MySQL
1.2. MySQL 데이터베이스 모델링
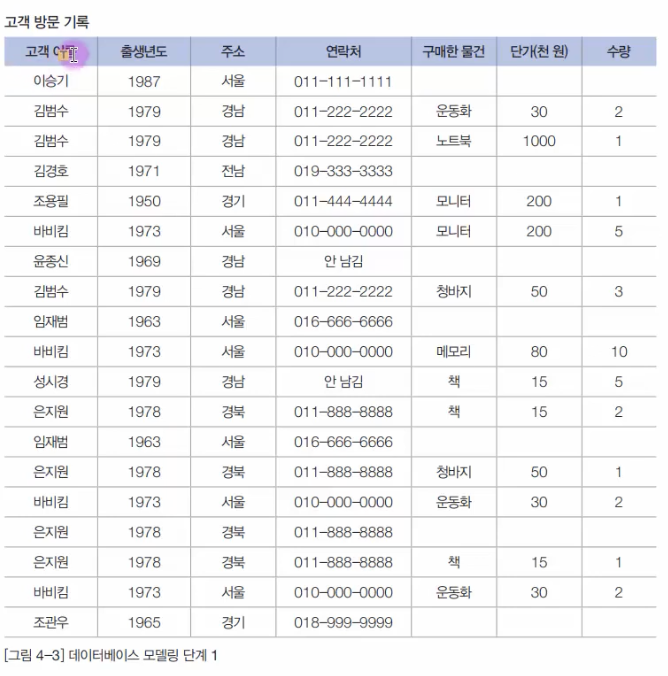
데이터베이스 모델링이란 현 세계에서 사용되는 작업이나 사물들을 DBMS의 데이터베이스 개체로 옮기기 위한 과정.<데이터베이스 모델링 실습>개념적 모델링, 논리적 모델링, 물리적 모델링으로 나눌 수 있다.우리는 데이터베이스를 학습하는 과정 중의 일부로 데이터베이스
2.3. MySQL - 인덱스, 뷰, 저장 프로시저, 트리거
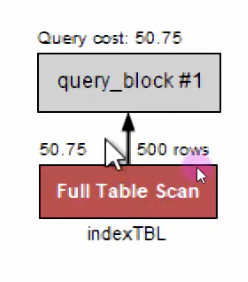
대부분의 책의 제일 뒤에 붙어 있는 '찾아보기(또는 색인)' 같은 개념. 실무에서 사용되는 수천만~수억 건 이상의 데이터에서 인덱스없이 전체 데이터를 찾아본다는 것은 MySQL입장에서는 시간이 오래 걸리는 일임. 즉 쿼리에 대한 응답을 줄이기 위해 가장 집중적으로
3.5. MySQL과 응용프로그램 연동
이번 시간에는 응용 프로그램에서 구축된 데이터 활용을 진행할거임.Visual Studio사용(Window)MySQL과 Visual Studio를 연결해주는 커넥터 설치.제어판실행 --> 관리도구 --> ODBC Data Sources (32-bit) 실행 --> 시스템
4.6. MySQL Workbench 사용법 - 쿼리창
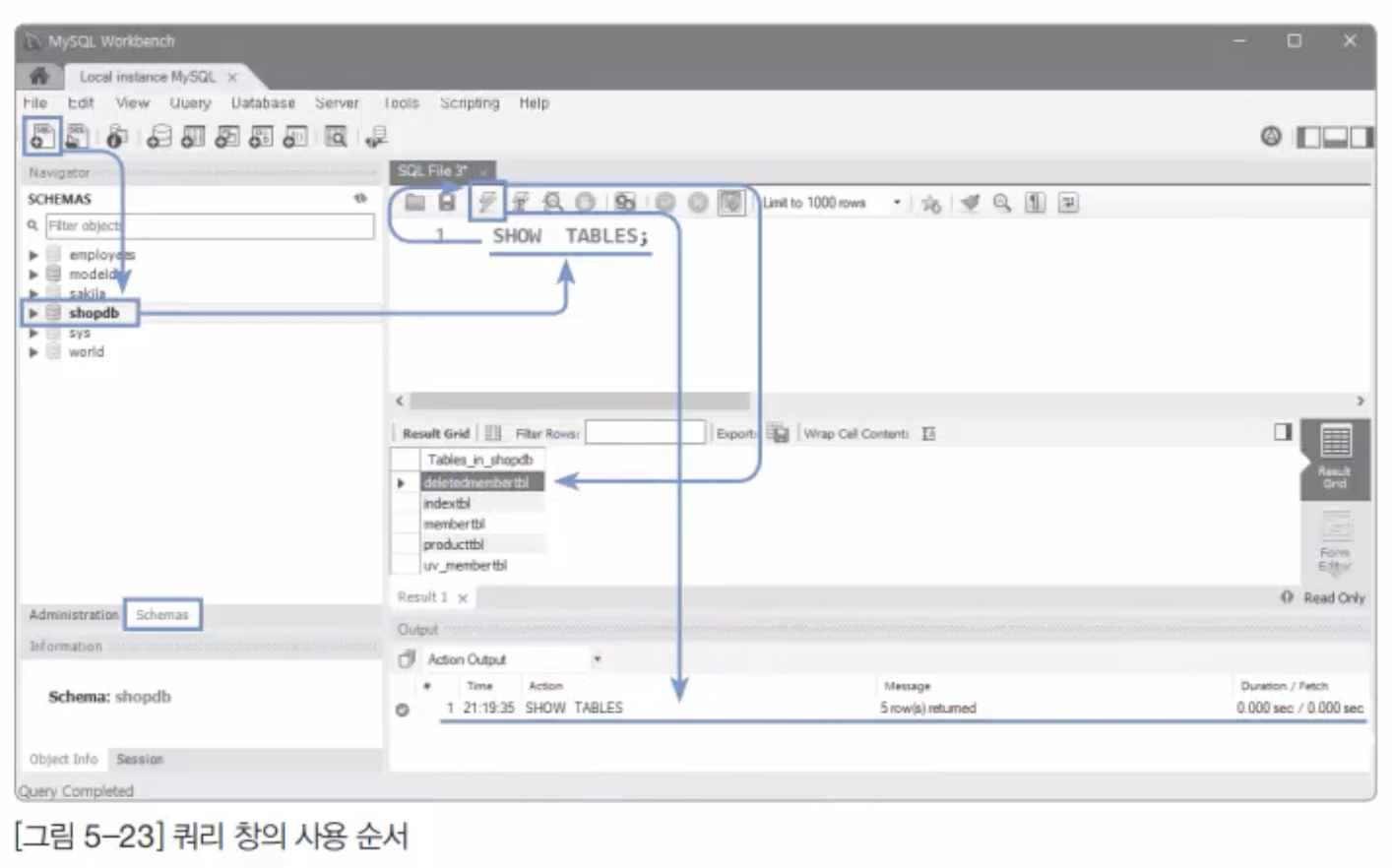
데이터베이스를 학습할 때 가장 먼저 배우게 되는 것은 SQL(Structured Query Language)문일 것이다.앞으로도 계속 내비게이터와 더불어서 '쿼리 창(Query Editor)'을 계속 사용하게 될 것임.쿼리 창을 간단히 표현하면 '쿼리 문장(SQL구문)
5. 7. MySQL 서버 관리 - Linux 서버
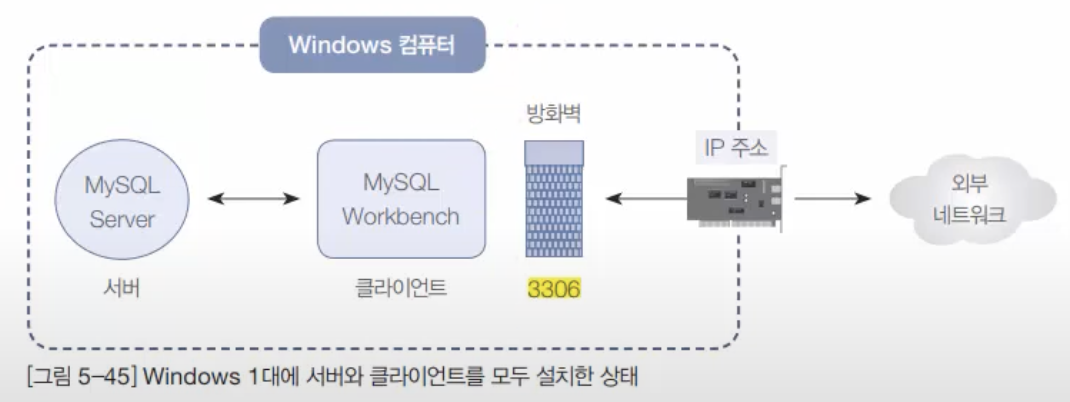
