머신러닝
1.Machine Learning Python

데이터에 대한 Label(명시적인 답)이 주어진 상태에서 학습시키는 방법분류(Classification)미리 정의된 여러 클래스 레이블 중 하나를 예측하는 것속성 값을 입력, 클래스 값을 출력으로 하는 모델암 양성 음성 중 하나로 분류, 붓꽃(iris)의 세 품종 중
2.python
w
3.python

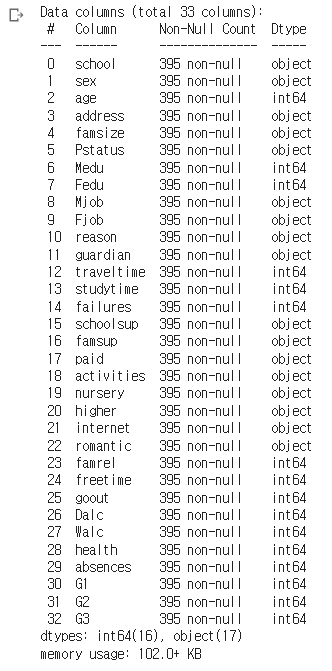
문제 , 답 분리 (A ,B 분리)데이터 확인훈련용 X_train, 테스트용 X_test 분리 및 확인훈련용 y_train, 테스트용 y_test 분리 및 확인\_\_
4.Machine learning bmi 학습하기
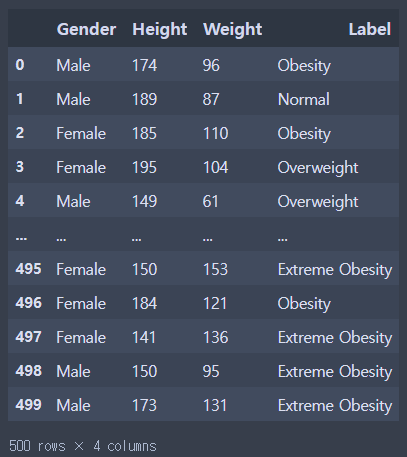
500명의 키와 몸무게, 비만도 라벨을 이용하여 비만을 판단하는 모델을 만들어 보자.1\. Pandas, 시각화 모듈 호출2\. knn 모델 불러오기, 측정 도구 불러오기3\. 데이터 준비(수집)4\. Label 컬럼을 인덱스로 설정해서 불러오기5\. 데이터 정보 확인
5.일반화, 과대적합, 과소적합

모델의 신뢰도를 측정하고, 성능을 확인하기 위한 개념으로 일반화 성능이 최대가 되는 모델을 찾는 것을 목표로 과대적합, 과소적합을 지양해야한다.훈련 세트에 너무 맞추어져 있어 테스트 세트의 성능 저하공의 종류는 다양하지만, 축구공만 설명둥글다.오각형과 육각형으로 이어졌
6.K-NN 실습

