붓꽃(iris) 데이터셋
150개의 샘플 데이터, 4개의 특성과 1개의 정답(3개의 품종)으로 구성

문제 정의(목표)
붓꽃 꽃잎의 길이/너비, 꽃받침의 길이/너비 특징을 활용해서 3가지 품종을 분류하는 모델을 만들어보자.knn 모델의 이웃 숫자를 조절해보자. K개수를 조절(하이퍼 파라미터 튜닝)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier #분류
from sklearn.metrics import accuracy_score #정확도 측정train, test를 분리하는 도구
from sklearn.model_selection import train_test_splitbmi실습에서 훈련용 데이터 70%, 테스트용 데이터 30%를 직접 구했지만 해당 라이브러리를 호출함으로써 보다 쉽게 적용할 수 있다.
데이터 불러오기
from sklearn.datasets import load_iris #붓꽃 데이터 불러오기
iris_data = load_iris()
iris_data
#{'data': array([[5.1, 3.5, 1.4, 0.2],
# [4.9, 3. , 1.4, 0.2],
# [4.7, 3.2, 1.3, 0.2],
# [4.6, 3.1, 1.5, 0.2],
# [5. , 3.6, 1.4, 0.2],
# [5.4, 3.9, 1.7, 0.4],.........
#'target_names': array(['setosa', 'versicolor', 'virginica'],....딕셔너리 접근하는 것처럼 활용 가능
sklearn.datasets -> 자료형태 : bunch객체
딕셔너리 데이터 접근 : 인덱싱 가능X , 키 값을 불러서 벨류에 저장
키값들만 확인
iris에 있는 key들
iris_data.keys()
#dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
#data : (필수) 문제 데이터, X, 독립변수, 설명변수, 피처, 특성 다 같은 말
#target : (필수) 값 데이터 ,y, 종속변수, 결과, 실제적 답 다 같은 말
#feature_names : (선택) 문제 데이터의 이름 리스트(컬럼명)
#target_names : (선택) 답 데이터의 이름 리스트
#DESCR : (선택) 자료에 대한 설명data와 target은 필수지만 나머지는 scikit learn에서 제공하는 선택적인 데이터다.
데이터 확인
iris_data['data'].shape
#(150, 4)
sh = iris_data['data'].shape
print(f'행: {sh[0]} 열: {sh[1]}')
#행: 150 열: 4위에서 5번째 행까지 가져오기
iris_data['data'][0:5]
#array([[5.1, 3.5, 1.4, 0.2],
# [4.9, 3. , 1.4, 0.2],
# [4.7, 3.2, 1.3, 0.2],
# [4.6, 3.1, 1.5, 0.2],
# [5. , 3.6, 1.4, 0.2]])특성(문제 데이터) 이름 확인
iris_data['feature_names']
#['sepal length (cm)', 꽃받침 길이 (0열)
#'sepal width (cm)', 꽃받침 너비 (1열)
#'petal length (cm)', 꽃잎의 길이 (2열)
#'petal width (cm)'] 꽃잎의 너비 (3열)답 데이터 확인
iris_data['target']
답 데이터 이름 확인
iris_data['target_names']
#array(['setosa' - 0 , 'versicolor' - 1, 'virginica'] - 2, dtype='<U10')타겟 이름으로 답 데이터 확인하기
iris_data.target_names[iris_data['target']]
설명 확인
DESCR
print(iris_data.DESCR)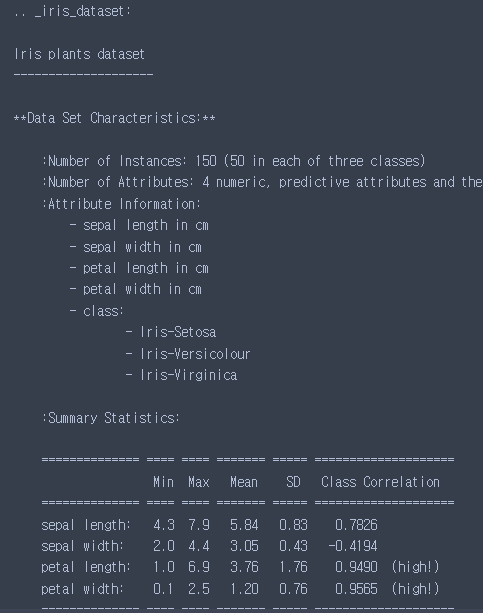
데이터 정리
- 문제 데이터를 DataFrame 형태로 변환(2차원)
- 문제 데이터와 답데이터로 변수 정리(X,y)
- train, test 분리(train_test_split활용)
- X_train, X_test, y_train, y_test
iris_df = pd.DataFrame(iris_data.data, columns = ['sel','sew','petl','petw'])이렇게 해도 DataFrame을 구성할 수 있지만
iris_df = pd.DataFrame(iris_data.data, columns = iris_data.feature_names)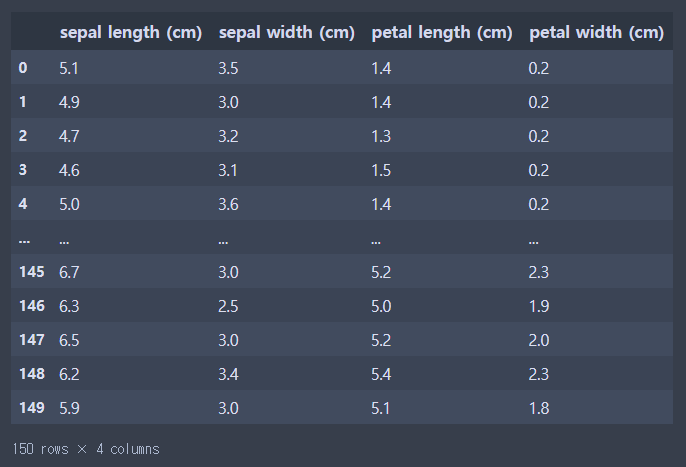