실무에서는 Windows용 MySQL보다는 Linux용 MySQL을 더 많이 사용한다. 그런데 Linux는 대부분 명령어 모드로만 사용하기 때문에 앞에서 배운 강력한 MySQL 툴인 Workbench를 사용할 수가 없다.우리가 지금까지 사용한 네트워크 환경의 구조Win
6.8. MySQL 사용자 관리
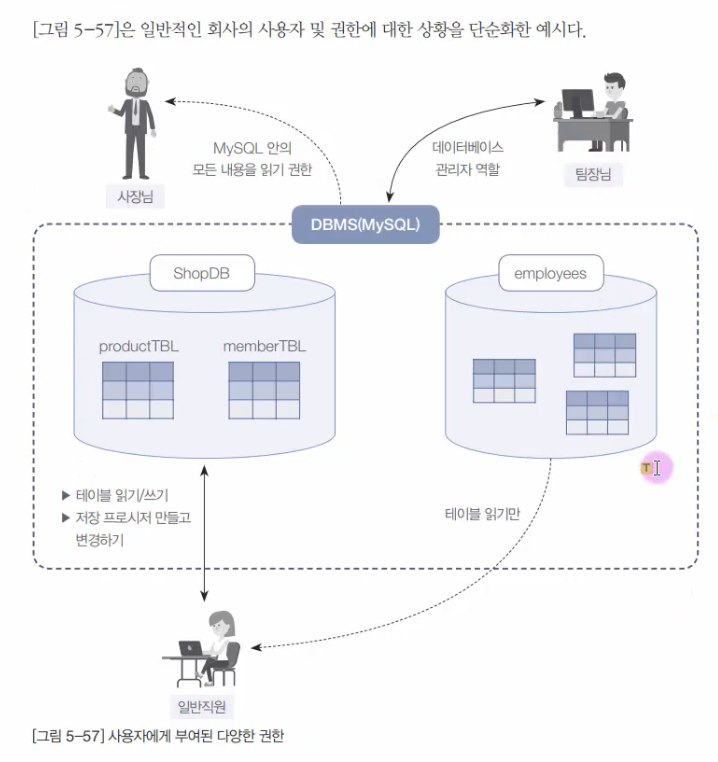
지금까지 우리는 MySQL 관리자인 root로 접속해서 사용함. 그런데, 실무에서는 MySQL 데이터베이스를 혼자 사용하는 것이 아니라 다양한 사용자나 응용 프로그램에 접속해서 사용함.MySQL에 접속하는 사람들에게 모두 root의 비밀번호를 알려준다면? 고의든 실수든
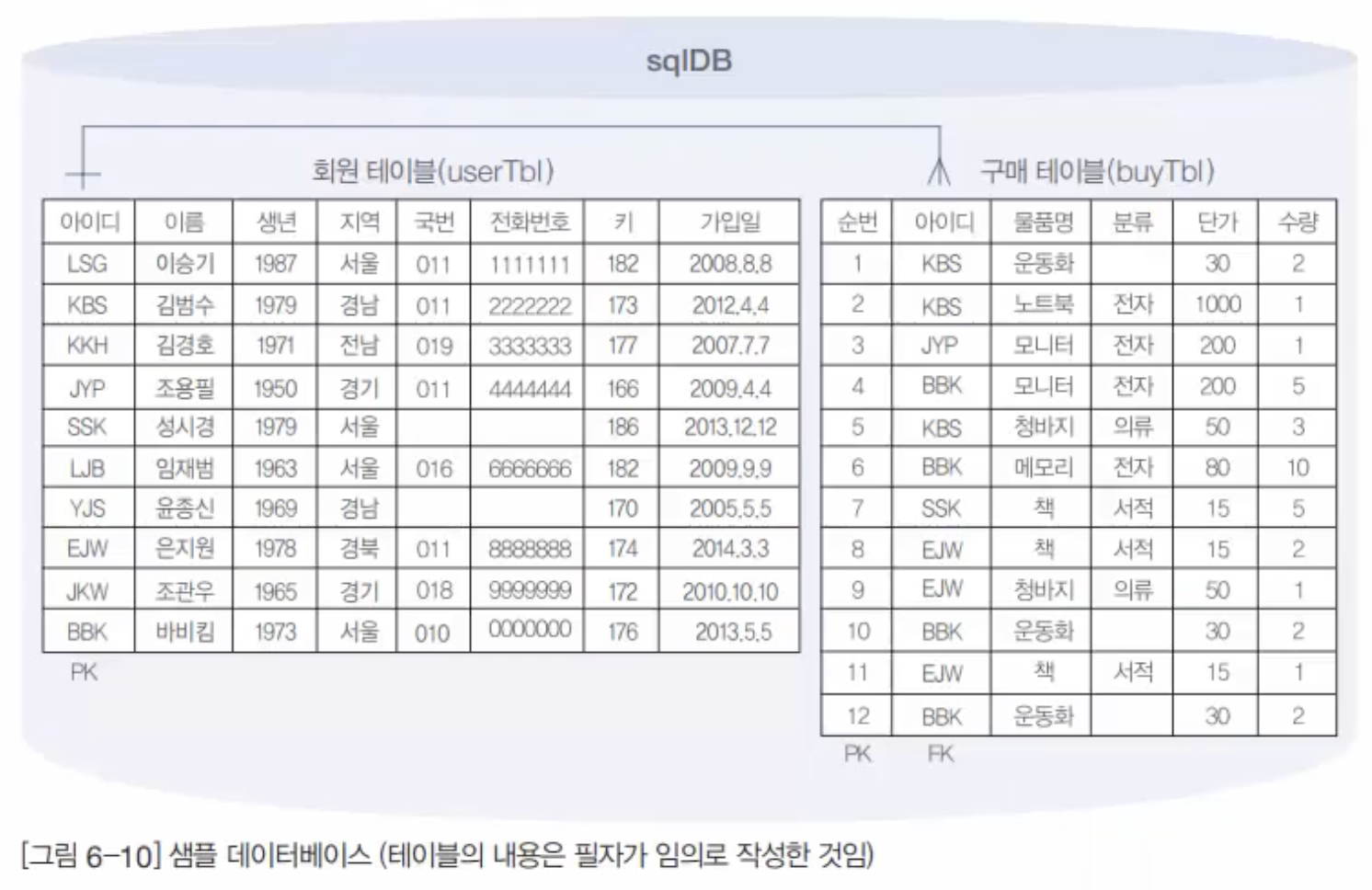
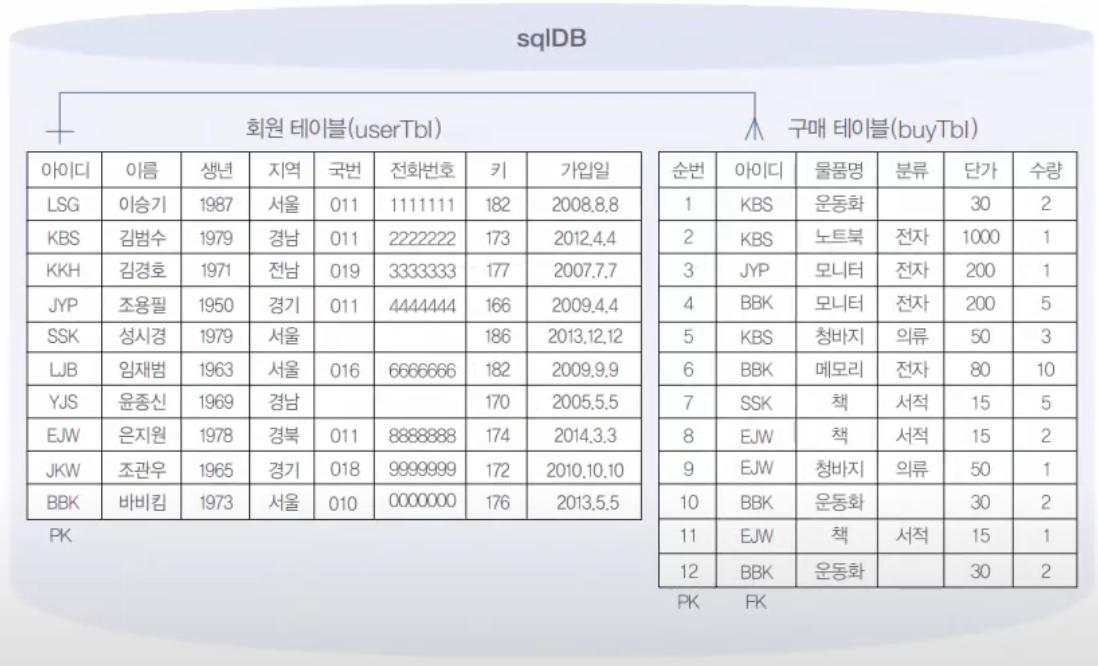
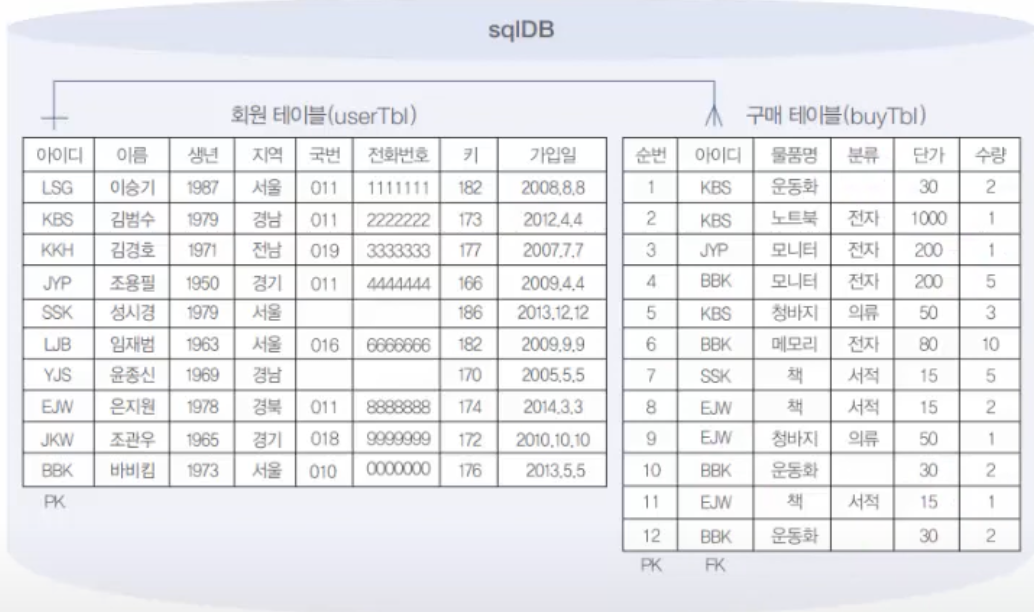
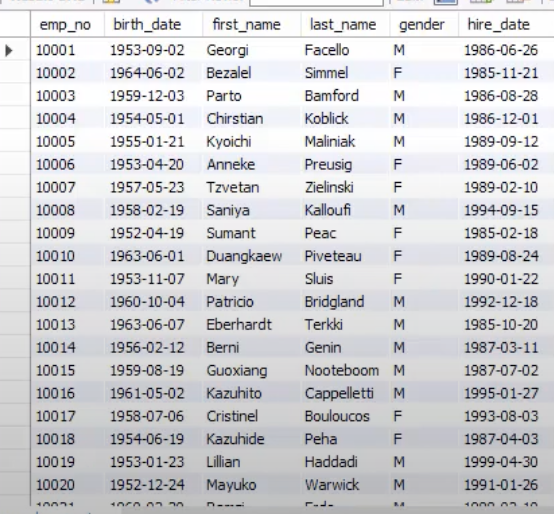
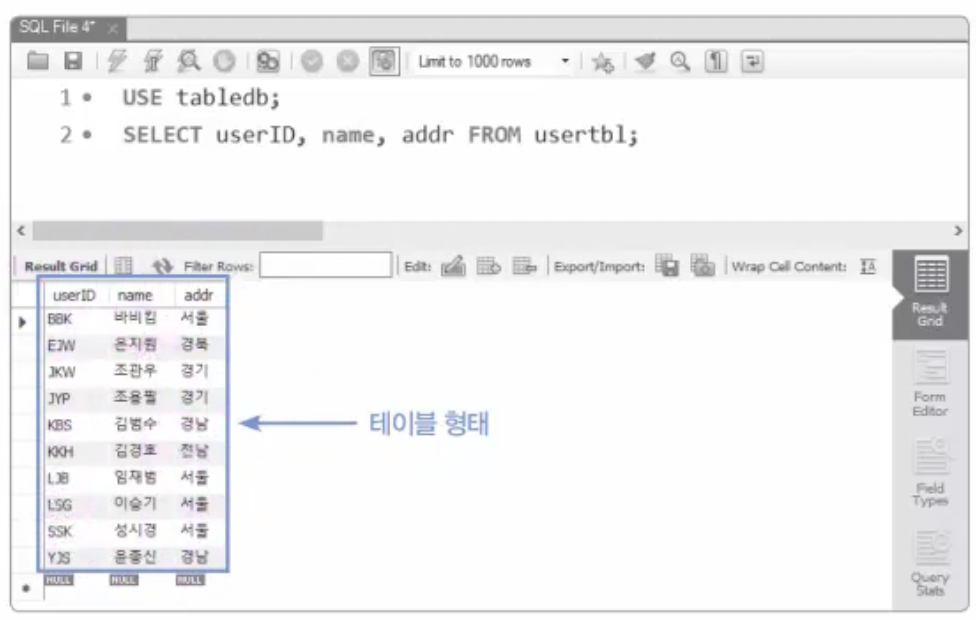
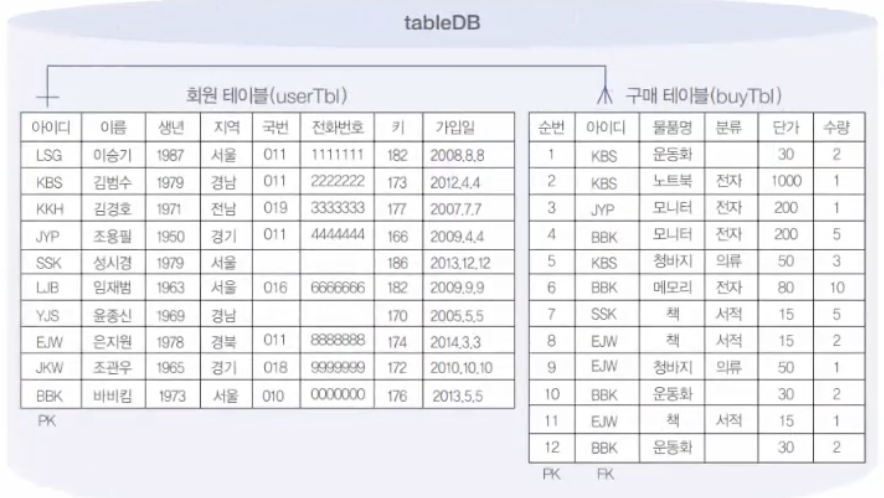
7.9. MySQL 샘플데이터베이스(sqlDB)생성
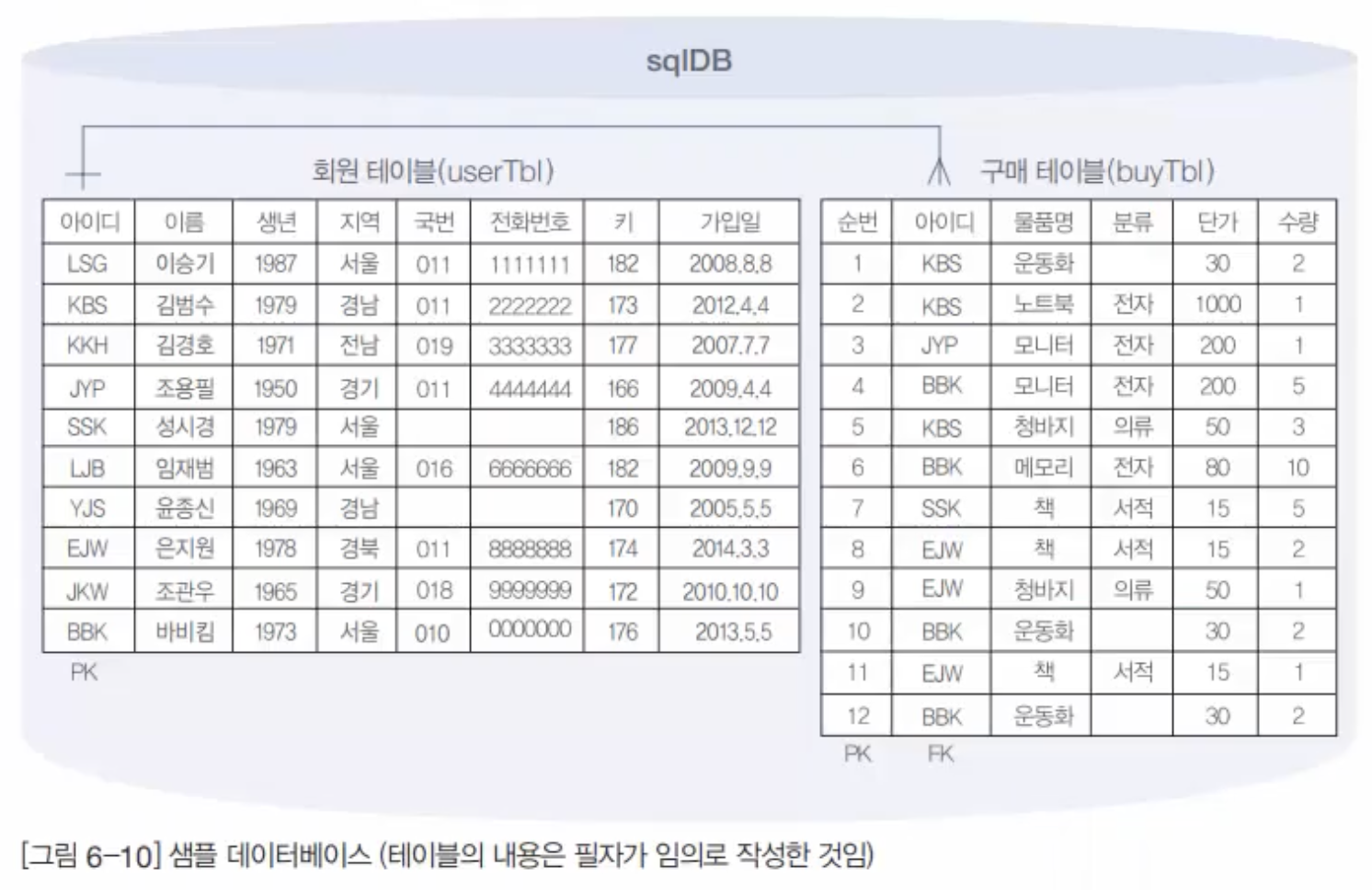
이 데이터베이스의 이름을 sqlDB로 줄 것임.이 sqlDB는 아주 간단한 쇼핑몰DB라고 생각하면 됨.sqlDB안에는 회원이 회원가입한 회원 테이블(userTBl)와 회원이 구매한 구매 테이블(buyTBl)이 존재함.이 테이블 각각에 10건과 12건의 데이터를 입력.이
8.10. MySQL WHERE절
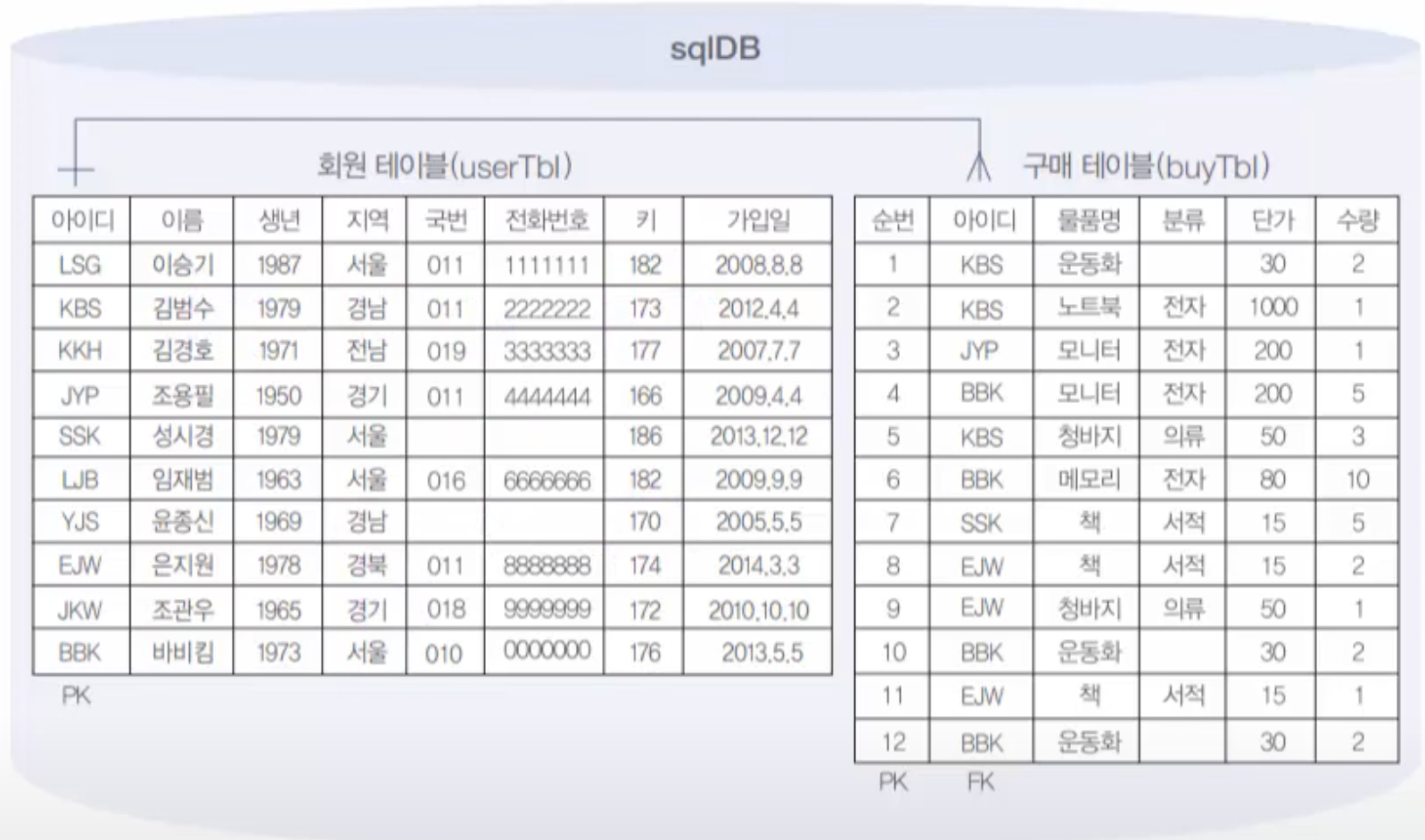
