인덱스에는 B+Tree, Hash, 비트맵, 함수 등의 여러가지 종류가 있다.
B+Tree 인덱스
인덱스 구조로 자주 사용되는 B+Tree의 B는 Balanced로, 루트부터 리프까지의 거리가 모든 경로에서 동일하다. 루트로부터 모든 리프까지의 Height가 같다.
하지만 이 균형은 어디까지나 리프까지의 이야기로, 리프에서 불균형이 일어날 수도 있다.
인덱스 스캔 종류
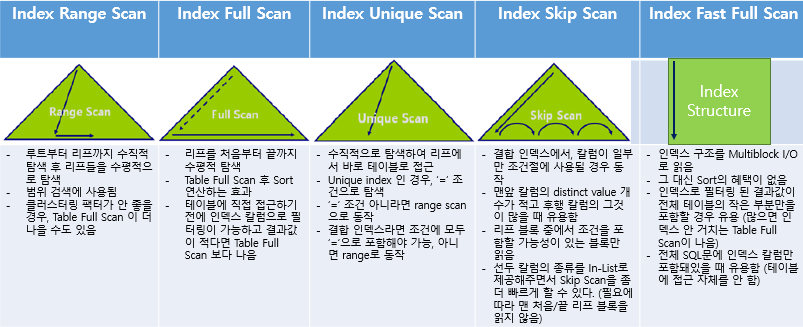
인덱스는 테이블과 같이 세그먼트 단위로 존재한다.
인덱스는 테이블의 Skinny 한 버전으로, 테이블의 row(s)를 포함하는 블록은 너무 크기 때문에 한 번 거쳐가는 단계로서 존재한다.
인덱스도 블록 단위로 존재하기 때문에 인덱스를 거치는 개수도 중요하긴 하다.
인덱스 전체를 Multiblock으로 스캔해버리는 Index Fast Full Scan이 아니라면, 다른 scan들에서 수직이든 수평이든 모두 single block I/O로 동작한다.
다만 크기가 작아서인지 이에 대해선 언급이 잘 없다.
SQL문에 인덱스 칼럼만 포함되어 있으면 테이블에 접근조차 안 해도 된다.
Index range scan을 할 것인지, Index Full Scan을 할 것인지 Fast full scan을 할 것인지, 아니면 table full scan을 할 것인지 정하는 것은
'필요한 결과의 row 수/필요없는데 보게 되는 row의 수'의 비율로 결정되는 것 같다.
Index Skew
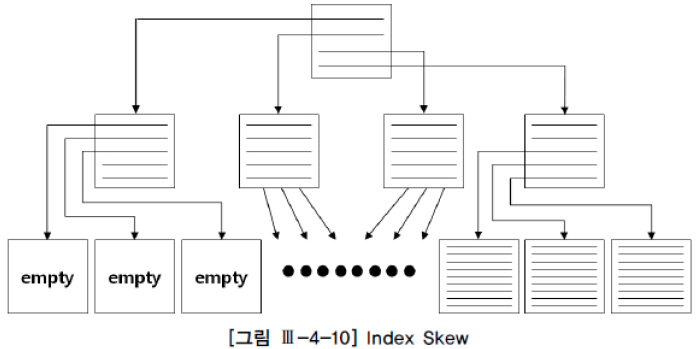
왼쪽 리프에 있는 row들을 죄다 제거해버려서 생기는 현상이다.
만약에 사원 테이블이 나이로 인덱싱 되어 있다면 정년퇴직을 한 경우 65세 이상이 다 삭제되므로 저렇게 될 수 있다.