150개의 샘플 데이터, 4개의 특성과 1개의 정답(3개의 품종)으로 구성붓꽃 꽃잎의 길이/너비, 꽃받침의 길이/너비 특징을 활용해서 3가지 품종을 분류하는 모델을 만들어보자.knn 모델의 이웃 숫자를 조절해보자. K개수를 조절(하이퍼 파라미터 튜닝)bmi실습에서 훈
7.Decision Tree
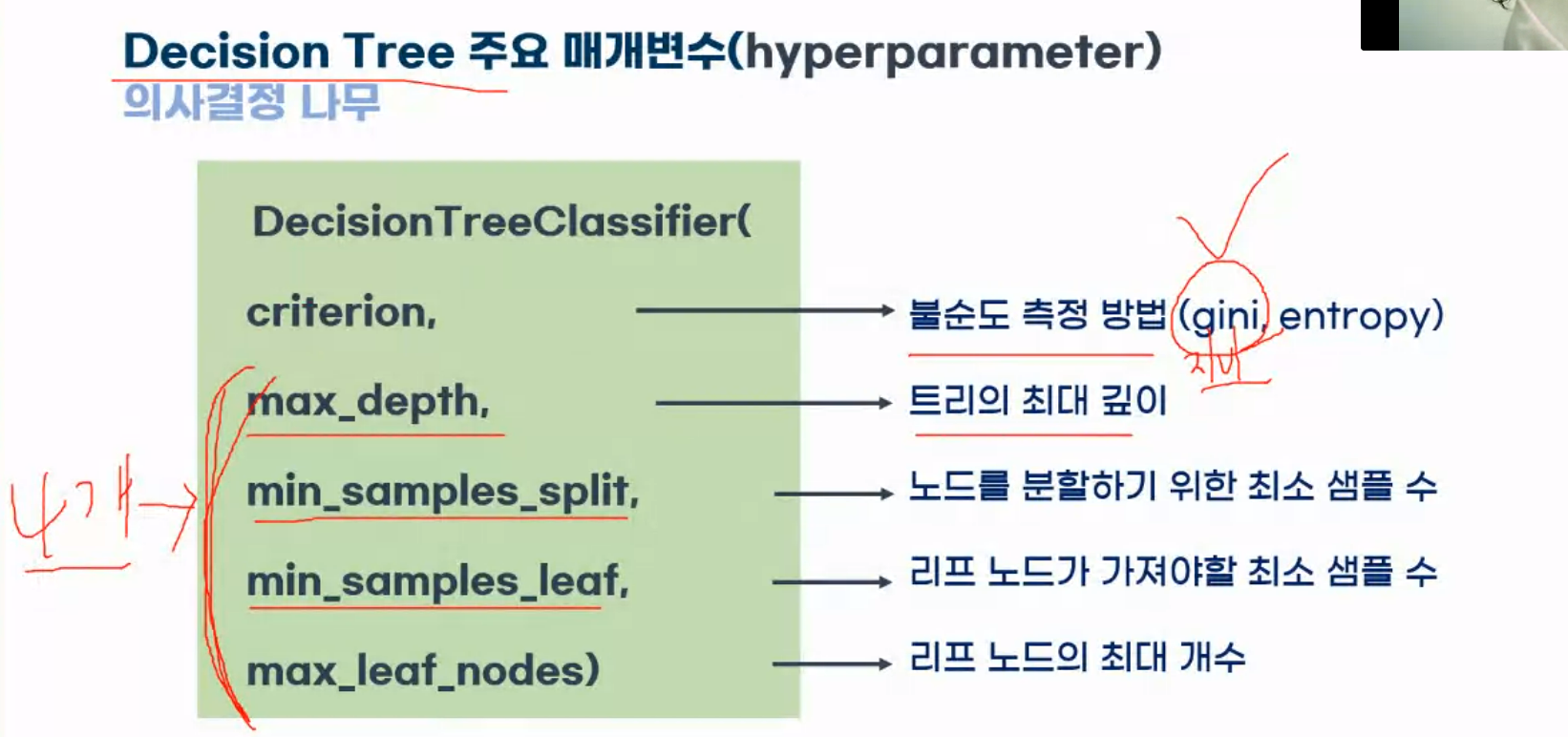
스무고개 하듯이 예/아니오 질문을 반복하며 학습하는 모델특정 기준(질문)에 따라 데이터를 구분하는 모델분류와 회귀에 모두 사용 가능
8.타이타닉 분류 실습
타이타닉 데이터를 활용하여 생존자/사망자 예측하기kaggle 경진 대회에 참가하여 우리 점수를 확인해보자머신러닝의 전체 과정을 체험해보자문제 정의 : 목표 설정, 어떤 모델을 선택할 것인지데이터 수집 : 분류를 할 거라면 class로 담긴 레이블이 있는 데이터 수집데이
9.Text Mining