특정한 조건의 데이터만 조회하는 만약 WHERE 조건 없이 다음을 조회해 보자. 지금 usertbl은 우리가 10건의 데이터만 넣었지만, 만약 실제로 대형 인터넷 쇼핑몰의 가입 회원으로 생각하면 수백만 명이 될 수도 있다. 그렇다면 전체 데이터가 스크롤되어 넘어가는
9.11. MySQL Group By, Having절
GROUP BY절이제는 SELECT 형식 중에서 GROUP BY, HAVING절에 대해서 파악해 보자.먼저 GROUP BY절을 살펴보자. 이 절이 말 그대로 그룹으로 묶어주는 역할을 한다. sqlDB의 구매 테이블(buytbl)에서 사용자(userID)가 구매한 물품의
10.12. MySQL - Insert, Update, Delete 및 CTE
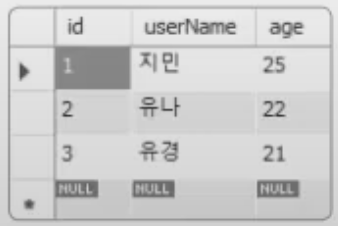
INSERT문 기본테이블에 데이터를 삽입하는 명령어.우선 테이블 이름 다음에 나오는 열은 생략이 가능하다. 하지만, 생략할 경우에 VALUES 다음에 나오는 값들의 순서 및 개수가 테이블이 정의된 열 순서 및 개수와 동일해야 한다. 만약, 위의 예에서 id와 이름만을
11.13. MySQL SQL 고급 - 데이터 형식, 변수
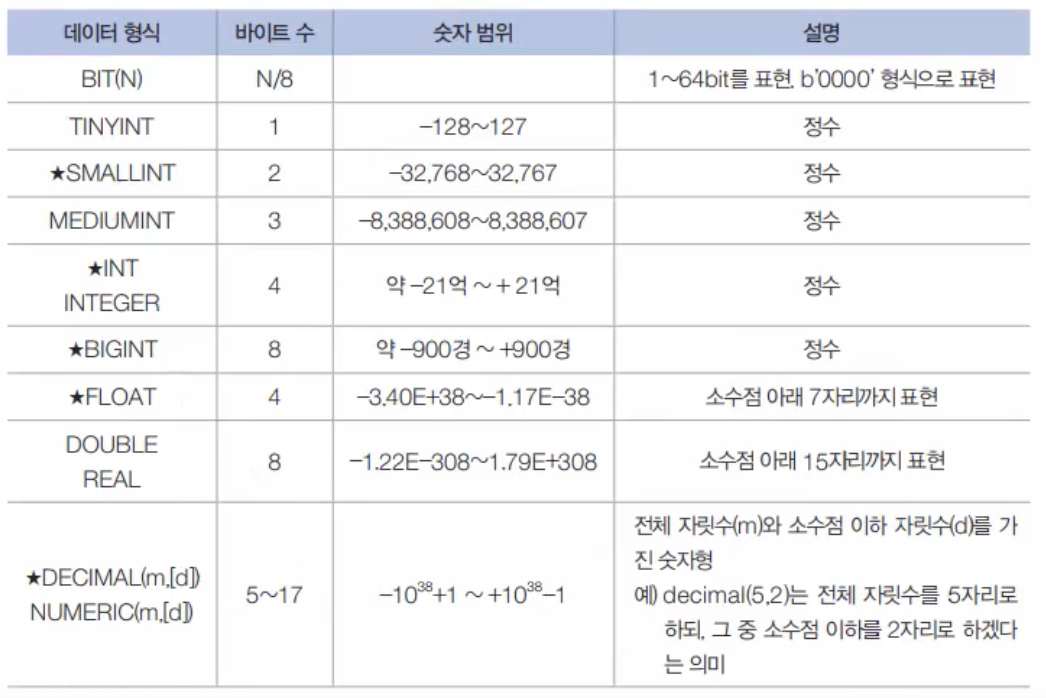
앞에서 SELECT/INSERT/UPDATE/DELETE문에 대해서 살펴보았다. 이제는 지금까지 은연 중에 계속 사용했지만 특별히 얘기하지 않았던 MySQL의 데이터 형식(Data Type)에 대해서 살펴보겠다. Data Type은 데이터 형식, 데이터형, 자료형, 데
12.14. MySQL SQL 고급 - 데이터형 변환, 내장 함수
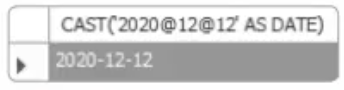