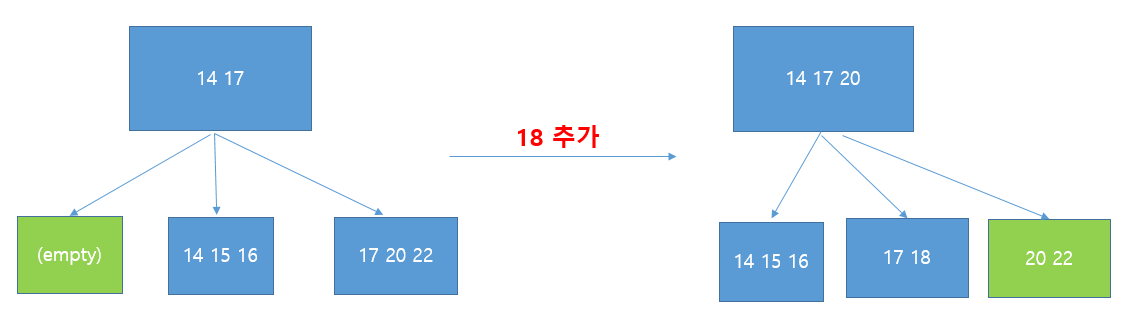
오라클의 경우 텅 빈 인덱스 블록은 커밋할 때 freelist로 반환되지만 구조 상엔 그대로 남는다.
데이터를 추가해서 다른 노드에서 인덱스 분할이 발생할 때 이 빈 블록이 재사용된다.
예를 들어 위 사진의 왼쪽과 같은 인덱스 구조가 있고 리프 노드의 최대 key값이 3개라고 하자.
이때 18이라는 데이터를 추가하면 맨 오른쪽의 '17 20 22' 리프 블록이 '17 18 20 22'와 같은 꼴을 갖고, 리프 블록의 최대치를 넘었으므로 분할이 일어나 우측과 같은 모습이 된다.
아까 비어있던 리프 블록을 가리키는 엔트리가 제거되고 다른 쪽 브랜치의 자식 노드로 이동하며, freelist에서 제외된다.
(freelist: 가용 블록을 리스트 형태로 관리하는 자료구조)
Index Sparse
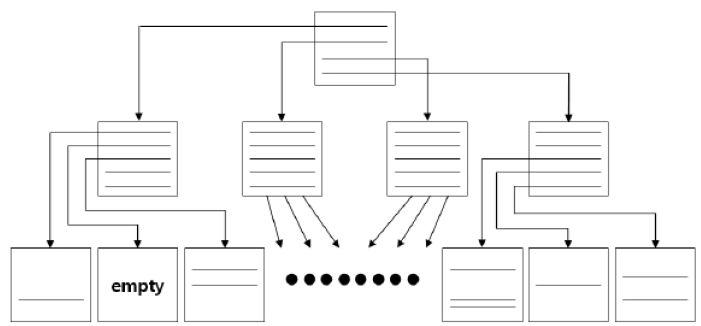
index sparse는 index skew처럼 블록이 아예 비어서 재활용도 못하고 이도저도 아닌 상태로 밀도만 낮아진 형태를 의미한다.
인덱스 재생성
인덱스를 쓰다보면 블록도 다 차고 하면서 DML 칠 때마다 인덱스 분할이 자주 발생해서 성능이 안 좋아질 수 있다.
그래서 적당한 시점마다 재생성 작업을 해줘야 한다. 다만 재생성도 시간이 걸리므로 했을 때 성능이 좋아질 거란 확신이 있을 때만 수행해야 한다.
그럴 때는 다음과 같다.
- 인덱스 분할에 의한 경합이 현저히 높을 때
- 자주 사용되는 인덱스 스캔 효율을 높이고자 할 때
특히 NL Join에서 자주 사용되는 인덱스 높이가 증가했을 경우 - 대량의 delete 작업을 수행한 이후, 다시 레코드가 입력되기까지 오랜 기간이 소요될 때
- 레코드 수가 일정한데도 인덱스가 계속 커질 때
비트맵 인덱스
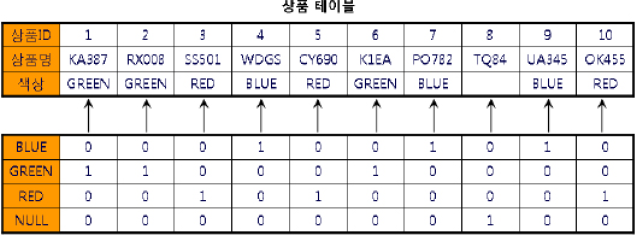
one hot encoding 된 값을 저장한다.
저장 효율도 좋고 비트 연산도 가능해서 검색 성능이 좋다.