텍스트 데이터로부터 유용한 인사이트를 발굴하는 Data Mining의 한 종류로 자연어 처리방식(Natural Language Processing)과 문서처리 방법을 적용하여 유용한 정보를 추출/가공하는 것을 목표로 한다.자연어란?인간이 일상생활에서 사용하는 언어인간이
10.딥러닝(colab)
실행 단축키ctrl + Enter : 실행 후 커서가 그대로 위치shift + Enter : 실행 후 커서를 아래 셀로 이동alt + Enter : 실행 후 아래 셀 생성 + 아래로 이동마크다운 변환(코드 -> 텍스트)ctrl + m + m코드모드로 변환(텍스트 ->
11.딥러닝 모델링
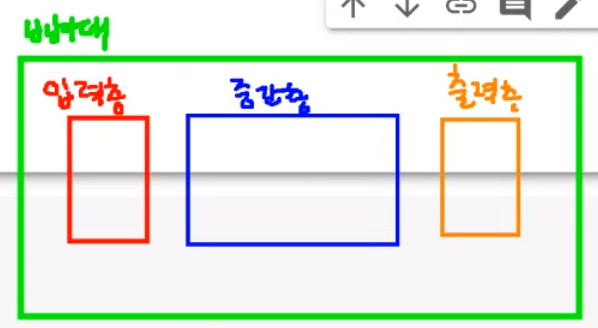
딥러닝 모델 도구 불러오기1\. 신경망 구조 설계2\. 신경망 학습 및 평가 방법 설정3\. 학습4\. 예측 및 평가뼈대 생성 앞으로 모델을 만들거야! 입력층 입력 특성의 갯수 작성중간층 은닉층이라고도 한다.업로드중..
12.개와 고양이 분류하기
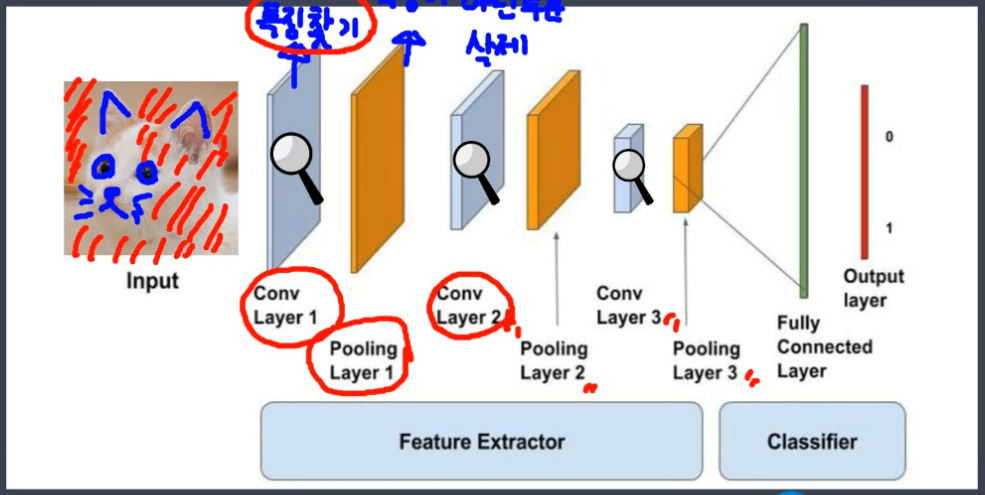
딥러닝 건물의 토대를 만들기층 쌓기건물 외부 디자인이진분류
13.Opencv 템플릿 매칭

Anaconda promptopencv이름의 환경 만들기conda create -n opencv python=3.8opencv 환경 들어가기activate opencv파이썬 다양한 라이브러리 설치하기pip install opencv-python scikit-learn
14.Opencv 이미지 합성하기

이미지를 합성하기 전에 사진 두 개를 준비하자.싸이 얼굴에 호랑이를 합성해보도록 하자이미지가 잘 출력이 된다.흰 부분은 쓰지 않고 까만 부분을 사용할 것이다.이로써 사용할 부분을 흰색으로 반전시켰다.업로드중..
15.mediapipe 얼굴 인식

anaconda promptMediapipe는 구글이 개발한 오픈 소스 프레임워크로, 컴퓨터 비전 및 머신 러닝을 활용하여 비디오 및 오디오 데이터에서 다양한 작업을 수행하는 데 사용됩니다. Mediapipe는 주로 실시간 비디오 및 오디오 처리, 손동작 감지, 얼굴
16.mediapipe 손동작
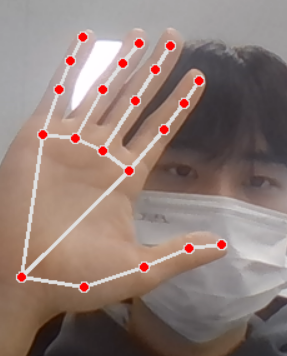
mediapipe의 손을 찾을 때는 21개의 특징점이 존재한다.