데이터 형식 변환 함수가장 일반적으로 사용되는 데이터 형식 변환과 관련해서는 CAST(), CONVERT() 함수를 사용한다. CAST(), CONVERT()는 형식만 다를 뿐 거의 비슷한 기능을 한다.데이터 형식 중에서 가능한 것은 BINARY, CHAR, DATE,
13.15. MySQL SQL 고급 - 영화사이트대용량 데이터 구축 실습
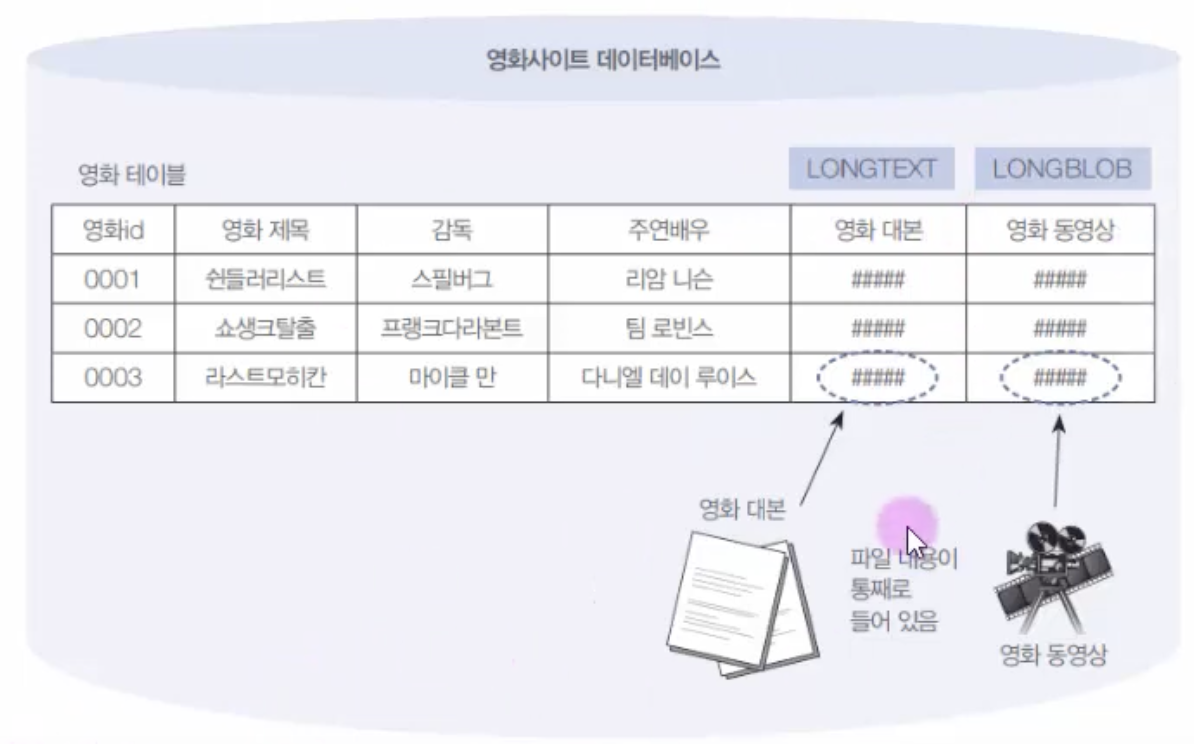
그림 구성하는 실습.\-> 대본, 동영상 다운로드NULL값으로 입력이 안된 것을 확인할 수 있음. 1.시스템 변수인 maxallowedpacket 변수가 기본값이(4MG) 너무 작기 때문. 2.그리고 폴더가 보안상 허용이 되어야 함.(보안상 그렇게 세팅 되어 있음)약
14.16. MySQL SQL 고급 - 피벗, JSON
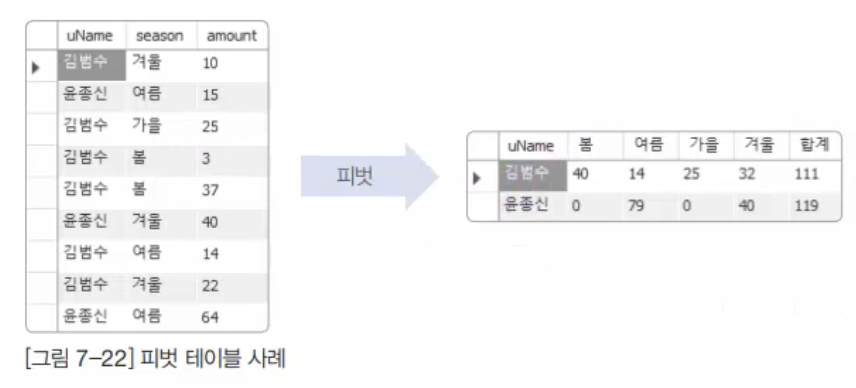
피벗의 구현피벗(Pivot)은 한 열에 포함된 여러 값을 출력하고, 이를 여러 열로 변환하여 테이블 반환 식을 회전하고 필요하면 집계까지 수행하는 것을 말한다.왼쪽은 판매자 이름, 판매 계절, 판매 수량으로 구성된 테이블이다. 이를 각 판매자가 계절별로 몇 개 구매했는
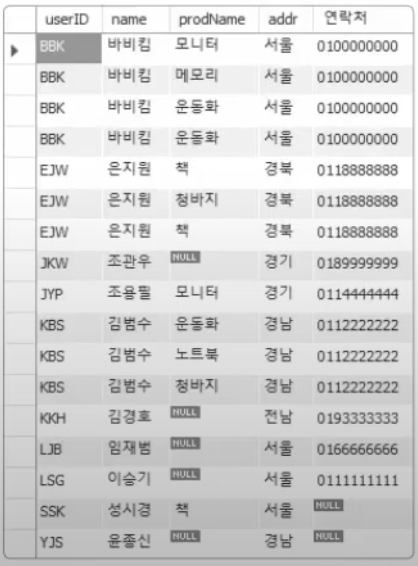
15.17. MySQL SQL 고급 - 조인 개념과 Inner Join
지금까지 우리는 대개 하나의 테이블을 다루는 작업을 위주로 수행했다. 이를 기반으로 해서 지금부터는 두 개이상의 테이블이 서로 관계되어 있는 상태를 고려해 보자.조인이란 두 개 이상의 테이블을 서로 묶어서 하나의 결과 집합으로 만들어 내는 것을 말한다.\*조인을 이해하
16.18. MySQL SQL 고급 - Outer, Cross, Self Join 및 Union
OUTER JOIN(외부 조인) Outer join은 조인의 조건에 만족되지 않는 행까지도 포함시키는 것.