DataFrame 구성 완료
문제와 답
X = iris_df
y = iris_data.target # target 데이터 연결하기확인
print(X.shape, y.shape)
#(150,4) (150,)훈련, 테스트 분리(train_test_split())
트레인 크기 : 0.7(70%), test 크기 : 0.3(30%)
통상적으로 7:3으로 분리하며 비율적인 의미로 넣어주려면 실수형태로,
개수 의미로 넣어주려면 정수형태로 대입한다. shuffle : 섞는 기능 True
random_state : shuffle을 동일한 기준으로 실행
train_test_split(문제, 답, 테스트 사이즈)
train_test_split(X,y,test_size=0.3)
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3, random_state = 1)
#처음 데이터를 분리하고 고정하는 것train, test 분리 완료!
크기 확인
print('훈련용 셋:', X_train.shape, y_train.shape)
print('테스트용 셋:', X_test.shape, y_test.shape)
#훈련용 셋: (105,4) (105,)
#테스트용 셋: (45,4) (45,)분리된 데이터 클래스별 개수 확인하기
7:3 비율 데이터 분리를 했고, 모델 입장에서 학습을 잘 하기 위해서는 다양한 데이터가 필요하다.
y트레인 개수 확인
y_train
array([2, 1, 1, 1, 1, 1, 0, 1, 2, 1, 2, 0, 1, 1, 2, 2, 1, 0, 1, 1, 0, 1,
0, 2, 1, 0, 0, 2, 2, 1, 2, 1, 2, 0, 1, 0, 1, 1, 2, 0, 0, 2, 2, 0,
1, 1, 1, 2, 1, 0, 0, 2, 0, 0, 0, 0, 0, 1, 1, 1, 2, 2, 0, 1, 0, 1,
2, 0, 0, 0, 2, 0, 2, 1, 2, 1, 1, 2, 0, 1, 1, 0, 2, 2, 0, 0, 1, 2,
0, 0, 0, 2, 0, 1, 2, 0, 2, 2, 1, 2, 0, 0, 2, 2, 2])판다스로 개수세기
pd.Series(y_train).value_counts()
#1 36
#0 36
#2 33
#dtype: int64혹은
np.unique(y_train, return_counts = True)데이터 탐색
- 특성간의 관계 확인
- 품종을 분리하기 위해서 어떤 특성이 도움이 될까?
산점도행렬(scatterplot matrix) : 한꺼번에 특성 간 관계를 일목 요연하게 확인
pd.plotting.scatter_matrix(iris_df,figsize=(10,10),c=y,alpha
=0.9)plt.show()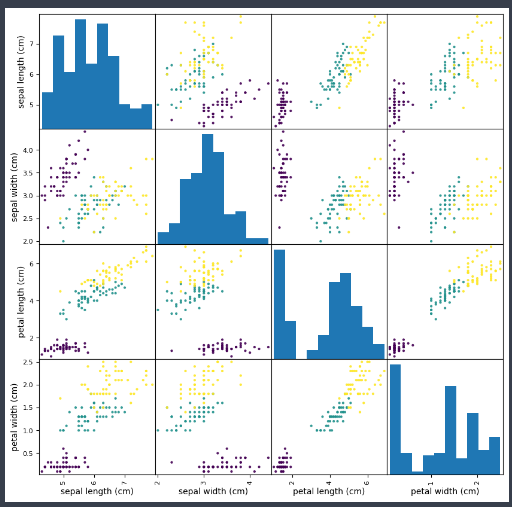
모델 평가 및 예측
객체 생성 이웃의 개수 5로 설정
iris_knn = KNeighborsClassifier(n_neighbors=5)모델 학습
iris_knn.fit(X_train, y_train)모델 예측
pre = iris_knn.predict(X_test)
pre
#array([0, 2, 1, 0, 1, 2, 0, 2, 1, 0, 1, 0, 0, 2, 2, 0, 2, 2, 0, 1, 1, 2,
1, 0, 1, 1, 0, 2, 0, 1, 2, 0, 1, 1, 0, 2, 2, 0])
iris_data.target_names[pre]
#array(['setosa', 'virginica', 'versicolor', 'setosa', 'versicolor',
'virginica', 'setosa', 'virginica', 'versicolor', 'setosa',
'versicolor', 'setosa', 'setosa', 'virginica', 'virginica',
'setosa', 'virginica', 'virginica', 'setosa', 'versicolor',
'versicolor', 'virginica', 'versicolor', 'setosa', 'versicolor',
'versicolor', 'setosa', 'virginica', 'setosa', 'versicolor',
'virginica', 'setosa', 'versicolor', 'versicolor', 'setosa',
'virginica', 'virginica', 'setosa'], dtype='<U10')
평가
accuracy_score(y_test,pre)
#1.0평가를 단 한 번 진행했다. 새롭게 예측하기 위해 여러 번 검증(교차검증)이 필요하다.
