32. CBO(비용기반 옵티마이저)는 쿼리 최적화 과정에 비용(Cost)를 계산한다. 다음 중 비용(Cost)과 가장 거리가 먼 것은?
- 비용이란 기본적으로, SQL 수행 과정에 수반될 것으로 예상되는 I/O 일량을 계산한 것이다.
- 데이터베이스 Call 발생량도 옵티마이저의 중요한 비용 요소다.
- 옵티마이저가 비용을 계산할 때, CPU 속도, 디스크 I/O 속도 등도 고려할 수 있다.
- 최신 옵티마이저는 I/O에 CPU 연산 비용을 더해서 비용을 계산한다.
해설
SQL문을 작성할 때 call 발생량도 생각해야 할 요소이나 call 발생량은 옵티마이저가 최적의 실행계획을 찾아낸 후 이를 실제 실행할 때 발생하는 것이다. 즉 call 발생량은 옵티마이저가 고려하지 않는다.
33. 다음 중 규칙기반 옵티마이저(RBO)가 사용하는 규칙으로가장 부적절한 것은?
- 고객유형코드에 인덱스가 있으면, 아래 SQL에 인덱스를 사용한다. select * from 고객 where 고객유형코드 = 'CC0123'
- 고객명에 인덱스가 있으면, 아래 SQL에 인덱스를 사용해 order by 소트 연산을 대체한다.
select * from 고객 order by 고객명 - 연령과 연봉에 인덱스가 하나씩 있으면, 아래 SQL에 연봉 인덱스를 사용한다. between 조건(닫힌 조건)이 부등호 조건(열린 조건)보다 아무래도 스캔 범위가 작을 가능성이 높기 때문이다.
select * from 사원 where 연령〉= 60 and 연봉 between 3000 and 6000 - 직급에 인덱스가 있고, 직급의 종류 개수가 5개 이상이면 인덱스를 사용한다.
select * from 사원 where 직급 = '대리’
해설
규칙 기반은 칼럼 통계(여기서는 NDV - Number of Distinct Values)를 사용하지 않는다.
34. 다음 중 전체범위 최적화(ALL_ROWS) 방식의 옵티마이저 모드에 대한 설명 으로 가장 거리가 먼 것은?
- 쿼리의 최종 결과 집합을 끝까지 Fetch하는 것을 전제로, 시스템 리소 스를 가장 적게 사용하는 실행계획을 선택한다.
- 부분범위 최적화(FIRST_ROWS)와 비교할 때, Index Scan보다 Table Full Scan하는 실행계획을 더 많이 생성한다.
- DML 문장은 옵티마이저 모드와 상관없이 항상 전체범위 최적화 방식 으로 최적화된다.
- 가장 빠른 응답속도(Response Time)를 목표로 한다.
해설
전체범위 최적화는 빠른 Response Time보다 Throughput(처리량) 중심으로 최적화를 시행한다.
35. 다음 중 비용기반 옵티마이저(Cost-Based Optinizer)가 사용하는 비용 계산식으로 가장 적절한 것을 2개 고르시오. (NDV = Number Of Distinct Value)
- 선택도(Selectivity) = 1 / NDV
- 선택도(Selectivity) = NDV / 총 로우 수
- 카디널리티(Cardinality) = NDV
- 카디널리티(Cardinality) = 총 로우 수 / NDV
해설
조건절이 =일 때 선택도는 1/NDV이다. 카디날러티는 선택도 * 총 로우 수이다.
36. 다음 중 통계정보 수집 시 고려사항을 설명한 것으로 가장 부적절한 것은?
- 시간/주기 : 부하가 없는 시간대에 가능한 한 빠르게 수집을 완료해야 함
- 표본(Sample) 크기 : 가능한 한 많은 양의 데이터를 읽도록 해야 함
- 정확성 : 표본(Sample) 검사하더라도 전수 검사할 때의 통계치에 근접 해야 함
- 안정성 : 데이터에 큰 변화가 없는데도 매번 통계치가 바뀌지 않아아함
해설
통계정보 수집 시 시스템에 많은 부하를 주므로 대용량 테이블에는 흔히 표본 검사 방식을 사용한다. 표본 검사 시, 가능한 한 적은 양의 데이터를 읽고도 전수 검사할 때의 통계치에 근접하도록 해야 한다.
37. 다음 중 동일 결과를 반환하는 SQL에서 가장 효율적인 것은? (단, ItemAmtFunc는 저장형 함수이고, 상품 테이블의 PK는 상품코드임)
보기 생략
해설
rownum을 select 에 넣으면 뷰 merging 안 된다. 하지만 itemamtfunc의 값을 재활용하기 위해 뷰 merging 을 안 하는 게 목적이기 때문에 2번이 정답이다.