다만 NDV(Number of Distinct Value)가 너무 크면 안 좋다.
또한 레코드 하나만 변경돼도 비트맵 범위에 속한 모든 레코드에 Lock이 걸린다는 단점이 있다.
OLTP보다는 읽기 위주의 DW(특히 OLAP) 환경에 적합하다.
함수 기반 인덱스
대소문자 구분 없이 이름을 검색하려 할 때 where upper(name) = 'JAKE' 와 같은 조건을 걸고, 주문수량이 null인 것을 0으로 치고 100 미만인 건들을 검색하려 할 땐 where nvl(주문수량, 0) < 100을 쓸 수 있다.
하지만 칼럼을 가공하면 인덱스를 사용할 수가 없다.
이럴 때 함수 기반 인덱스(Function Based Index)를 사용할 수 있다.
칼럼 값 자체가 아니라, 칼럼에 특정 함수를 적용한 값으로 B+Tree 인덱스를 만드는 방식이다.
예를 들어
create index emp_x01 on emp(nvl(주문수량, 0)); 과 같이 인덱스를 생성하면, 주문수량이 Null인 레코드는 인덱스에 0으로 저장된다.
다만 이렇게 하면 DML 칠 때마다 함수를 적용하기 때문에 다소 부하가 있을 수 있으며 특히 사용자 정의 함수일 경우엔 부하가 더 심하다.
꼭 필요할 때만 써야한다.
리버스 키 인덱스
일련번호나 주문일시 같이 순차적으로 증가하는 칼럼에 인덱스를 만들면 인덱스의 오른쪽 리프에만 데이터가 쌓일 수 있다.
이를 Right growing 혹은 Right hand 인덱스라고 부른다.
한 시점에 insert가 심하면 인덱스 블록 경합을 일으켜 초당 트랜잭션 처리량을 감소시킨다.
이럴 때 추가할 때마다 입력된 키 값을 reverse 시켜서 넣어주면 골고루 들어가게 할 수 있다.
create index 주문_x01 on 주문(reverse(주문일시)); 과 같은 함수 기반 인덱스를 사용하면 된다.
201, 202, 203, 204, 205 를 집어넣으면 102, 202, 302, 402, 502가 되기 때문에 리프 블록 전체에 분산시키는 효과를 기대할 수 있다.
클러스터 인덱스
클러스터 테이블, 그 중에서도 인덱스 클러스터 테이블은 하나의 키를 기준으로, 같은 키를 가지는 레코드끼리 한 블록에 모여있는 테이블이고 이때 그 키를 클러스터 인덱스라고 한다.
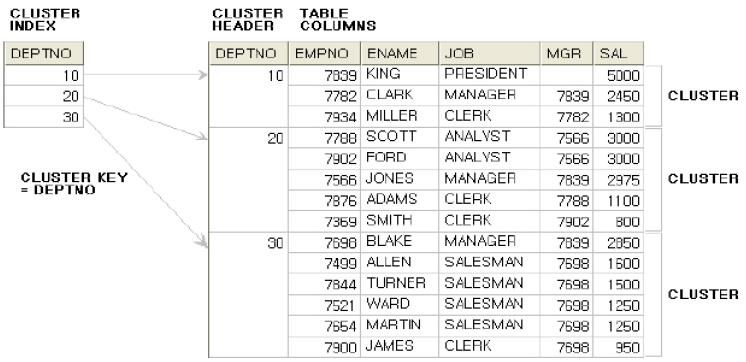
오라클에서 이를 구현하는 방법은 다음과 같다.
- 인덱스 클러스터를 만든다. (클러스터=모임을 정의한다.)
create cluster c_deptno ( deptno number(2) ) index ; - 각 클러스터의 키로 쓸 클러스터 인덱스를 만든다.
create index i_deptno on cluster c_deptno; - 테이블이 해당 클러스터를 사용하게 한다.
create table emp cluster c_deptno (deptno) as select * from scott.emp;
클러스터 인덱스도 일반적인 B+Tree를 사용하지만 해당 키 값을 저장하는 첫 번째 데이터 블록만을 가리킨다. (블록 안에서는 알아서 찾아야 함)
일반적인 인덱스는 리프 블록과 테이블 레코드가 1:1 관계를 가지지만 클러스터 인덱스의 리프는 테이블 블록과는 1:1이고 레코드와는 1:M이다.
