스토어드 함수
MySQL이 사용자가 원하는 모든 함수를 제공하지는 않으므로 필요하다면 사용자가 직접 함수를 만들어서 사용할 필요가 있다. 이렇게 사용자가 직접 만들어서 사용하는 함수를 스토어드 함수라고 부른다. 스토어드 함수는 바로 앞에서 배운 스토어드 프로시저와 상당히 유사하지만, 형태와 사용용도에는 약간의 차이가 있다.
- 다른 DBMS에서는 스토어드 프로시저를 '저장 프로시저'로, 스토어드 함수를 '사용자 정으 ㅣ함수'라고도 부른다.
스토어드 함수의 개요
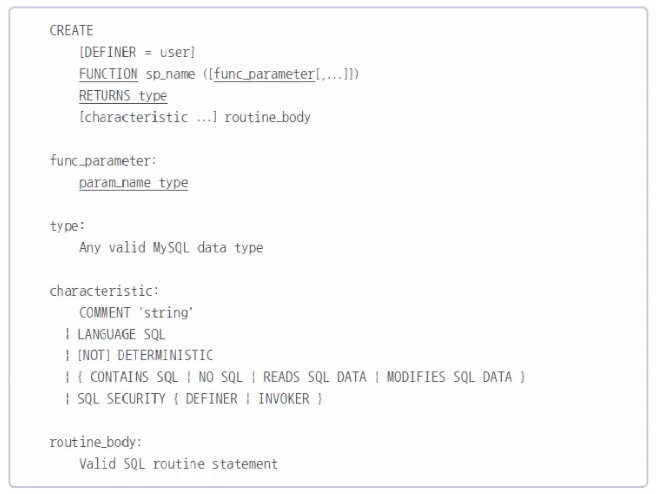
다음과 같이 좀더 간단하게 표현할 수 있다.

스토어드 함수의 정의를 보면 스토어드 프로시저와 상당히 유사하다. 차이점을 몇 가지 살펴보면 다음과 같다.
- 스토어드 프로시저의 파라미터와 달리 IN, OUT등을 사용할 수 없다. 스토어드 함수의 파라미터는 모두 입력 파라미터로 사용된다.
- 스토어드 함수는 RETURNS문으로 변환할 값의 데이터 형식을 지정하고, 본문 안에서는 RETURN문으로 하나의 값을 반환해야 한다. 스토어드 프로시저는 별도의 반환하는 구문이 없으며, 꼭 필요하다면 여러 개의 OUT 파라미터를 사용해서 값을 반환할 수 있었다.
- 스토어드 프로시저는 CALL로 호출하지만, 스토어드 함수는 SELECT 문장 안에서 호출된다.
- 스토어드 프로시저 안에는 SELECT문을 사용할 수 있지만, 스토어드 함수 안에서는 집합 결과를 반환하는 SELECT를 사용할 수 없다.
- SELECT...INTO...는 집합 결과를 반환하는 것이 아니므로, 예외적으로 스토어드 함수에 사용할 수 있다.
- 스토어드 프로시저는 여러 SQL문이나 숫자 계산 등의 다양한 용도로 사용되지만, 스토어드 함수는 어떤 계산을 통해서 하나의 값을 반환하는데 주로 사용된다.
스토어드 함수를 사용하기 위해서는 먼저 다음 쿼리문으로 스토어드 함수 생성 권한을 허용해줘야 한다.
SET GLOBAL log_bin_trust_function_creators = 1;간단히 2개의 숫자의 합계를 계산하는 스토어드 함수를 보자.
USE sqlDB;
DROP FUNCTION IF EXISTS userFunc;
DELIMITER $$
CREATE FUNCTION userFunc(value1 INT, value2 INT)
RETURNS INT
BEGIN
RETURN value1 + value2;
END $$
DELIMITER;
SELECT userFunc(100,200);<실습>
스토어드 함수를 사용해 보자.
출생년도를 입력받아서 현재나이를 반환하는 함수를 만들어보자.