4번처럼 하면 함수의 값이 캐싱이 되지만 어차피 상품코드가 unique 한 값이기 때문에 캐싱이 안 된다.
38. Oracle에서 no_merge 힌트를 사용하지 않고도 아래 SQL문에 뷰 머징 (View Merging)O| 발생하지 않게 하려고 한다. 다음 중 ㄱ 안에 들어갈 키워드로 가장 적절한 것은?
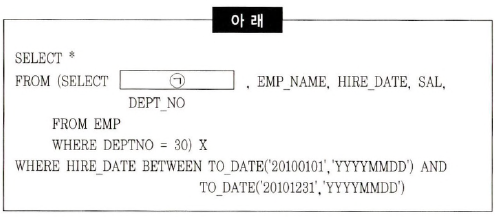
- TO_DATE(SYSDATE, ’YYYYMMDD’)
- ROWNUM
- EMPNO
- ROWID
해설
rownum 넣으면 뷰 merging 안 된다.
39. 다음 중 뷰 머징(View Merging)을 불가능하게 하는 경우가 아닌 것은?
- 뷰 안에 ROWNUM을 사용한 경우
- 뷰 안에 Group By를 사용한 경우
- 뷰 안에 윈도우 함수(Window Function)를 사용한 경우
- 뷰 안에 UNION 연산사를 사용한 경우
해설
group by 있는 뷰 merging -> complex view merging이긴 한데 불가능하진 않다.
40. 다음 중 아래 SO에 대한 설명으로 가장 적절한 것은?(단,쿼리변환(Query Transformation)이 동작하는 것으로 가정함)

- emp 테이블에 job + deptno로 구성된 인덱스를 만들면, job 조건만 인덱스 액세스 조건으로 사용되고, deptno 조건은 필터로 처리된다.
- emp 테이블 job에 단일 컬럼 인덱스를 만들면, 이 인덱스를 정상적으로 사용할 수 없다. 즉, Index Range Scan할 수 없다.
- emp 테이블에 deptno + job으로 구성된 인덱스를 만들면, job과 deptno에 대한 조건 모두를 인덱스 액세스 조건으로 사용할 수 있다.
- emp 테이블 deptno에 단일 컬럼 인덱스를 만들면, 이 인덱스를 정상적 으로 사용할 수 없다. 즉, Index Range Scan할 수 없다.
해설
- 둘 다 인덱스 액세스 조건으로 사용될 수 있다.
- 할 수 있다. job 칼럼을 변환하는 부분이 없기 때문이다.
- deptno + job이 인덱스라면 메인쿼리에 있는 deptno 조건절을 pushdown 해서 서브쿼리를 merging 할 수 없는 대신 미리 필터링할 수 있다.
- 할 수 있다.
41. 다음 중 아래 SQL을 처리하는 데 있어 옵티마이저가 선택할 수 있는 옵션으로 가장 부적절한 것은?

- 두 인라인 뷰(Inline View)를 풀어(View Merging) 고객번호 조인을 먼저 처리한 후에, 고객번호로 group by하면서 과금액과 수납액을 구한다.
- 인라인 뷰 e2에 있는 '고객번호 = 10' 조건을 el에 전달해 줌으로써 과금』k 인덱스를 사용해 처리한다.
- 메인 쿼리에 있는 '수납액 > 0' 조건을 인라인 뷰 e2에 제공함으로써 조인 연산 전에 필터링이 일어나도록 한다.
- 사용자가 작성한 SQL 형태 그대로, 각 인라인 뷰를 따로 최적화한 후에 조인한다.
해설
- 문제의 쿼리는 고객번호가 10번인 고객의 총 수납액과 과금액을 구하는 것이다. group by를 나중에 하면 모든 고객의 과금액을 구한 다음 10번 고객만 뽑는 꼴이다.
- 조건절 pullup 후 pushdown을 하는 것이다. 어차피 inner join인데다 e2에 고객번호=10이 걸려있어서 결국 10번 고객만 나오기 때문에 e1에서 전체를 볼 필요가 없다.
- 수납액 > 0으로 마지막에 거르는 것보다 거르고 시작하는 것이 연산량이 적다.
- 1번처럼 다 풀고 최적화하는 것보다 각자 최적화 하고 합치는 것이 낫다.
42. 아래 SQL과 트레이스 결과를 보고, 최적의 튜닝 방안을 선택하시오.
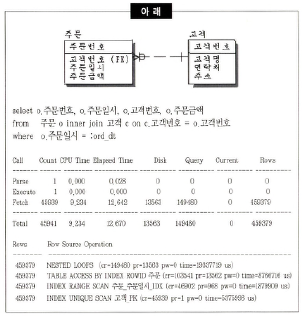
보기 생략
해설
쿼리에서 고객 테이블에 관한 정보는 필요가 없다. -> 조인을 제거한다.
