11. 다음 중 데이터베이스 Call에 대한 설명으로 가장 부적절한 것을 2개 고르시오.
- SELECT 문장을 수행할 땐 Execute, Parse, Fetch 순으로 Call이 발생한다.
- SELECT 문장에선 대부분 I/O가 Fetch Call 단계에서 일어난다.
- Group By를 포함한 SELECT 문장에서 Group By 결과집합을 만들기까지의 I/O는 Execute Call 단계에서, 이후 결과집합을 전송할 때의 I/O는 Fetch Call 단계에서 일어난다.
- INSERT, UPDATE, DELETE 문장에선 Fetch Call이 전혀 발생하지 않는다.
해설
- Parse, Execute, Fetch 순이다.
- Fetch Call은 결과집합을 요청에 따라 사용자에게 반환하는 콜이다.
- Group By의 결과집합 반환은 Fetch Call에서 일어난다.
- DML은 Fetch Call을 할 이유가 없다.
12. 다음 중 SQL 트레이스에서 얻은 Call Statistics를 통해 얻을 수 있는 정보와 가장 거리가 먼 것은?
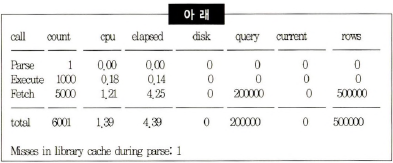
- SQL 파싱 부하가 최소화되도록 프로그램을 효과적으로 작성하였다.
- Order By, Group By 등 데이터 정렬이 필요한 연산을 포함하지 않는 SQL이다.
- 실행할 때마다 평균적으로 200개 블록을 읽었고, 필요한 블록을 모두 버퍼캐시에서 찾았다.
- 매번 실행할 때마다 비슷한 양의 결과집합을 반환했다면, Array(=Fetch) Size는 100 정도로 설정한 상태였을 것이다.
해설
- 밑에 Library cache miss가 1인 걸로 보아, 파싱을 딱 한 번만 했다.
- call 종류만 봐선 모른다.
- query (읽은 버퍼 수)가 200000이고, 1000번 실행됐으므로 실행 당 200개의 블록을 버퍼에서 읽었다. (만약 disk가 200000이었으면 디스크에서 읽은 것이다)
- rows가 500000이고 fetch call이 5000이므로 100개씩 읽어들였다.
13. 다음 중 부분범위처리에 대한 설명으로 가장 부적절한 것은?
- 부분범위처리가 가능하도록 SQL을 작성하면 출력 대상 레코드가 많을 수록 쿼리 응답 속도도 그만큼 빨라진다.
INSERT INTO ... SELECT문장에서도 인덱스를 잘 활용하면 부분범위처리에 의한 성능 개선 효과를 얻을 수 있다.- Array 크기를 증가시키면 데이터베이스 Call 횟수가 감소한다.
- Array 크기를 증가시키면 블록 I/O 횟수가 감소한다.
해설
- 전체 100개 데이터가 있다고 할 때, 1개씩 100번 출력하는 것보다 10개씩 10번 출력하는 게 더 빠르다.
- INSERT는 부분범위처리의 대상이 아니다. 데이터베이스에서 한 번에 일어나기 때문이다.
- Array 크기를 증가시키면 fetch 횟수가 줄어든다.
- Array 크기를 증가시키면 블록 I/O 횟수가 줄어든다. 단, 블록 크기보다 더 늘리면 효과가 없다.
14. 다음 중 사용자 정의 함수(User Defined Function)의 성능 특성에 대한 설명으로 가장 부적절한 것을 2개 고르시오.
- SQL을 포함하는 형태의 사용자 정의 함수라면, 대용량 쿼리에 그것을 사용하는 순간 성능이 크게 저하된다.
- SQL을 포함하지 않는 형태의 사용자 정의 함수라면, 대용량 쿼리에 그것을 사용해도 성능에 큰 영향은 없다.
- 작은 코드 테이블로부터 코드명을 가져오는 정도의 사용자 정의 함수 라면, 코드명을 가져오기 위해 매번 조인하는 것보다 오히려 성능상 유리하다.