하이퍼 파라미터 조정(튜닝)
- n_neighbors : 이웃 수를 여러 번 바꿔보면서 모델의 성능을 확인해보자.
저장하는 빈 리스트 2개 설정
train_lst = [] #train 성능
test_lst = [] #test 성능1~50까지 2칸씩 뛰면서 k값을 세팅(홀수를 이용하도록 하자)
n_setting = range(1,50,2) #이웃의 수
for k in n_setting:
#모델 생성
knn_clf = KNeighborsClassifier(n_neighbors=k)
#모델 학습 train 데이터 활용
knn_clf.fit(X_train,y_train)
#모델 예측 및 평가(성능 확인)
#train ->train_lst에 점수 저장
train_pre = knn_clf.predict(X_train)
#정확도 평가
train_acc = accuracy_score(y_train, train_pre)
train_lst.append(train_acc)
#test ->test_lst에 점수 저장
test_pre = knn_clf.predict(X_test)
test_acc = accuracy_score(y_test, test_pre)
#정확도 평가
test_lst.append(test_acc)평가
test_lst
#[1.0,
1.0,
1.0,
0.9736842105263158,
0.9736842105263158,
0.9736842105263158,
0.9736842105263158,
0.9736842105263158,
0.9736842105263158,
0.9736842105263158,
train_lst
#[1.0,
0.9464285714285714,
0.9553571428571429,
0.9642857142857143,
0.9732142857142857,
0.9732142857142857,
0.9732142857142857,
0.9732142857142857,
0.9642857142857143,
0.9642857142857143,
0.9553571428571429,
0.9553571428571429,
plt.figure(figsize = (10,4))
plt.plot(n_setting,train_lst,label ='train_acc')
plt.plot(n_setting,test_lst,label = 'test_acc')
plt.legend() #범례 출략
plt.grid() # 그래프 눈금선 출력
plt.ylabel('accuracy') # y축 이름 설정
plt.xlabel('n_neighbors==k') # x축 이름 설정
plt.xticks(n_setting) # x축 격자 크기 설정
plt.show()train 100% 맞춘다는 건 과대적합일 확률이 높을 수 있음(하이퍼 파라미터 수 부족)
k값이 커질 수록 성능이 떨어지고 있으며 점점 과소적합일 확률이 높아지고 있음
학습용 데이터라서 모델이 학습하기에, 예측하기에 쉬운 데이터
iris_knn 모델 교차검증 진행
모델의 일반화 성능 확인
from sklearn.model_selection import cross_val_scoretrain 데이터를 기준으로 어떤 모델, 어떤 데이터, 몇 번 검증할 것인가?
#cross_val_score(모델,train,cv = 횟수)
#cv : 데이터를 분리해서 검증하는 횟수
cross_val_score(iris_knn,X_train,y_train,cv=5)
#array([0.95652174, 0.95652174, 0.95454545, 0.95454545, 0.86363636])
print(cross_val_score(iris_knn,X_train,y_train,cv=5).mean())
#0.9371541501976285하이퍼 파라미터가 9일때와 3일 때
iris_knn9 = KNeighborsClassifier(n_neighbors = 9)
print("교차 검증 평균: ",cross_val_score(iris_knn9,X_train,y_train,cv=5).mean())교차 검증 평균 : 0.9731225296442687
iris_knn3 = KNeighborsClassifier(n_neighbors = 3)
print("교차 검증 평균: ",cross_val_score(iris_knn3,X_train,y_train,cv=5).mean())교차 검증 평균 : 0.9462450592885375
교차검증의 결과를 확인하면서 어떤 파라미터로 설정하는게 좋을까 사람이 판단한다. 9로 설정하는 것도 괜찮다.