17.19. MySQL SQL 고급 - SQL 프로그래밍
지금 익히는 것은 특히 나중에 배우는 스토어드 프로시저, 스토어드 함수, 커서, 트리거 부분의 기본이 되므로 잘 알아두자. SQL에서도 다른 프로그래밍 언어와 비슷한 분기, 흐름 제어, 반복의 기능이 있다. 이러한 기능을 전에 소개했던 변수와 함께 잘 활용한다면 강력한
18.20. MySQL 테이블과 뷰 - Workbench에서 테이블 생성
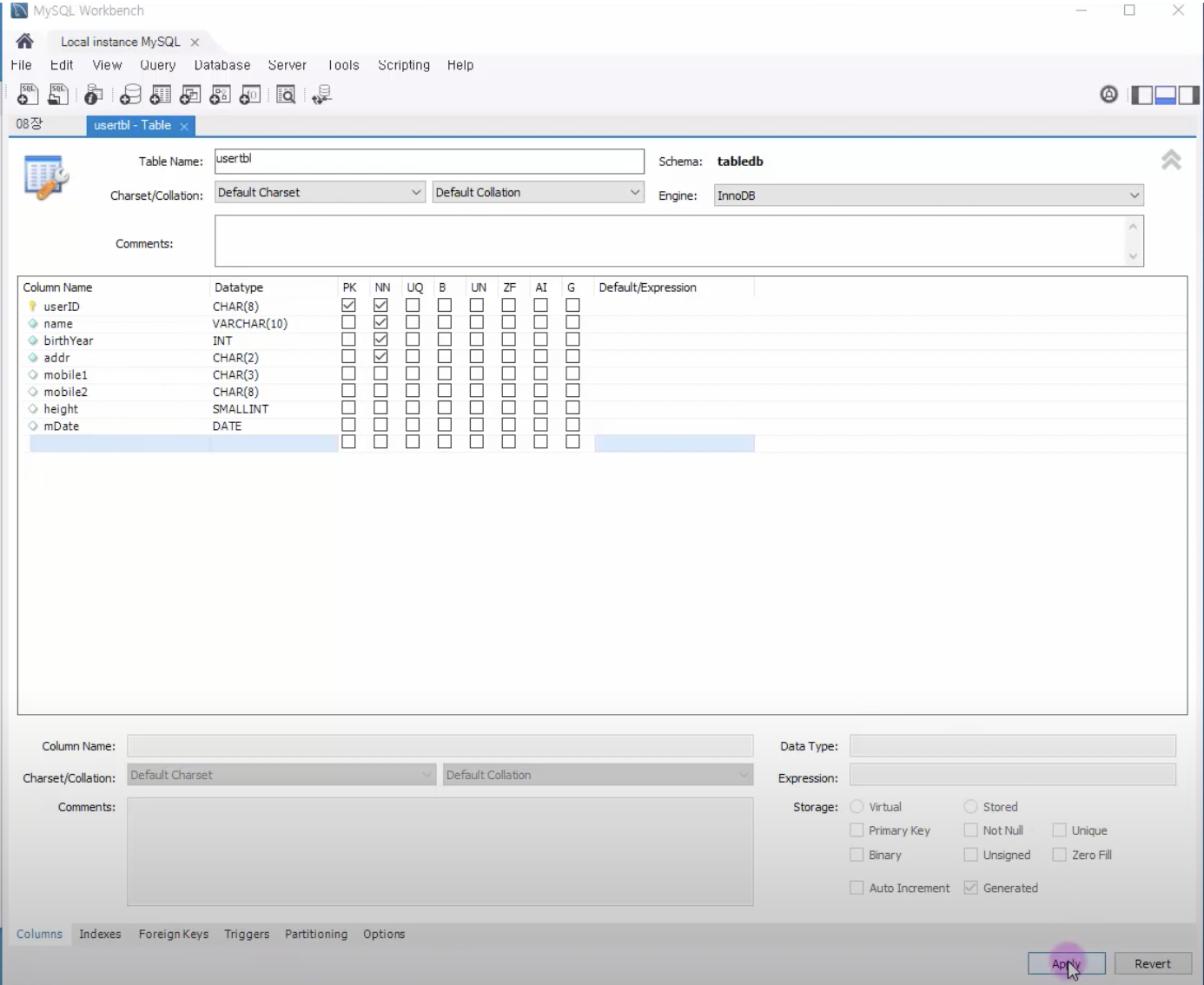
테이블 테이블의 생성 및 사용은 지금까지 계속 반복해 왔다. 별다른 설명을 하지 않았어도 사용에 별로 어려움을 느끼지 못했을 것이다. 다시 한번 확인 차원에서 간단히 테이블을 생성해 보고, 제약 조건 및 테이블의 수정에 대해서 자세히 알아보자. 테이블 만들기 MySQ
19.21. MySQL 테이블과 뷰 - SQL문으로 테이블 생성
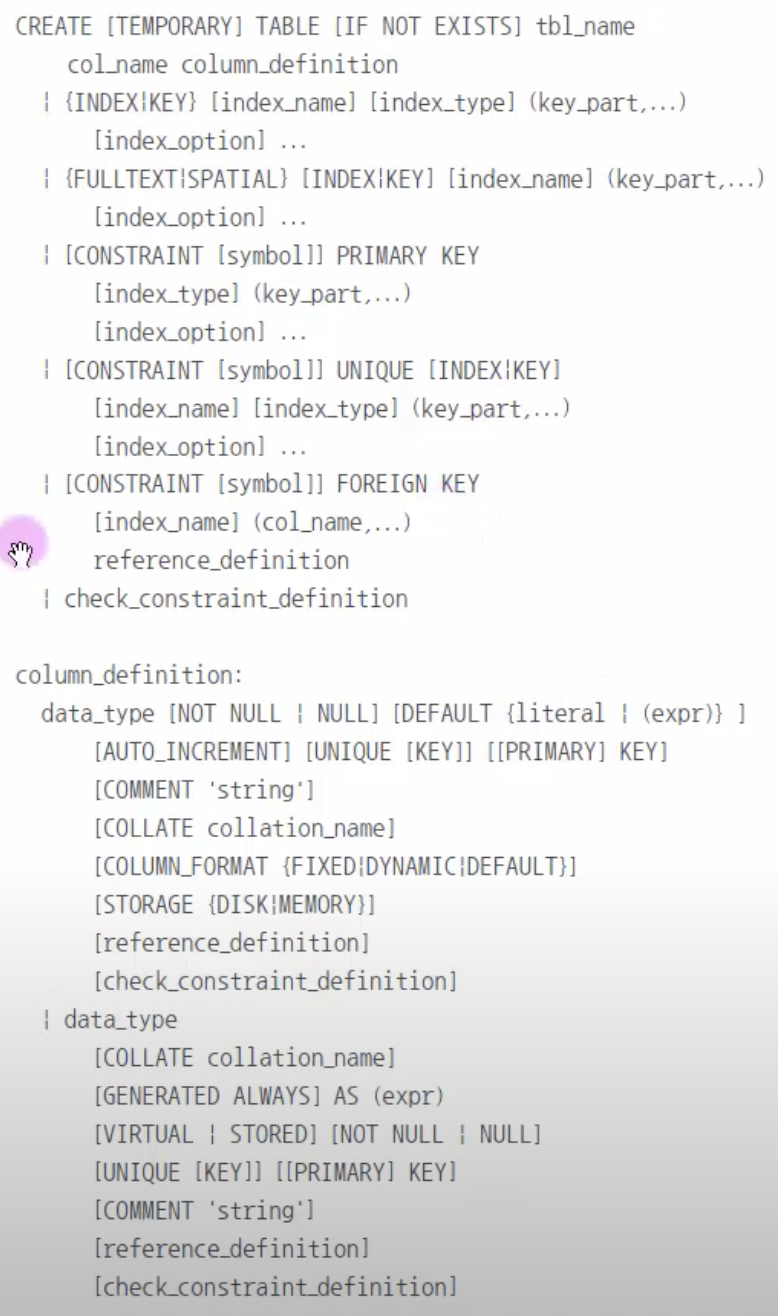
MySQL 도움말에 나오는 테이블을 생성하는 기본적인 형식은 다음과 같다.일부만 써놓은 것이고 실제는 좀 더 복잡여기에 NOT NULL 추가하기근데 전화번호가 없는 사람도 회원가입을 하게 해줌.없어도 되는 사람은 NULL 입력이번에는 기본키 설정buytbl의 num에
20.22. MySQL 테이블과 뷰 - 제약조건기본키, 외래키
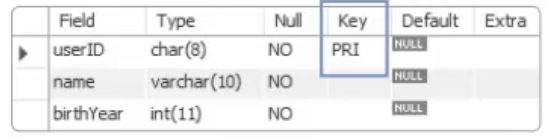
샘플로 사용할 tabledb데이터의 무결성을 지키기 위한 제한된 조건을 의미한다. 즉, 특정 데이터를 입력할 때 무조건적으로 입력되는 것이 아닌, 어떠한 조건을 만족했을 때에 입력되도록 제약할 수 있다.간단한 예로, 인터넷 쇼핑몰에 회원 가입을 해본 경험이 있을 것이다
21.23. MySQL 테이블과 뷰 - 제약조건Unique, Check 등 및 테이블 압축, 임시테이블
UNIQUE 제약 조건 '중복되지 않는 유일한 값'을 입력해야 하는 조건이다. 이것은 PRIMARY KEY와 거의 비슷하며 차이점은 UNIQUE는 NULL 값을 허용한다는 점이다. NULL은 여러 개가 입력되어도 상관 없다. 회원 테이블의 예를 든다면 주로 Email
22.24. MySQL 테이블과 뷰 - 테이블 삭제, 수정 및 제약조건 전체 실습
테이블 삭제 단 주의할 사항은 외래 키(FOREIGN KEY) 제약 조건의 기준 테이블은 삭제할 수가 없다. 먼저, 외래 키가 생성된 외래 키 테이블을 삭제해야 한다. 구매 테이블(buytbl)이 아직 존재하는데, 회원 테이블(usertbl)을 삭제할 수 없다. 먼저
23.25. MySQL 테이블과 뷰 - 뷰의 개념과 실습
일반 사용자 입장에서는 테이블과 동일하게 사용하는 개체다. 뷰는 한 번 생성해 놓으면 테이블이라고 생각하고 사용해도 될 정도로 사용자들의 입장에서는 테이블과 거의 동일한 개체로 여겨진다.쿼리 창에서 SELECT문을 수행해서 나온 결과를 생각해 보자.SELECT에서 아이
24.26. MySQL 테이블과 뷰 - 테이블스페이스
소용량의 데이터를 다룰 때는 테이블이 저장되는 물리적 공간인 '테이블스페이스 Tablespace'에 대해서 별로 신경쓰지 않아도 되지만, 대용량의 데이터를 다룰 때는 성능 향상을 위해서 테이블스페이스에 대한 설정을 하는 것이 좋다.데이터베이스가 테이블이 저장되는 논리