- 성능이 중요하다면. 함수 안에서 또다른 함수를 Recursive하게 호출 하는 형태는 지양해야 한다.
해설
- 사용자 정의 함수는 컴파일 해야 하고 가상머신으로 돌려야 한다. context switch 때문에 시간을 많이 잡아먹는다.
- SQL 포함 여부에 상관 없이 context switch는 존재한다.
- 스칼라 서브쿼리로 해결이 가능하고 그게 제일 빠르다.
- 맞다.
15. 다음중 오라클어서 DB 저장형 함수 (사용자 정의 함수)를 사용할 때성능이 저하돠는 원인과 거리가 가장 먼 것은?
- 함수를 실행할 때마다 컴파일하는 부하
- 가상머신(VM) 상에서 실행되므로 매번 바이트 코드를 해석하는 부하
- 쿼리 문장의 조회 건수만큼 함수를 반복적으로 호출하는 부하
- 함수에 내장된 쿼리가 있다면, 해당 문장을 Recursive하게 반복 수행 하는 부하
해설
- 함수를 실행할 때마다 컴파일하진 않는다.
16. 다음 중 아래 두 SQL의 수행 성능을 비교한 설명으로 가장 적절한 것은?
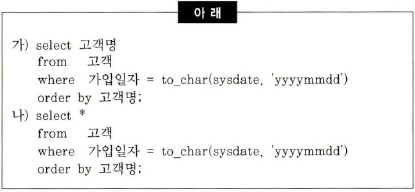
- 클라이언트에게 데이터를 전송할 때 발생하는 네트워크 트래픽은 두 SQL 이 똑같다.
- 가입일자만으로 구성된 단일 컬럼 인덱스를 사용한다면, 두 SQL의 소트 공간 사용량은 똑같다.
- 가입일자만으로 구성된 단일 컬럼 인덱스를 사용한다면 ’나’보다 '가’ SQL에 블록 I/O가 더 많이 발생한다.
- {가입일자 + 고객명}을 선두로 갖는 인덱스를 사용한다면 '가’보다 ’나’ SQL에 블록 I/O가 더 많이 발생한다.
해설
- '나'는 모든 칼럼을 결과집합으로 전송한다.
- '나'의 칼럼이 더 많기 때문에 소트 공간을 더 많이 사용한다.
- 인덱스가 가입일자 밖에 없으면 어차피 고객명 찾으려고 블록 한 번 들어가봐야 하기 때문에 블록 I/O는 '가'나 '나'나 똑같다.
- 인덱스가 가입일자 + 고객명이면 '가'의 경우 블록을 안 들여다 봐도 된다. 인덱스만 결과 집합으로 전달하면 되기 때문이다. 그래서 '가'보다 '나'에서 블록 I/O가 더 많이 발생한다.
17. 다음 중 I/O 효율화 튜닝 방안으로 가장 부적절한 것은?
- 필요한 최소 블록만 읽도록 쿼리를 작성한다.
- 전략적인 인덱스 구성은 물론 DBMS가 제공하는 다양한 기능을 활용한다.
- 옵티마이저 행동에 영향을 미치는 가장 중요한 요소는 통계정보이므로 변경이 거의 없는 테이블일지라도 통계정보를 매일 수집해 준다.
- 필요하다면, 옵티마이저 힌트를 사용해 최적의 액세스 경로로 유도한다.
해설
- 블록 I/O call은 DB 성능의 가장 큰 지표이다.
- 되도록이면 사용자 정의 함수보다 빌트인 함수를 사용하고, 옵티마이저를 잘 활용해야 한다.
- 변경이 거의 없으면 맨날 안 해도 된다.
- 옵티마이저 힌트를 잘 사용하면 SQL 쿼리 성능을 높일 수 있다.
18. 다음 중 블록 I/O에 대한 설명으로 가장 부적절한 것은?
- Random I/O는 인덱스를 통해 테이블을 액세스할 때 주로 발생한다.
- Direct Path I/O는 병 렬로 인덱스를 통해 테이블을 액세스할 때 주로 발생한다.
- Single Block I/O는 인덱스를 통해 테이블을 액세스할 때 주로 발생한다.
