다면 좋겠지만 아니게 될 수도 있다.
좋다면 클러스터링이 잘 돼있는 것이고 아니면 여러 블록을 각각 읽어야 할 것이다.
index full scan 했을 때 읽게 되는 블록의 수를 클러스터링 팩터라고 한다.
유효 테이블 선택도 (= 전체 로우 중 조건절 범위에 걸릴 확률) * 클러스터링 팩터는
조건절 범위에 해당하는 로우가 위치해있는 블록의 수와 같다.
따라서 리프 블록에서 테이블에 접근했을 때 읽어야 할 것으로 예상되는 테이블 블록의 수는
클러스터링 팩터 * 유효 테이블 선택도이다.
결론적으로 인덱스에서 sequential하게 테이블에 접근한다고 할 때의 비용은
blevel + (리프 블록 수 * 유효 인덱스 선택도) + (클러스터링 팩터 * 유효 테이블 선택도)이다.
Full Scan 의 경우
Full scan 은 Multiblock I/O 방식으로 동작한다.
(정확하진 않지만) 전체 블록 수를 Multiblock I/O 단위로 나눈 만큼의 비용이 발생한다.
Multiblock I/O 단위는 db_file_multiblock_read_count 파라미터로 조절할 수 있다.
이 값이 커질 수록 Full Scan 시 비용이 줄어든다.
힌트
옵티마이저에도 한계가 있어 제대로 된 판단을 못할 때도 있다.
특히 데이터에 대한 분포를 정확히 계산을 못할 때가 많다.
조건들이 결합되면 조건들의 선택도를 단순히 곱하기만 한다.
하지만 현실적으로 각 조건들은 조건부 확률일 수도 있어 마냥 곱하기만 해선 정확한 선택도를 얻을 수가 없다.
혹은 바인딩 변수를 쓰면서 칼럼 통계를 활용하지 못하거나,
바인딩 변수를 사용하게 되면 선택도를 알 수가 없어 규칙 기반으로 선택도를 계산하며,
first_rows 힌트를 사용하면 index scan을 하게 된다.
조건절의 인덱스 접근 비용이 같으면 알파벳 순으로 동작하는 등
특정 경우 옵티마이저가 규칙 기반으로 동작할 수도 있다.
따라서 데이터의 실제 분포나 특성을 제대로 아는 개발자가 직접 인덱스를 지정하거나
(개발자가 보기 편하게) subquery를 썼지만 풀어서 조인하는 게 나은 경우 조인 방식을 변경하는 등
옵티마이저에게 힌트를 주어 더 좋은 실행계획으로 인도할 수 있다.
다만, 문법적으로나(syntatic) 의미적으로(semantic) 틀리다면 무시된다.
힌트 구문이나 상황에 오류가 없으면 옵티마이저는 무조건 실행된다.
예를 들어 내가 힌트로 지정된 인덱스가 이미 삭제된 것이라면,
SQL에선 에러가 나고 오라클에서는 다른 인덱스로 대체하거나 자체적으로 Full Table Scan으로 변경한다.
힌트 종류
| 분류 | 힌트 |
|---|---|
| 최적화 목표 | all_rows - 처리시간 (throughput) 우선 first_rows(n) - 최초응답시간 우선 |
| 액세스 경로 | full(a) - table full scan해라. 괄호에 서브쿼리 블록이나 테이블이 지정되어 있으면 (qb_name 참조) 그것만 full scan 한다 cluster - 인덱스 클러스터 테이블 지정 hash - 해시 클러스터 테이블 지정 index(테이블, 인덱스 이름) - 해당 테이블의 인덱스로 접근 no_index(테이블, *인덱스) - 그 테이블의 그 인덱스 쓰지 마라 (그 테이블의 인덱스는 다 쓰지 마라) index_asc(테이블, 인덱스 이름), index_desc - 인덱스로 오름차순/내림차순 접근 index_combine - 비트맵 인덱스에서 인덱스 결합하라 index_join - 인덱스 조인 유도 index_ffs, no_index_ffs - index fast full scan 관련 index_ss, no_index_ss - index skip scan 관련 index_ss_asc, index_ss_desc - index skip scan 오름차순/내림차순 |
| 쿼리 변환 | no_query_transformation - 쿼리 변환 하지마라 use_concat, no_expand - or 을 union-all로 바꿔라/바꾸지 마라 rewrite, no_rewrite merge, no_merge 뷰 머지 해라/하지 마라 star_transformation, no_star_transformation fact, no_fact unnest, no_unnest |
| 조인 순서 | ordered - from 절에 등장하는 순서대로 NL조인하라 leading - (a b c d ...) from 절에 테이블이 기술된 순서를 무시하고, a b c d 순서로 조인해라(먼저 온 게 inner) 둘은 당연하게도, 둘은 같이 쓰일 수가 없다 |
| 조인 방식 | use_nl(a), no_use_nl - a를 inner로 해서 NL Join 해라/하지 마라 use_nl_with_index - 지정된 index로 NL조인해라 use_merge, no_use_merge - 소트 머지 조인해라/하지 마라 use_hash(a b), no_use_hash - a를 build input, b를 probe input으로 해서 해시 조인 해라/하지 마라 hash_aj, hash_sj, merge_aj, merge_sj - 안티 조인/세미 조인 |
| 병렬 처리 | parallel(스레드 수), no_parallel - 병렬처리 해라/하지 마라 pq_distribute - 참조 parallel_index(테이블, 인덱스명), no_parallel_index - 인덱스 범위 스캔으로 병렬처리 해라 |
| 기타 | append, noappend - Direct Path Loading 해라/하지 마라 cache, nocache Full scan으로 읽은 블록들을 LRU의 맨 앞에서 넣어라/맨 뒤에 넣어라(full scan) push_pred, no_push_prd - 조건절 pushdown 해라/하지 마라 push_subq, no_push_subq - 서브쿼리부터 수행해라/메인쿼리부터 수행해라 (no_unnest랑 같이 쓰이며, 서브쿼리 절에 힌트를 쓴다.) qb_name(sth) 쿼리 블록에서, 해당 블록의 이름을 sth로 지정한다. cursor_sharing_exact driving_site dynamic_sampling model_min_analysis |