25.27. MySQL 인덱스 - 인덱스의 개념, 자동으로 생성되는 인덱스
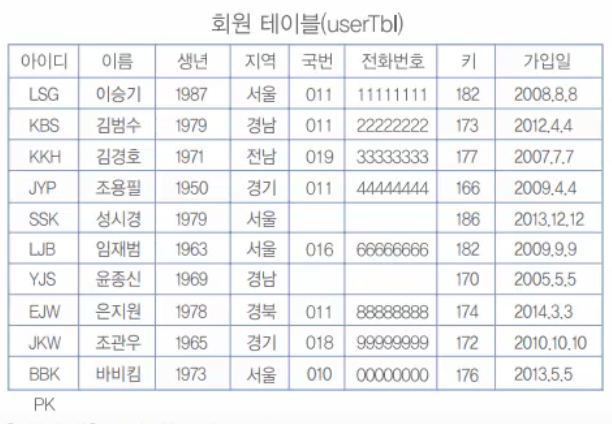
인덱스는 SELECT 검색을 할 때 굉장히 빠르게 찾아줄 수 있다. 그래서 대용량 데이터에서 쓰면 좋다. 소용량 데이터에서 쓰면 오히려 안좋을 수 있다. 또 SELECT는 빠를 수 있지만 INSERT, UPDATE, DELETE 작업은 더 느려질 수 있다.인덱스는 튜닝
26.28. MySQL 인덱스 - 인덱스의 내부작동1
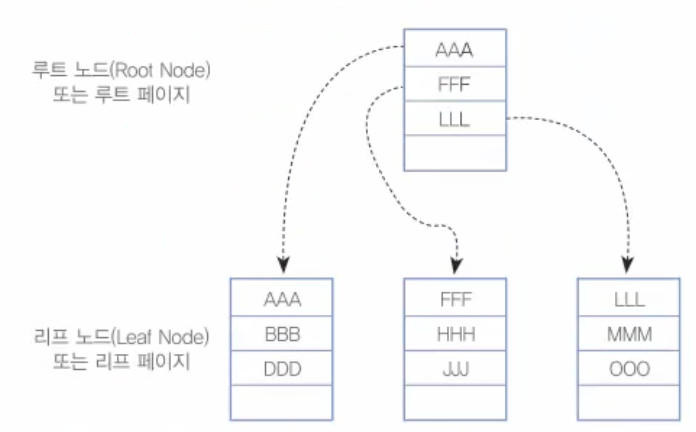
인덱스의 내부적인 작동을 이해하기 위해서는 우선 몇 가지 개념의 정립이 필요하다.B-Tree는 '자료 구조'에 나오는 범용적으로 사용되는 데이터의 구조다. 이 구조는 주로 인덱스를 표현할 때와 그 외에서도 많이 사용된다. 이름에서도 알 수 있듯이 B-Tree는 균형이
27.29. MySQL 인덱스 - 인덱스의 내부작동2
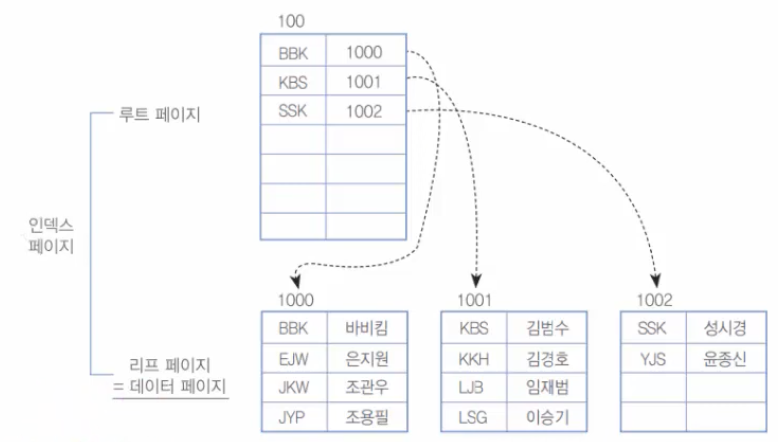
그림 9-17 클러스터형 인덱스의 구성 후우선 클러스터형 인덱스에서 검색해 보자. 만약 JKW(조관우)를 검색한다면 단순히 몇 개 페이지를 읽을 것인가? 루트 페이지(100번)와 리프 페이지(=데이터 페이지, 1000번) 한 개씩만 검색하면 된다. 총 2개 페이지를 읽
28.30. MySQL 인덱스 - 인덱스 실습과 결론
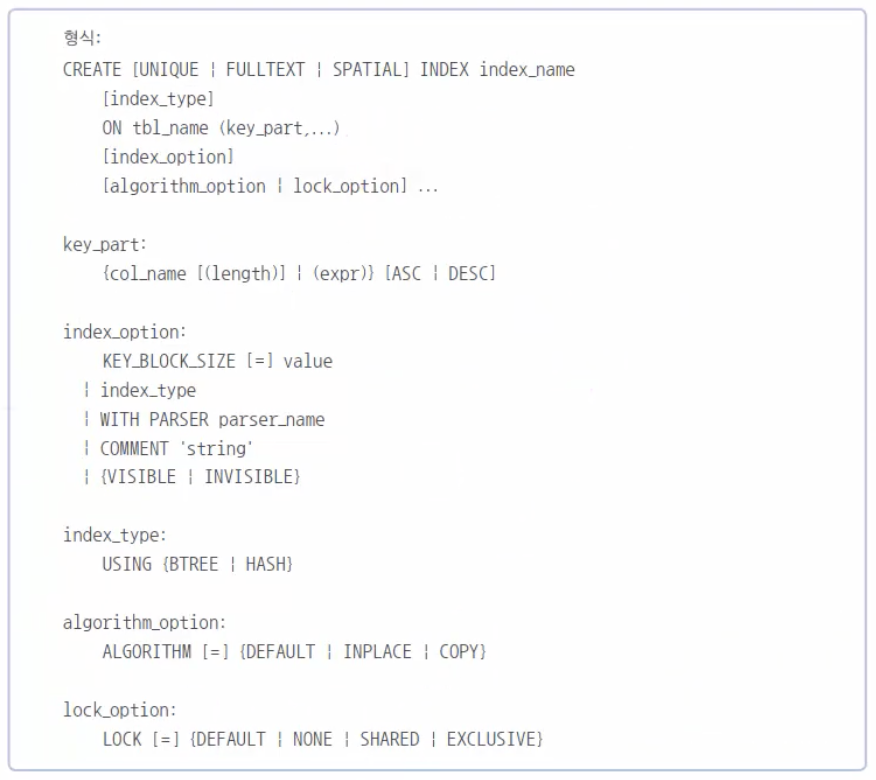
이제는 제약 조건에서 자동으로 생성되는 인덱스 외에 직접 인덱스를 생성하는 구문을 살펴보자.CREATE INDEX문으로는 Primary Key로 생성되는 클러스터형 인덱스를 만들 수는 없다. 만약, 클러스터형 인덱스를 생성하려면 앞에서 했던 것처럼 ALTER TABLE
29.31. MySQL 스토어드 프로그램 - 스토어드 프로시저
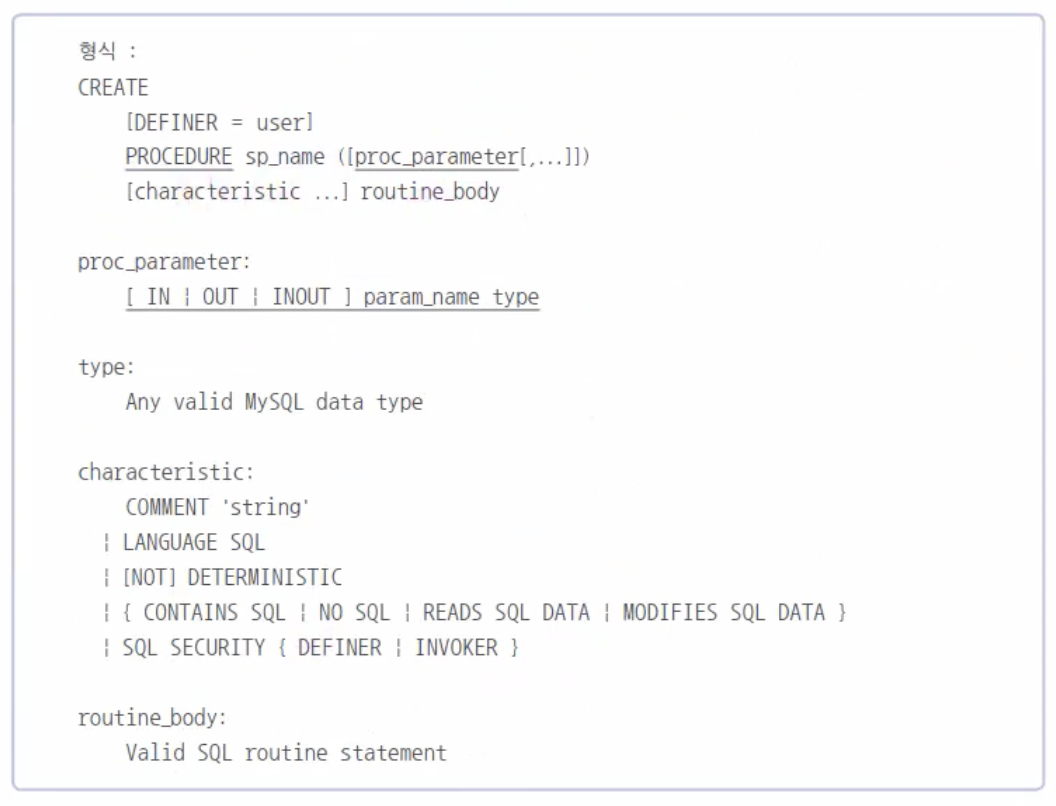
스토어드 프로시저(Stored Procedure, 저장 프로시저)란 MySQL에서 제공되는 프로그래밍 기능이라고 생각하면 된다. 이것은 일반적인 프로그래밍과는 조금 차이가 있지만 MySQL 내부에서 사용하기 위해서는 아주 적절한 방식을 제공해 준다.한마디로 쿼리문의 집
30.32. MySQL 스토어드 프로그램 - 스토어드 함수, 커서
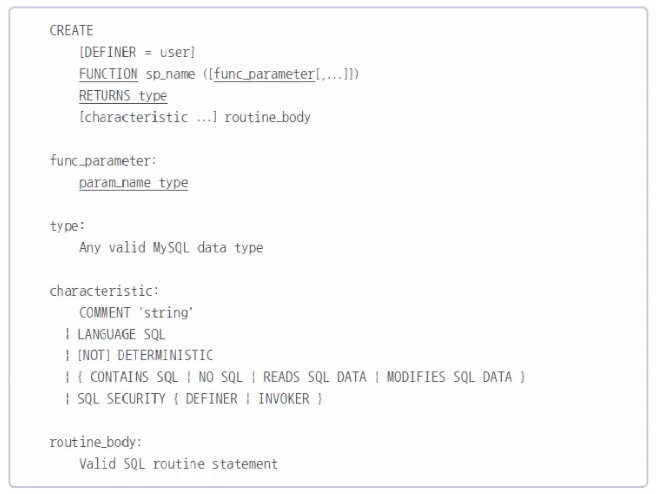
MySQL이 사용자가 원하는 모든 함수를 제공하지는 않으므로 필요하다면 사용자가 직접 함수를 만들어서 사용할 필요가 있다. 이렇게 사용자가 직접 만들어서 사용하는 함수를 스토어드 함수라고 부른다. 스토어드 함수는 바로 앞에서 배운 스토어드 프로시저와 상당히 유사하지만,
31.33. MySQL 스토어드 프로그램 - 트리거 개념과 실습

트리거 트리거는 사전적 의미로 '방아쇠'를 뜻한다. 방아쇠를 당기면 '자동'으로 총알이 나가듯이, 트리거는 테이블에 무슨 일이 일어나면 '자동'으로 실행된다. 트리거는 기본적인 개념만 잘 파악하고 있다면 사용이 그다지 어렵지 않지만, 몇 가지 주의해야 할 점이 있다.