SET GLOBAL log_bin_trust_function_creators = 1;
USE sqlDB;
DROP FUNCTION IF EXISTS getAgeFunc;
DELIMITER $$
CREATE FUNCTION getAggeFunc(bYear INT)
RETURNS INT
BEGIN
DECLARE age INT;
SET age = YEAR(CURDATE()) - bYear;
RETURN age;
END $$
DELIMITER;
SELECT getAgeFunc(1979);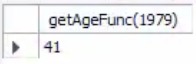
함수의 결과를 변수로 저장할 수도 있음.
SELECT getAgeFunc(1979) INTO @age1979;
SELECT getAgeFunc(1997) INTO @age1989;
SELECT CONCAT('1997년과 1979년의 나이차 ==> ', (@age1979-@age1989));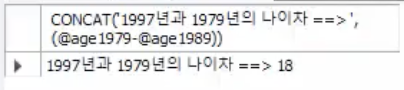
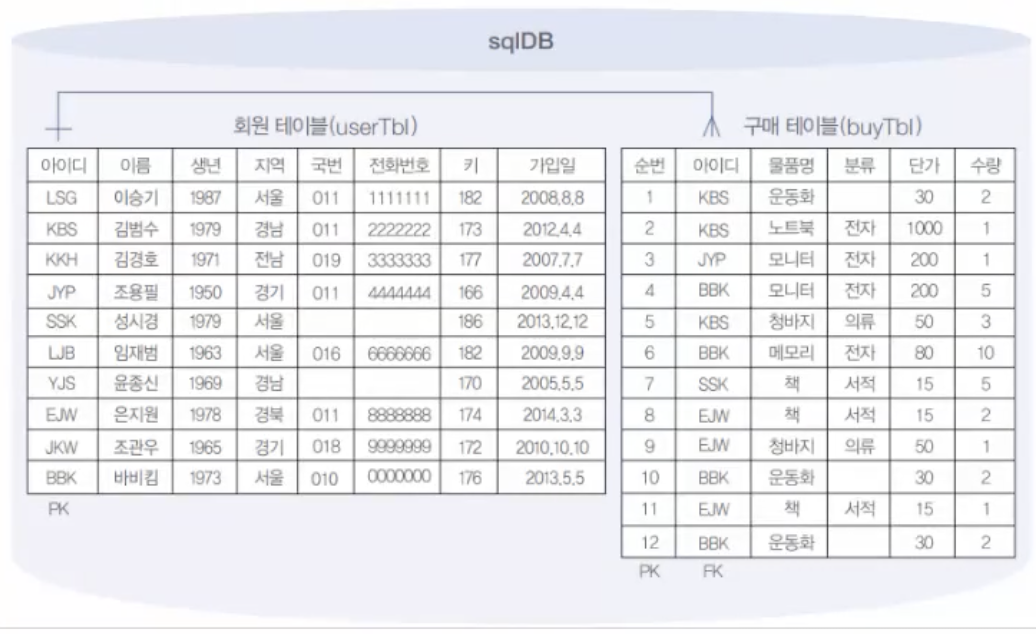
SELECT userID, name, getAgeFunc(birthYear) AS '만 나이' FROM userTbl;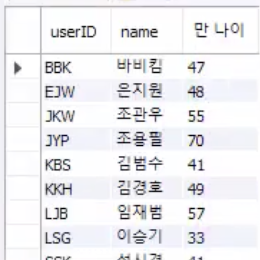
SHOW CREATE FUNCTION getAgeFunc;
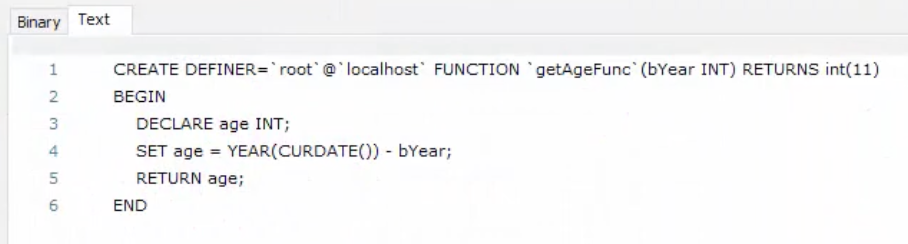
DROP FUNCTION getAgeFunc;커서
MySQL은 스토어드 프로시저 내부에 커서를 사용할 수 있다. 커서는 일반 프로그래밍 언어의 파일 처리와 방법이 비슷하기 때문에, 행의 집합을 다루기에 편리한 기능을 많이 제공해 준다.
