UNIQUE 제약 조건
'중복되지 않는 유일한 값'을 입력해야 하는 조건이다. 이것은 PRIMARY KEY와 거의 비슷하며 차이점은 UNIQUE는 NULL 값을 허용한다는 점이다. NULL은 여러 개가 입력되어도 상관 없다. 회원 테이블의 예를 든다면 주로 Email 주소를 Unique로 설정하는 경우가 많다.
다음은 기존의 회원 테이블에 E-Mail열을 추가한 경우이다. 다음 두 문장은 모두 동일한 결과를 나타낸다.
USE tableDB;
DROP TABLE IF EXISTS buyTBL, userTBL;
CREATE TABLE userTBL
( userID CHAR(8) NOT NULL PRIMARY KEY,
name VARCHAR(10) NOT NULL,
birthYea INT NOT NULL,
email CHAR(30) NULL UNIQUE
);
DROP TABLE IF EXISTS userTBL;
CREATE TABLE userTBl
( userID CHAR(8) NOT NULL PRIMARY KEY,
name VARCHAR(10) NOT NULL,
birthYea INT NOT NULL,
email CHAR(30) NULL,
CONSTRAINT AK_email UNIQUE (email)
);위의 두 번째 방법은 모든 열의 정의가 끝난 상태에서 별도로 Unique 제약 조건을 추가했다. 그래서, email 정의가 끝난 후에 콤마(,)로 구분되어 있다.
- 제약 조건의 이름을 지정할 때 일반적으로 Primary Key는 PK, Foreign Key는 FK, Unique는 AK를 주로 사용한다. 참고로 Unique는 Alternate Key로도 부른다.
CHECK 제약 조건
입력되는 데이터를 점검하는 기능을 한다. 키(height)에 마이너스 값이 들어올 수 없게 한다든지, 출생년도가 1900년 이후이고 현재 시점 이전이어야 한다든지 등의 조건을 지정한다. 먼저 테이블을 정의하면서 CHECK 제약 조건을 설정하는 방법을 살펴보자.
-- 출생년도가 1900년 이후 그리고 2023년 이전, 이름은 반드시 넣어야 함.
DROP TABLE IF EXISTS userTBL;
CREATE TABLE userTBL
( userID CHAR(8) PRIMARY KEY,
name VARCHAR(10),
birthYear INT CHECK (birthYear >= 1900 AND birthYear <= 2023),
mobile1 char(3) NULL,
CONSTRAINT CK_name CHECK (name IS NOT NULL)
);첫 번째 CHECK 제약 조건은 출생년도의 제한을 뒀다. 열을 정의한 후에 바로 CHECK 예약어로 조건을 지정했다. 두 번째 CHECK 제약 조건은 열을 모두 정의한 후에, 마지막에 추가하는 방식이다. 두 번째 방식은 CHECK 제약 조건의 이름을 직접 지정할 수 있다.
필요하다면 열을 정의한 후에 ALTER TABLE문으로 제약 조건을 추가해도 된다.
-- 휴대폰 국번 체크
ALTER TABLE userTbl
ADD CONSTRAINT CK_mobile1
CHECK (mobile1 IN ('010', '011', '016', '017', '018', '019'));CHECK 제약 조건을 설정한 후에는, 제약 조건에 위배되는 값은 입력이 안 된다. CHECK에서 사용할 수 있는 조건은 SELECT문의 WHERE 구문에 들어오는 조건과 거의 비슷한 것이 들어오면 된다.
CHECK 제약 조건을 만들되 작동하지 않도록 하려면 제약 조건의 제일 뒤에 NOT ENFORCED 구문을 추가하면 되지만, 거의 사용할 일은 없다.
DEFAULT 정의
값을 입력하지 않았을 때, 자동으로 입력되는 기본 값을 정의하는 방법이다.