32.34. MySQL 스토어드 프로그램 - 트리거 임시 테이블, 중첩 트리거
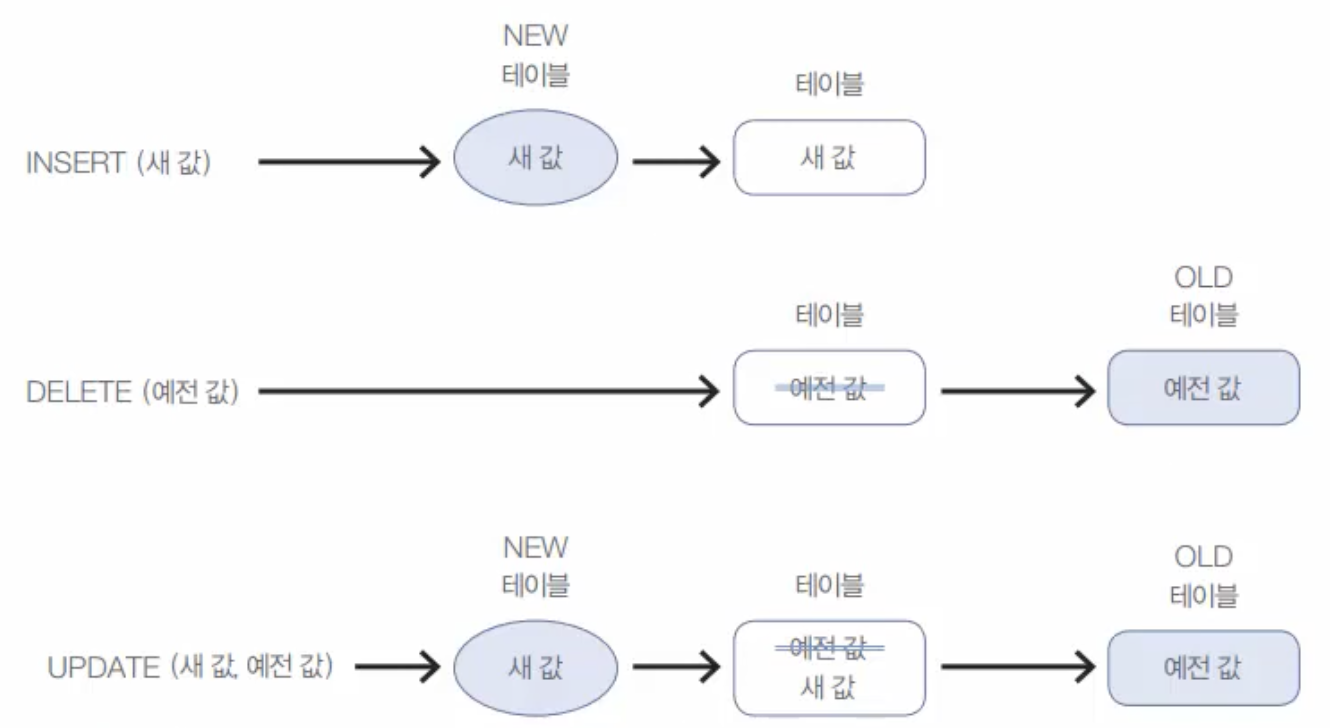
트리거가 생성하는 임시 테이블트리거에서 INSERT, UPDATE, DELETE 작업이 수행되면 임시로 사용되는 시스템 테이블이 두 개 있는데, 이름은 'NEW'와 'OLD'이다. 두 테이블은 그림 10-15와 같이 작동한다.그림 10-15 트리거의 NEW와 OLD 테
33.35. MySQL 전체 텍스트 검색과 파티션 - 전체텍스트검색 개념과 실습
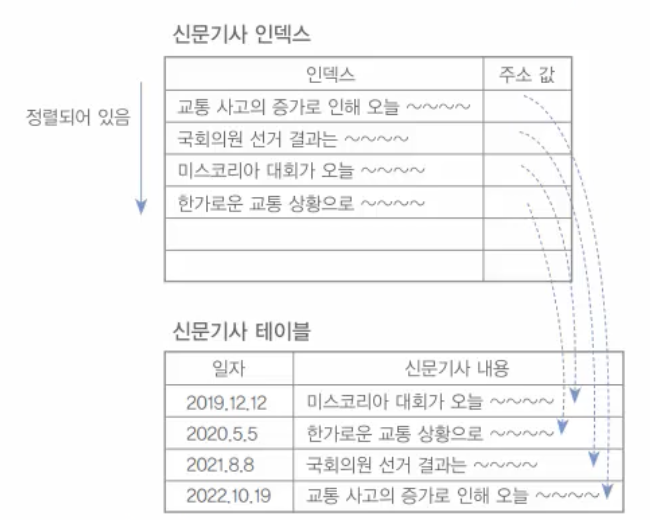
전체 텍스트 검색은 긴 문자로 구성된 구조화되지 않은 텍스트 데이터(예로, 신문 기사) 등을 빠르게 검색하기 위한 부가적인 MySQL의 기능이다.전체 텍스트 검색은 저장된 텍스트의 키워드 기반의 쿼리를 위해서 빠른 인덱싱이 가능하다.그림 11-1 신문기사 테이블과 신문
34.36. MySQL 전체 텍스트 검색과 파티션 - 파티션 개념과 실습
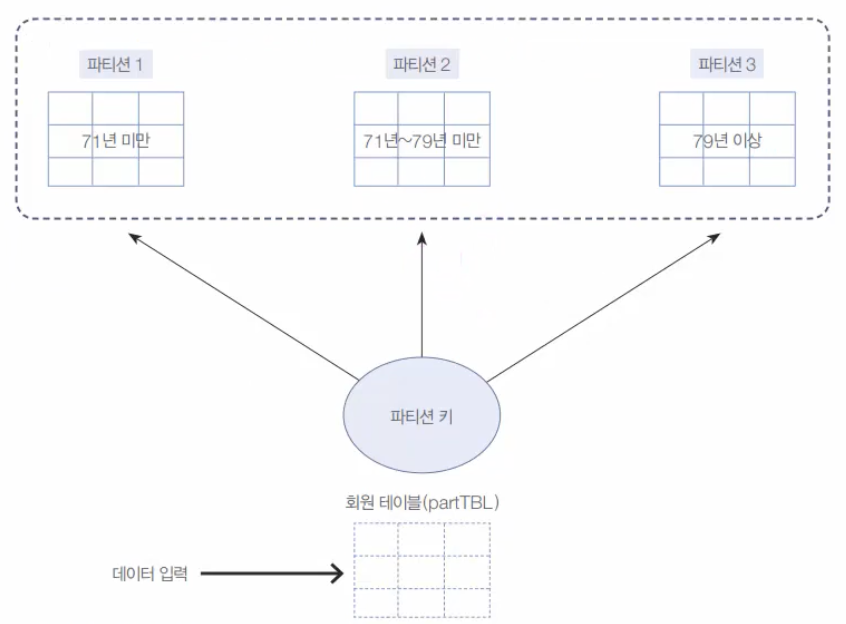
파티션은 대량의 테이블을 물리적으로 여러 개의 테이블로 쪼개는 것을 말한다. 예로 수십억 건의 테이블에 쿼리를 수행할 때, 비록 인덱스를 사용한다고 해도 테이블의 댜용량으로 인해서 MySQL에 상당한 부담이 될 수밖에 없다.이럴 때, 하나의 테이블이 10개의 파티션으로
35.37. MySQL PHP 기본 - 웹 개발환경 구축
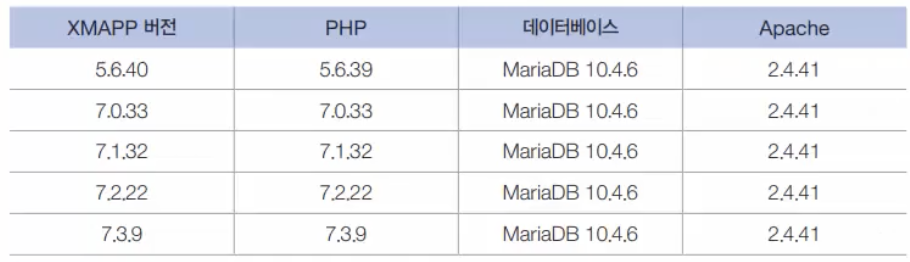
04 MySQL 응용 프로그래밍 및 공간 데이터chapter 12 PHP 기본 프로그래밍chapter 13 PHP와 MySQL의 연동chapter 14 MySQL과 공간데이터chapter 15 파이썬과 MySQL 응용 프로그래밍웹 사이트를 구축하기 위해 웹 서버, 데이
36.38. MySQL PHP 기본 - HTML 태그, PHP 기초문법
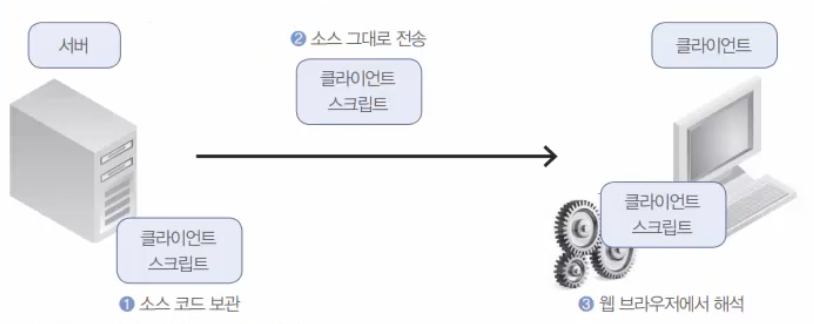
일반적으로 HTML만을 사용해도 간단한 홈페이지를 만들 수 있다. HTML을 사용해서 작성된 사이트를 정적인 웹 사이트(static web site)라고 부른다. '정적'의 의미가 고정되고 변화가 없다는 의미를 갖듯이 한번 HTML로 코딩해 놓으면 별도의 변경이 없이
