트랜잭션
트랜잭션은 업무 처리를 위한 논리적인 작업 단위로,
내부의 여러 연산들이 하나의 연산처럼 전부 처리되거나
아니면 (도중에 오류가 발생하는 등의 경우) 하나도 처리되지 않도록 해야 한다. (All or Nothing)
트랜잭션의 특징
Atomicity: 원자성, All or Nothing. 트랜잭션은 더 이상 분해될 수 없는, 업무의 최소 단위이다.
Consistency: 일관성, 트랜잭션을 통해 데이터베이스의 일관성이 유지되어야 한다.
Isolation: 격리성, 트랜잭션이 실행 중에 생성하는 연산의 중간 결과는 다른 트랜잭션이 접근할 수 없다.
Durability: 영속성, 트랜잭션이 완료되면 그 결과는 데이터베이스에 영속적으로 저장된다.
문장수준 읽기 일관성
SQL문이 실행되는 도중, 다른 세션이 그 테이블을 조회하거나 수정하는 일이 발생할 수도 있다.
이때 앞서 실행된 SQL문의 결과의 일관성을 보장하는 것을 문장수준 읽기 일관성,
Statement level read consistency라고 한다.
예시
테이블 '계좌'가 다음과 같고
| 계좌번호 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 잔고 | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 |
select sum(잔고) from 계좌트랜잭션 1이 위 문장을 실행하는 도중,
insert into 계좌(계좌번호, 잔고) values (11, 1000);
commit;이나
update 계좌 set 잔고 = 잔고 + 100 where 계좌번호 = 7;
update 계좌 set 잔고 = 잔고 - 100 where 계좌번호 = 3;
commit;와 같은 트랜잭션이 실행된다면
트랜잭션 1의 결과는 달라질 수 있다.
Consistent 모드 읽기, Current 모드 읽기
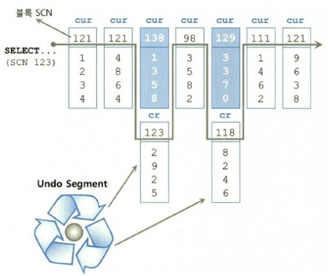
오라클은 데이터를 SCN(System Commit Number)라고 하는 시간정보를 이용하여 데이터를 버전별로 관리하고 있다.
SCN 변수는 사용자가 커밋할 때마다, 혹은 일정 시간마다 1씩 증가한다.
또한 블록 별로 마지막으로 변경된 시점 정보를 식별하기 위해
모든 블록 헤더에 SCN(System Change Number)를 기록한다.
이를 통해 데이터베이스의 일관성 있는 상태를 식별해서
문장이 시작됐을 때의 데이터베이스의 상태(쿼리 시점 SCN)로 되돌린 다음(Undo)
필요한 데이터를 읽어서 문장 수준의 일관성을 유지할 수 있다.
데이터가 시점별로 변경된 기록들은 CR 블록에 저장된다.
CR블록은 Current블록, 즉 수정된 시점의 블록에 대한 복사본이다.
Current블록은 하나이며, 그게 수정될 때마다 CR블록들에 복사되어 여러 버전이 존재하는 것이다.
이렇게 Current블록을 CR 블록으로 Copy해서 읽기 일관성을 지원하는 메커니즘을
다중 버전 읽기 일관성 모델(Multi-Version Read Consistency Model)이라고 한다.
Consistent 모드 읽기에서는 쿼리 SCN보다 작거나 같은 블록SCN만을 읽는다.
(쿼리 시작되기 전에 수정사항이 commit된 블록)
Current 모드 읽기에서는 SCN에 상관 없이 Current 블록만을 읽는다.
select는 consistent 모드로 읽고,
insert, update, delete, merge는 current 모드로 읽고 쓴다.
다만 갱신할 대상 레코드를 식별하는 작업은 consistent 모드로 이루어진다.
트랜잭션 수준 읽기 일관성
위의 문장수준 읽기 일관성과 비슷하게,
트랜잭션 수준 읽기 일관성(Transaction-Level Read Consistency)는 트랜잭션이 시작된 시점을 기준으로 일관성 있게 데이터를 읽어들이는 것을 말한다.