예로, 출생년도를 입력하지 않으면 -1을 입력하고, 주소를 특별히 입력하지 않았다면 '서울'이 입력되며, 키를 입력하지 않으면 170이라고 입력되도록 하고 싶다면 다음과 같이 정의할 수 있다.
DROP TABLE IF EXISTS userTBL;
CREATE TABLE userTBL
( userID CHAR(8) NOT NULL PRIMARY KEY,
name VARCHAR(10) NOT NULL,
birthYear INT NOT NULL DEFAULT -1,
addr CHAR(2) NOT NULL DEFAULT '서울',
mobile1 CHAR(3) NULL,
mobile2 CHAR(8) NULL,
height SMALLINT NULL DEFAULT 170,
mDate DATE NULL
);또는 ALTER TABLE 사용 시에 열에 DEFAULT를 지정하기 위해서 ALTER COLUMN문을 사용한다.
DROP TABLE IF EXISTS userTBL;
CREATE TABLE userTBL
( userID CHAR(8) NOT NULL PRIMARY KEY,
name VARCHAR(10) NOT NULL,
birthYear INT NOT NULL DEFAULT -1,
addr CHAR(2) NOT NULL DEFAULT '서울',
mobile1 CHAR(3) NULL,
mobile2 CHAR(8) NULL,
height SMALLINT NULL DEFAULT 170,
mDate DATE NULL
);
ALTER TABLE userTBL
ALTER COLUMN birthYear SET DEFAULT -1;
ALTER TABLE userTBL
ALTER COLUMN addr SET DEFAULT '서울';
ALTER TABLE userTBL
ALTER COLUMN height SET DEFAULT 170;디폴트가 설정된 열에는 다음과 같은 방법으로 데이터를 입력할 수 있다.
-- default문은 DEFAULT로 설정된 값을 자동 입력한다.
INSERT INTO usertbl VALUES ('LHL', '이혜리', default, default, '011', '1234567', default, '2023.12.12');
-- 열 이름이 명시되지 않으면 DEFAULT로 설정된 값을 자동 입력한다.
INSERT INTO usertbl(userID, name) VALUES('KAY', '김아영');
-- 값이 직접 명기되면 DEFAULT로 설정된 값은 무시된다.
INSERT INTO usertbl VALUES ('WB', '원빈', 1982, '대전', '019', '9876543', 176, '2020.5.5');
SELECT * FROM usertbl;
NULL 값 허용
NULL 값을 허용하려면 NULL을, 허용하지 않으려면 NOT NULL을 사용하면 된다. 하지만, PRIMARY KEY가 설정된 열에는 NULL 값이 있을 수 없으므로 생략하면 자동으로 NOT NULL로 인식된다.
NULL 값은 '아무 것도 없다'라는 의미다. 즉, 공백('')이나 0과 같은 값과는 다르다는 점에 주의해야 한다.
- NULL 저장 시에 고정 길이 문자형(CHAR)은 공간을 모두 차지하지만, 가변 길이 문자형(VARCHAR)은 공간을 차지하지 않는다. 그러므로, NULL 값을 많이 입력한다면 가벽 길이의 데이터 형식을 사용하는 것이 좋다.
테이블 압축
테이블 압축 기능은 대용량 테이블의 공간을 절약하는 효과를 갖는다. MySQL 5.0부터 테이블 압축 기능을 제공하기 시작했으며, MySQL 8.0에서는 내부적인 기능이 더욱 강화되어 MySQL이 허용하는 최대 용량의 데이터도 오류없이 압축이 잘 작동한다.
<실습>
테스트용 DB를 생성한 후에 동일한 열을 지닌 간단한 두 테이블을 생성한다. 단, 하나는 열 뒤에 ROW_FORMAT=COMPRESSED문을 붙여서 압축되도록 설정한다.