37.39. MySQL PHP 기본 - PHP 문법 및 내장 함수

if() 함수조건에 따라서 분기하는 if() 함수는 다음의 형식을 갖는다. 다음 형식에서 else{} 부분은 생략할 수 있다.조건식의 결과는 TRUE 또는 FALSE가 오는데 주로 비교 연산자인 ==, <>, <, >, <=, >= 등이 사용된다.여러
38.40. MySQL PHP 기본 - HTML과 PHP의 관계
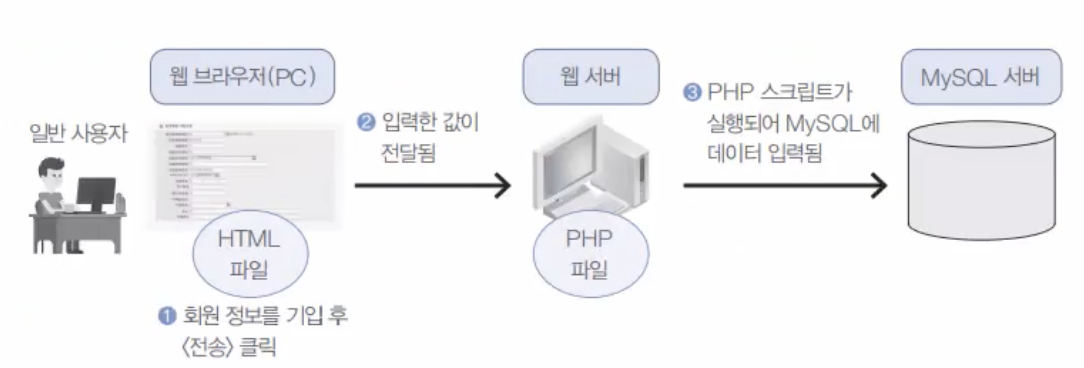
HTML과 PHP 데이터 전송 개념chapter 11까지는 데이터의 입력/수정/삭제를 위해서 직접 SQL문 INSERT/UPDATE/DELETE를 사용해 왔다. 하지만, 사용자가 데이터의 조회나 수정을 위해서 이러한 SQL문을 배울 수는 없다.예로 쇼핑몰에 회원 가입하
39.41. PHP와 MySQL 연동 - 기본 연동 방법
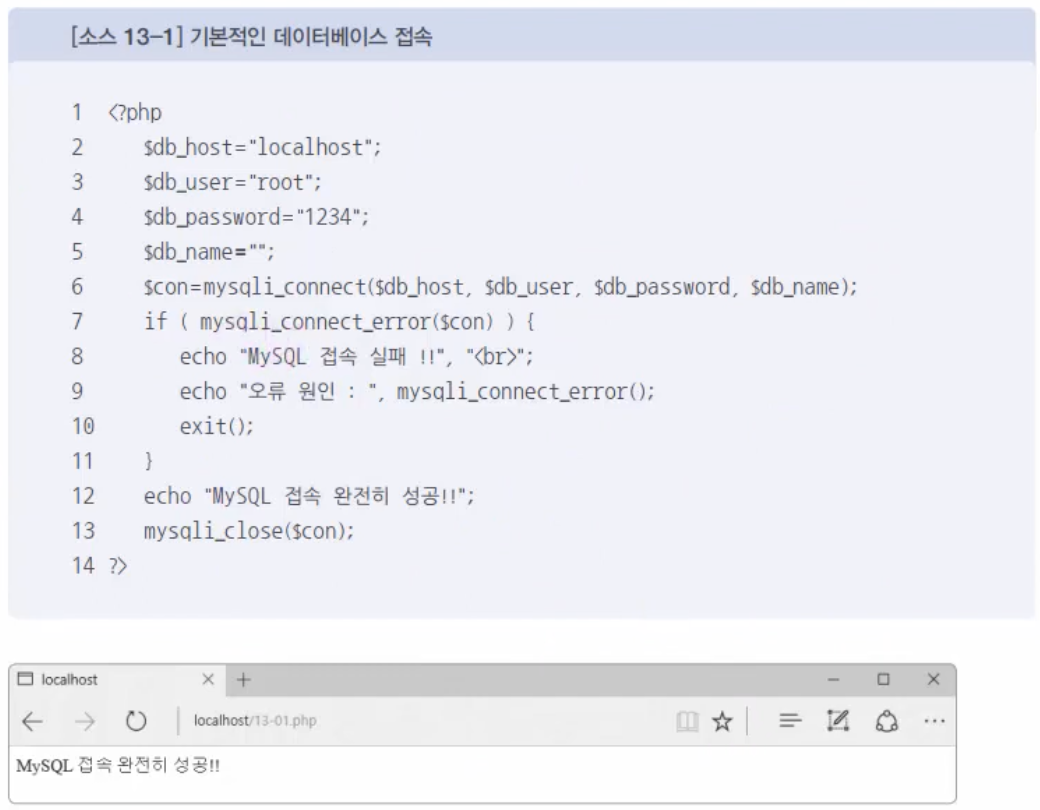
가장 기본적인 DB 접속을 확인해 보자.2행~5행에 서버 주소, DB 사용자, 비밀번호, 접속할 DB 등을 변수에 지정해 놓았다. 그리고 6행에서 각 변수에 들어 있는 내용으로 mysqli_connect() 함수로 접속을 시도했다. 접속된 결과를 $con에 저장해 놓았
40.42. PHP와 MySQL 연동 - 회원 관리 시스템 구현
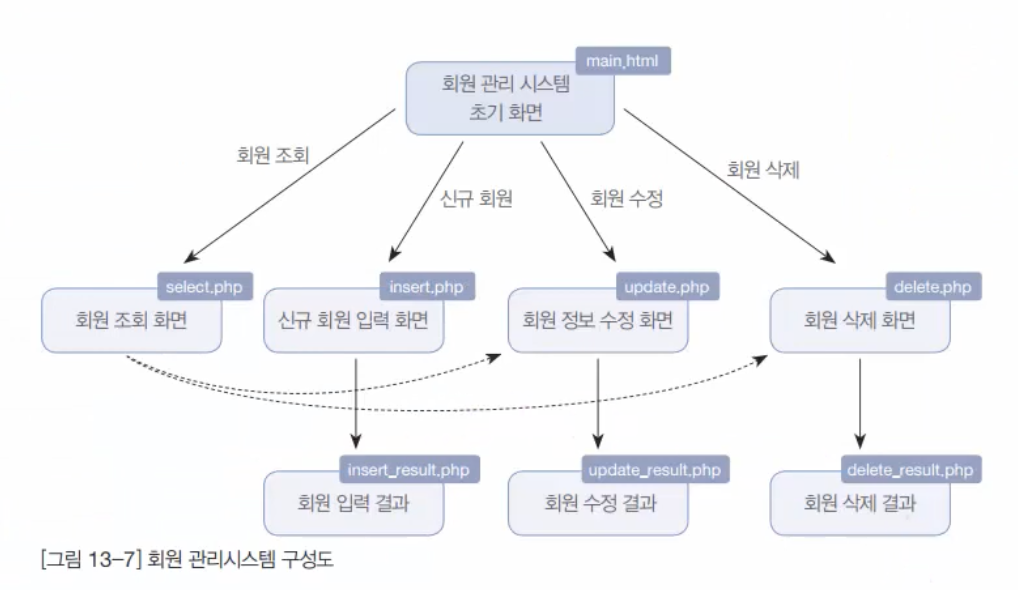
앞에서 PHP에서 데이터베이스의 생성 및 테이블 생성, 데이터 입력, 데이터 조회에 대해서 모두 알아보았다. 이제는 이렇게 단편적으로 학습한 내용을 종합해서 간단한 회원 관리시스템을 만들어 보자.회원 관리시스템은 회원의 조회/입력/수정/삭제를 웹 상에서 처리하는 응용
41.43. MySQL - GIS 개념과 MySQL의 공간데이터
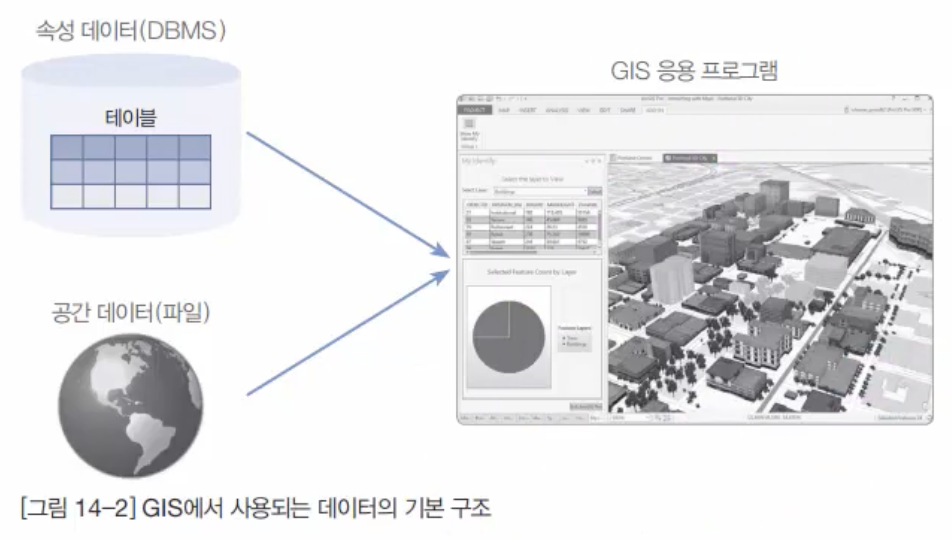
지리정보시스템(GIS, Geographical Information System)이란지표면과 지상공간에 존재하고 있는 각종 자연물(산,강,토지 등)과 인공물(건물,도로,철도 등)에 대한 위치 정보와 속성 정보를 컴퓨터에 입력 후, 이를 연계시켜 각종 계획 수립과 의사