오라클은 완벽한 문장 수준의 읽기 일관성을 보장하지만 트랜잭션에 대해서는 아니다.
트랜잭션 수준 읽기 일관성이 없을 때 생기는 문제
-
Dirty Read (= Uncommitted Dependency)
수정 중이고, 커밋되지 않은 데이터를 다른 트랜잭션에서 읽게 되는 문제이다.
이렇게 되면 쿼리의 최종 결과값의 일관성이 보장되지 않을 수도 있다.
즉, 트랜잭션의 4대 원칙 중 Consistency에 어긋나게 된다.
commit을 안 했으므로 언제든 롤백할 수 있기 때문이다. -
Non-Repeatable Read(= Inconsistent Analysis)
한 트랜잭션 내에서 같은 쿼리를 두 번 수행할 때,
그 사이에 다른 트랜잭션이 값을 수정 또는 삭제해서 둘의 결과가 다르게 나타나는
비일관성(Inconsistency)이 발생하는 문제이다. -
Phantom Read
한 트랜잭션 안에서 일정 범위의 레코드들을 두 번 이상 읽을 때,
첫 번째 쿼리에서 없던 유령 레코드가 두 번째 쿼리에서 나타나는 현상이다.
고립화 수준
위 문제들을 해결하기 위해서, 트랜잭션 고립화 수준이라는 것이 존재한다.
레벨 1. Read Committed
Dirty Read를 해결하기 위해서, 커밋된 데이터만 읽는 것을 허용한다.
오라클은 쿼리 시작 시점의 Undo 데이터를,
다른 DBMS는 읽기 공유 Lock을 이용해서 해결한다.
레벨 2. Repeatable Read
선행 트랜잭션이 읽은 데이터는 트랜잭션이 종료될 때까지 후행 트랜잭션이 갱신하거나 삭제하는 것을 불허함으로써
같은 데이터를 두 번 쿼리했을 때 일관성 있는 결과를 리턴하도록 한다.
오라클에선 for update절을 이용해 구현가능하다.
레벨 3. Serializable
선행 트랜잭션이 읽은 데이터를 후행 트랜잭션이 갱신하거나 삭제하지 못할 뿐만 아니라
중간에 새로운 레코드를 삽입하는 것도 막아줌
완벽한 읽기 일관성을 보장한다.
set transaction isolation level serializable;로 조정할 수 있다.
일관성과 동시성, trade off
일관성과 동시성은 반비례의 관계를 가진다.
일관성을 높이면, 즉 lock 메카니즘을 통해 레코드에의 동시 접근을 막으면 동시성이 떨어진다.
반대로 레코드를 동시에 여러 트랜잭션이 수정할 수 있게 되면 일관성이 떨어질 위험이 있다.
다만 오라클의 경우엔 lock을 안 쓰고 트랜잭션을 고립화 시키므로 동시성이 떨어지진 않는다.
비관적/낙관적 동시성 제어
비관적 동시성 제어(pessimistic concurrency control)는 사용자들이 같은 데이터를 동시에 수정할 것이라고 가정한다.
따라서 한 사용자가 데이터를 읽는 시점에 Lock을 걸고 조회 또는 갱신처리가 완료될 때까지 이를 유지한다.
낙관적 동시성 제어(optimistic concurrency contorl)는 사용자들이 같은 데이터를 동시에 수정하지 않을 것이라고 가정한다.
따라서 데이터를 읽을 때는 Lock을 설정하지 않는다.
Snapshot too old
오라클은 트랜잭션의 일관성을 유지하는 과정에서 Lock을 사용하지 않는다.
단 scn과 undo 데이터를 활용해서 동시성과 일관성의 두 마리 토끼를 잡는다.
다중 버전 동시성 제어(Multi-version Concurrency Control)는 대신 Snapshot too old에러가 발생할 수 있다.