커서의 개요
커서는 테이블에서 여러 개의 행을 쿼리한 후에, 쿼리의 결과인 행 집합을 한 행씩 처리하기 위한 방식이다. 혹, '파일 처리' 프로그래밍을 해본 독자라면 파일을 읽고 쓰기 위해서 파일을 오픈한 후에, 한 행씩 읽거나 썼던 것을 기억할 것이다. 한 행씩 읽을 때마다 '파일 포인터'는 자동으로 다음줄을 가리킨다. 커서도 이와 비슷한 동작을 한다.
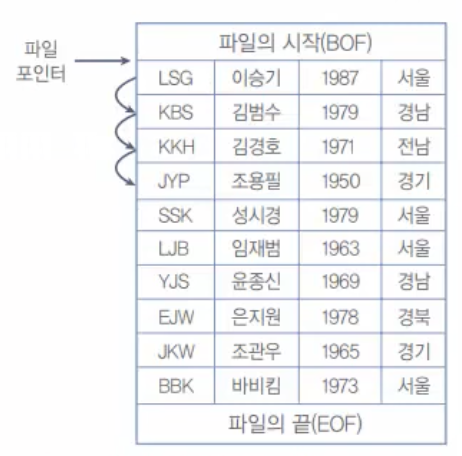
[그림 10-8] 파일 처리의 작동 개념
예를 들어 [그림 10-8]과 같은 텍스트 파일이 저장되어 있다고 생각해 보자. 이 파일을 처리하기 위해서는 다음의 순서를 거치게 될 것이다.
1. 파일을 연다. (Open) 그러면 파일 포인터는 파일의 제일 시작 (BOF: Begin Of File)을
2. 처음 데이터를 읽는다. 그러면 '이승기'의 데이터가 읽어지고, 파일 포인터는 '김범수'로 이동한다.
3. 파일의 끝(EOF: End Of File)까지 반복한다.
[그림 10-8]의 텍스트 파일을 이제는 테이블의 행 집합으로 생각해 보자. 커서를 활용하면 거의 비슷한 방식으로 처리가 가능하다. 먼저 커서의 처리 순서를 확인하고 실습을 진행하자.
커서의 처리 순서
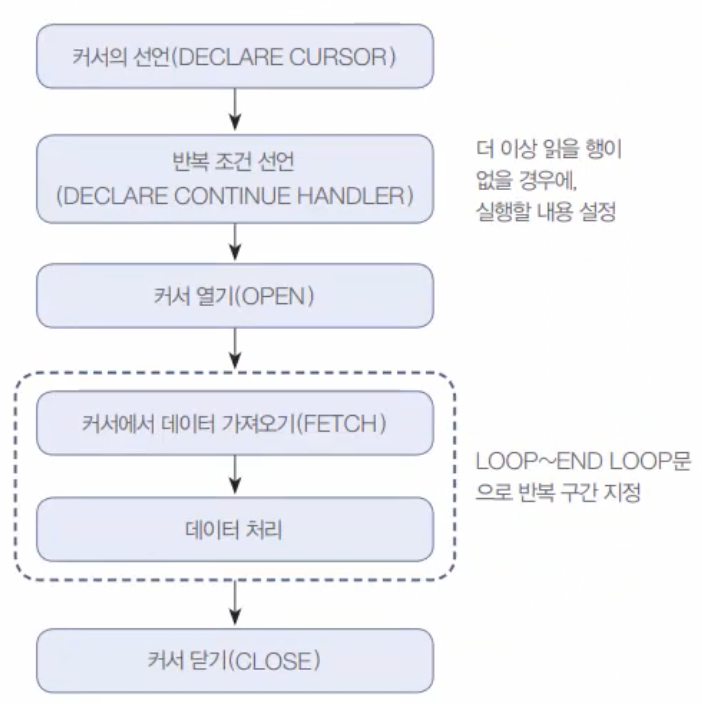
[그림 10-9] 커서의 작동 순서
커서를 하나씩 이해하기보다는 우선 간단한 예제로 커서를 사용해 보자. 커서는 대부분 스토어드 프로시저의 내용으로 활용된다. 커서의 세부 문법을 외우기보다는 [그림 10-9]와 같이 커서를 사용하는 전반적인 흐름에 초점을 맞춰서 실습을 진행하도록 하자.