CREATE DATABASE IF NOT EXISTS compressDB;
USE compressDB;
CREATE TABLE normalTBL(emp_no int, first_name VARCHAR(14));
CREATE TABLE compressTBL(emp_no int, first_name VARCHAR(14))
ROW_FORMAT=COMPRESSED;
INSERT INTO normalTbl
SELECT emp_no, first_name FROM employees.employees; -- 1.5초정도 걸림
INSERT INTO compressTbl
SELECT emp_no, first_name FROM employees.employees; -- 5초정도 걸림
SHOW TABLE STATUS FROM compressDB;
DROP DATABSE IF EXISTS compressDB;
compresstbl의 길이나 크기가 훨씬 작은 것을 확인할 수 있다.
임시 테이블
이름처럼 임시로 잠깐 사용되는 테이블이다.
CREATE TEMPORARY TABLE [IF NOT EXISTS] 테이블이름
(열 정의 ...)구문 중에서 TABLE 위치에 TEMPORARY TABLE이라고 써주는 것 외에는 테이블과 정의하는 것이 동일하다. 결국 임시 테이블은 정의하는 구문만 약간 다를 뿐, 나머지 사용법 등은 일반 테이블과 동일하게 사용할 수 있다. 단, 임시 테이블은 세션내에서만 존재하며, 세션이 닫히면 자동으로 삭제된다. 또한 임시 테이블은 생성한 클라이언트에서만 접근이 가능하며, 다른 클라이언트는 접근할 수 없다.
임시 테이블은 데이터베이스 내의 다른 테이블과 이름은 동일하게 만들 수 있다. 그러면 기존의 테이블은 임시 테이블이 있는 동안에 접근이 불가능하고, 무조건 임시 테이블로 접근할 수 있다. 예로 employees DB안에 employees라는 테이블이 있지만, 임시 테이블도 employees라는 이름으로 생성할 수 있다. 그러면 employees라는 이름으로 접근하면 무조건 임시 테이블 employees로 접근이 된다. 기존의 employees는 임시 테이블 employees가 삭제되기 전에는 접근할 수가 없다.
- 기존 테이블과 임시 테이블의 이름이 같으면 혼란스러울 수 있으므로, 가능하면 임시 테이블은 기존 테이블의 이름을 사용하지 않는 것이 좋다.
임시 테이블이 삭제되는 시점
- 사용자가 DROP TABLE로 직접 삭제
- Workbench를 종료하거나 mysql 클라이언트를 종료하면 삭제됨
- MySQL 서비스가 재시작되면 삭제됨
<실습>
임시 테이블을 사용하자
접속 두개 하기
각각 Workbench1, Workbench2 라고 하자
Workbench1
-- Workbench 1
USE employees;
CREATE TEMPORARY TABLE IF NOT EXISTS temptbl (id INT, name CHAR(5));
CREATE TEMPORARY TABLE IF NOT EXISTS employees (id INT, name CHAR(5));
DESCRIBE temptbl;
DESCRIBE employees;
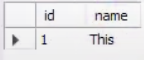
INSERT INTO temptbl VALUES (1, 'This');
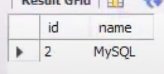
INSERT INTO employees VALUES (2, 'MySQL');
SELECT * FROM temptbl;
SELECT * FROM employees;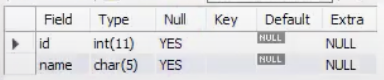
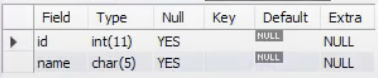
DESCRIBE로 확인
Workbench2
USE employees;
SELECT * FROM temptbl;
SELECT * FROM employees;--> 세션이 다르니까 임시테이블에 접근이 안되는 것을 확인할 수 있다.
--> SELECT * FROM employees; 는 Workbench2에 임시테이블이 존재하지 않으니까 진짜 테이블인 employees에 접근이 되는 것을 확인할 수 있다.
Workbench1
-- Workbench 1
DROP TABLE temptbl; -- 임시테이블 삭제
USE employees; -- Workbench 종료 후 실행 해보기
SELECT * FROM employees; 그럼 원래 employees 테이블이 조회가 되는 것을 확인할 수 있다.