- Multiblock I/O는 인덱스를 이용하지 않고 테이블 전체를 스캔할 때 주로 발생한다.
해설
- 블록의 정렬 상태는 인덱스의 정렬 상태와 일치하지 않는다. 따라서 인덱스로 접근할 때는 십중팔구 블록 당 하나를 읽게 되므로 (= 순서대로 읽어야 하는 레코드가 다른 블록에 있게 되므로) Random I/O를 하게 된다.
- Direct Path I/O는 일반적으로 병렬 쿼리로 Full Scan을 수행할 때 발생한다.
- 1번과 같은 이유로, multiblock I/O를 해봤자 정렬 상태도 다르고, 캐시 버퍼에 올려봤자 필요 없는 (방금 찾은 인덱스 범위에 들지 않는) 블록들을 올리게 되면서 LRU 알고리즘에 의해 진짜 필요한 블록들이 밀려나게 된다. 그래서 Single I/O를 해야 한다.
- 인덱스를 안 쓰고 테이블 전체를 스캔할 때는 Multiblock I/O가 유리하다. 그래야 전체 Block I/O가 줄어들기 때문이다.
19. 다음 중 데이터베아스 I/O 원리를 설명한 것으로 가장 부적절한 것은?
- 한 쿼리 내에서 같은 블록을 반복적으로 액세스하면 버퍼 캐시 히트율 (BCHR) 은 높아진다.
- Multiblock I/O는 한번의 I/O Call로 여러 데이터 블록을 읽어 메모리에 적재하는 방식이다.
- 테이블을 Full Scan할 때, 테이블이 작은 Extent로 구성되어 있을수록 더 많은 I/O Call이 발생한다.
- 인덱스를 통해 테이블을 액세스할 때, 테이블이 큰 Extent로 구성돼 있으면 더 적은 I/O Call이 발생한다.
해설
- 한 쿼리 내에서 같은 블록을 반복적으로 액세스하면 버퍼 캐시 히트율 (BCHR) 은 높아진다. 단, 이게 곧 높은 성능으로 이어지진 않는다. 여러 세션이 공유하게 되면 래치 경합이 일어날 수 있기 때문이다.
- Multiblock I/O는 필요한 블록과 인접한 블록들을 같이 캐시 버퍼에 올린다.
- extent가 작으면 안에 블록도 적게 들어있다는 뜻이다. multiblock I/O는 블록 여러개를 올리긴 하지만 그 올리는 블록들의 범위는 당시의 extent로 한정된다. 즉 extent 하나를 다 올리더라도 I/O call은 extent 수만큼 반복된다. 따라서 extent가 작을 수록 더 많은 I/O call이 발생한다.
- 인덱스를 통해 테이블을 액세스하면 어차피 single block I/O를 하게 된다. 즉 블록의 크기랑은 상관이 없다.
20. 다음 중 데이터베이스 I/O 원리에 대한 설명으로 가장 부적절한 것은?
- 단 하나의 레코드를 읽더라도 해당 레코드가 속한 블록을 통째로 읽는다.
- I/O를 수행할 때 익스텐트 내에 인접한 블록을 같이 읽어들이는 것을 'Multiblock I/O’라고 한다.
- 테이블 블록을 스캔(Scan)할 때는 Sequential I/O 방식을, 인덱스 블록을 스캔(Scan)할 때는 Random I/O 방식을 사용한다.
- MPP(Massively Parallel Processing) 방식의 데이터베이스 제품에선 각 프로세스가 독립적인 메모리 공간을 사용하며, 데이터를 저장할 때도 각각의 디스크를 사용한다. 읽을 때도 동시에 각각의 디스크를 액세스하기 때문에 병렬 I/O 효과가 극대화된다.
해설
- I/O는 블록 단위로 이루어진다.
- 맞다.
- 인덱스 블록을 스캔하는 것이랑, 인덱스를 스캔하면서 테이블을 액세스하는 것이랑은 다르다.
- 요즘은 NAS 서버나 SAN가 보편적으로 사용되기 때문에 네트워크 속도가 I/O 성능에 큰 영향을 미친다. RAC 같은 클러스터링 데이터베이스 환경에선 메모리도 I/O 성능에 영향을 미친다.