<실습>
DROP PROCEDURE IF EXISTS cursorProc;
DELIMITER $$
CREATE PROCEDURE cursorProc()
BEGIN
DECLARE userHeight INT; -- 고객의 키
DECLARE cnt INT DEFAULT 0; -- 고객의 인원 수 (=읽은 행의 수)
DECLARE totalHeight INT DEFAULT 0; -- 키의 합계
DECLARE endOfRow BOOLEAN DEFAULT FALSE; -- 행의 끝 여부(기본을 FALSE)
DECLARE userCuror CURSOR FOR -- 커서 선언
SELECT height FROM userTbl;
DECLARE CONTINUE HANDLER -- 행의 끝이면 endOfRow 변수에 TRUE를 대입
FOR NOT FOUND SET endOfRow = TRUE;
OPEN userCuror; -- 커서 열기
cursor_loop: LOOP
FETCH userCuror INTO userHeight; -- 고객 키 1개를 대입
IF endOfRow THEN -- 더이상 읽을 행이 없으면 LOOP를 종료
LEAVE cursor_loop;
END IF;
SET cnt = cnt + 1;
SET totalHeight = totalHeight + userHeight;
END LOOP cursor_loop;
-- 고객 키의 평균을 출력한다.
SELECT CONCAT('고객 키의 평균 ==> ', (totalHeight/cnt));
CLOSE userCuror; -- 커서 닫기
END $$
DELIMITER;
CALL cursorProc();
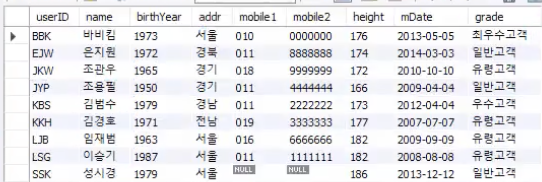
ALTER TABLE userTbl ADD grade VARCHAR(5); -- 고객 등급 열 추가
DROP PROCEDURE IF EXISTS gradeProc;
DELIMITER $$
CREATE PROCEDURE gradeProc()
BEGIN
DECLARE id VARCHAR(10); -- 사용자 아이디를 저장할 변수
DECLARE hap BIGINT; -- 총 구매액을 저장할 변수
DECLARE userGrade CHAR(5); -- 고객 등급 변수
DECLARE endOfRow BOOLEAN DEFAULT FALSE;
DECLARE userCuror CURSOR FOR -- 커서 선언
SELECT U.userid, sum(price*amount)
FROM buyTbl B
RIGHT OUTER JOIN userTbl U
ON B.userid = U.userid
GROUP BY U.userid, U.name;
DECLARE CONTINUE HANDLER
FOR NOT FOUND SET endOfRow = True;
OPEN userCuror; -- 커서 열기
grade_loop: LOOP
FETCH userCuror INTO id, hap; -- 첫 행 값을 대입
IF endOfRow THEN
LEAVE grade_loop;
END IF;
CASE
WHEN(hap >= 1500) THEN SET userGrade = '최우수고객';
WHEN(hap >= 1000) THEN SET userGrade = '우수고객';
WHEN(hap >= 1) THEN SET userGrade = '일반고객';
ELSE SET userGrade = '유령고객';
END CASE;
UPDATE userTbl SET grade = userGrade WHERE userID = id;
END LOOP grade_loop;
CLOSE userCuror; -- 커서 닫기
END $$
DELIMITER;
CALL gradeProc();
SELECT * FROM userTBL;