그래서 클러스터 인덱스들을 스캔할 때는 Random Access가 키 값당 한 번씩만 발생하고, 그 이후 (블록 접근 후)부터는 Sequential Access가 가능하다.
따라서 넓은 범위를 검색할 때 유리하나, 클러스터 키가 자주 바뀔 때는 이 기능을 안 쓰는 게 좋다.
클러스터 키의 대상이 새로 생기면 새로 클러스터를 할당해줘야 되고, 키 값을 바꾸면 바꾼대로 클러스터 간 이동이 발생하기 때문이다.
인덱스 클러스터 테이블을 사용하면 클러스터링 팩터가 좋아진다.
클러스터'형' 인덱스
먼저, 클러스터 인덱스와 클러스터형 인덱스는 다르다.
클러스터 인덱스는 인덱스 클러스터 테이블에서 군집으로 묶는 인덱스 클러스터에 사용되는 인덱스이다.
클러스터형 인덱스(= Clustered Index)는 SQL Server에서 쓰는 용어로, 오라클에선 IOT(Index Organized Table)이라고 한다.
기존 인덱스를 사용할 때는 먼저 인덱스에 접근해서 내가 접근해야 할 레코드(rowid)를 필터링 하고, 그 다음 레코드를 접근했다.
즉 인덱스 오브젝트와 테이블 오브젝트가 따로 놀았다.
클러스터 인덱스는 그것보다는 테이블과 느슨하게 연결되어 있다. (클러스터 인덱스와 테이블 블록이 1:M이므로)
반면 클러스터형 인덱스/IOT는 인덱스와 테이블이 결합된 형태로, 인덱스에 따로 접근할 필요 없이 테이블이 정렬된 형태로 존재한다.
오라클의 IOT는 SQL Server의 클러스터형 인덱스와 달리, PK에만 생성할 수 있다는 차이가 있다.
아래부터는 IOT라는 명칭으로 통일한다.
IOT는 인위적으로 클러스터링 팩터를 좋게 만드는 방법 중 하나다.
처음부터 테이블이 100% 정렬된 채로 시작하기 때문에 Random access가 아닌 Sequential로 접근이 가능하고 넓은 범위를 액세스할 때 유리하다.
하지만 테이블 자체가 인덱스 구조로 만들어지기 때문에 데이터를 생성할 때 성능이 느리고 분할이 많이 발생하게 되는 경우가 있다.
또한 Direct Path Insert (버퍼 캐시 안 거치고 바로 Insert, /*+ append */로 사용가능)가 불가능한 단점이 있다.
IOT가 빛을 발하는 경우는 다음과 같다.
- 칼럼이 별로 없는 테이블
PK 이외에 많은 칼럼을 갖는다면 리프에 저장해야 될 데이터가 많아지고 분할 빈도가 많아진다. (여러 기준으로 정렬하므로) - NL 조인으로 반복 접근되는 테이블
IOT는 생성할 때는 안 좋을지언정 여러번 접근할 때는 좋다.
드라이빙하는 테이블의 레코드를 읽을 때마다 인덱스 테이블 인덱스 테이블 인덱스 테이블... 반복하는 것보다 낫다. - 넓은 범위를 주로 검색하는 테이블
주로 Between, like 같은 조건으로 넓은 범위를 검색하는 테이블이라면 좋다. - 데이터 입력과 조회 패턴이 다른 테이블
100명의 영업사원이 있는 회사의 사원-영업실적 테이블이 매일 추가되고, 한 블록에 100개 로우라고 하자.
1년이 지나서 각 사원별로 영업 통계를 뽑아보려고 하면, 사원별로 365개 블록을 봐야 한다.
데이터 입력은 전체 사원의 데이터가 일별로 이루어지는데 조회는 사원별로 이루어져서 발생하는 현상이다.
이럴 때 사원 기준으로 IOT를 생성하면 한 페이지만 읽어 처리할 수 있다.