일정 작업 후 A 레코드를 읽어 수정하는 작업을 포함하는 쿼리가 있는데
A 레코드 수정하기 전 수많은 다른 트랜잭션들이 여러 수정작업을 거치면서
Undo 세그먼트 (CR 블록들이 있는 공간)를 다 쓰고도 모자라서 이미 있는 공간에 덮어써야 하는 지경까지 가게 되고
하필 A도 마침 수정되어서 해당 Undo 영역이 재사용되었는데,
그제서야 선행 작업을 마치고 나서 A 레코드를 조회하려고 할 때 발생한다.
이게 오류인 이유는,
문장 수준 읽기 일관성을 위해서라면 쿼리가 시작됐을 때의 시점의 A 레코드를 읽어야 할텐데
A 레코드에 해당하는 공간이 Undo 공간이 부족해서 재사용, 즉 덮어씌워지는 바람에
그 때의 A 레코드를 못 불러와서이기 때문이다.
| 시간(분:초) | 진행사항 |
|---|---|
| 0:00 | 쿼리 시작 |
| 0:01 | 다른 세션이 블록 1,000,000을 UPDATE한다. 이 블록에 대한 UNDO 정보는 UNDO 세그먼트에 기록한다. |
| 0:01 | 이 UPDATE 세션이 COMMIT한다. 이 세션이 생성한 UNDO 데이터는 아직도 그대로 남아 있지만, 이후로 공간이 필요해지는 순간 언제든 덮어 쓰일 수 있다. |
| 1:00 | 쿼리 진행이 블록 200,000에 도달했다. |
| 1:01 | 많은 활동이 계속 진행되어 그 만큼 많은 UNDO 데이터를 생성했다. |
| 3:00 | 쿼리 진행이 블록 600,000에 도달했다. |
| 4:00 | UNDO 세그먼트가 덮여 쓰여지기 시작하고 쿼리를 시작할 때 활성화되어 있던(트랜잭션이 진행 중이던) 공간을 재사용한다. 특히, 0:01에 블록 1,000,000에 대한 UPDATE 시 사용되었던 UNDO 세그먼트 공간을 방금 재사용했다. |
| 5:00 | 쿼리가 블록 1,000,000에 도달했다. 쿼리가 시작한 이후로 그 블록이 변경되었음을 발견한다. 일관적인 읽기를 위해 UNDO 세그먼트로 가서 그 블록에 대한 UNDO를 찾으려고 시도한다. 이 시점에, 필요한 UNDO 정보가 더 이상 존재하지 않음을 발견하고 ORA-01555 에러와 함께 쿼리가 실패한다. |
이는 Undo 영역이 너무 작거나, 쿼리가 너무 오래 돌아서 그런 것이다.
snapshot too old를 줄이기 위해선
1. Undo 영역의 크기를 증가시킨다.
2. 불필요하게 커밋을 자주 수행하지 않는다. (CR블록의 증가를 줄인다.)
3. fetch across commit 형태의 프로그램 작성을 피해 다른 방식으로 구현한다. (2번이랑 일맥상통한다. fetch across commit은 반복문 내에서 계속해서 로우 하나하나를 commit하는 형태이다.)
4. 트랜잭션이 몰리는 시간대에 오래 걸리는 쿼리가 같이 수행되지 않도록 한다.
5. 일관성에 문제가 없다는 가정 하에, 큰 테이블을 일정 범위로 나누어서 읽고 단계적으로 실행한다.
6. 오랜 시간에 걸쳐 같은 블록을 여러 번 방문하는 nested loop 형태의 조인문 또는 인덱스를 경유한 테이블 액세스를 수반하는 프로그램이 있는지 체크하고
조인 메소드 변경, full table scan 등 이를 회피할 수 있는 방법을 강구한다.
7. 소트 부하를 감수하더라도 order by 등을 강제로 삽입해 소트 연산이 발생하도록 한다.
서버에서 데이터를 읽어 temp 세그먼트에 저장하는데 성공하면 같은 블록을 아무리 재방문하더라도 에러가 나지 않는다.
8. 대량 업데이트 후 full scan 하도록 쿼리를 날린다.
