문제정의
500명의 키와 몸무게, 비만도 라벨을 이용하여 비만을 판단하는 모델을 만들어 보자.
1. Pandas, 시각화 모듈 호출
import pandas as pd
import matplotlib.pyplot as plt2. knn 모델 불러오기, 측정 도구 불러오기
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score3. 데이터 준비(수집)
#pd.read_csv('파일 경로 설정')
#data 변수에 담아주기
data = pd.read_csv('./bmi.ipynb')
# bmi 파일 준비
data
#데이터 확인
4. Label 컬럼을 인덱스로 설정해서 불러오기
data = pd.read_csv('./bmi_500.csv', index_col='Label')
인덱스에 있는 label을 컬럼쪽으로 연결하기(이동하기)
data2 = data.reset_index()5. 데이터 정보 확인해보기
전체 행, 컬럼 정보, 결측치 여부 확인
data.info()
# # Column Non-Null Count Dtype
--- ------ -------------- -----
# 0 Gender 500 non-null object
# 1 Height 500 non-null int64
# 2 Weight 500 non-null int64
#Null이 없다. Gender는 type이 object이다.
data.shape
#(500, 3)이번 실습에서는 Height, Weight, Label 3개만 활용 예정이다. 이번 실습에서는 전처리를 진행하지 않을 예정이다.
6. 데이터 분석(탐색)
- 기술 통계 확인 : 평균, 최소, 중앙(오름차순으로 줄세웠을 때 정중앙에 있는 값), 최대 등
- 시각화를 통해 데이터의 분포 확인해보기
data.describe()
#숫자 형태(int, float)먼저 적용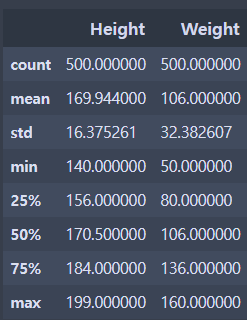
현재 data 안에는 비만인 사람의 데이터가 많이 있음을 알 수 있음.
Label 확인이 필요하며 중복없이 Label을 확인해보자.
data.index.unique()
#Index(['Obesity', 'Normal', 'Overweight', 'Extreme Obesity', 'Weak',
'Extremely Weak'],
dtype='object', name='Label')각각의 값의 횟수를 셀 수 있는 함수(기능)
data.index.value_counts()
#Extreme Obesity 198
#Obesity 130
#Normal 69
#Overweight 68
#Weak 22
#Extremely Weak 13
#Name: Label, dtype: int647. 시각화 해보기 : 비만도 레이블을 표현해보기
X축 키, y축 몸무게를 기준으로 산점도 그려보기(Extreme Obesity)
data.loc['Extreme Obesity']
#행들에만 접근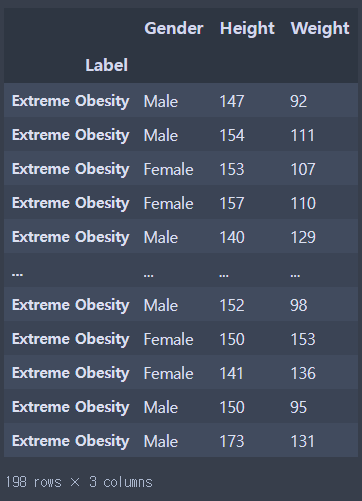
인덱싱을 하기 위해 'd'라는 변수에 저장
d = data.loc['Extreme Obesity']컬럼 인덱싱
plt.scatter(d['Height'],d['Weight'],c='blue',label='ext obes')
#d.loc[:,'Height']랑 같은 의미
plt.legend() # 범례표시
plt.show() #표현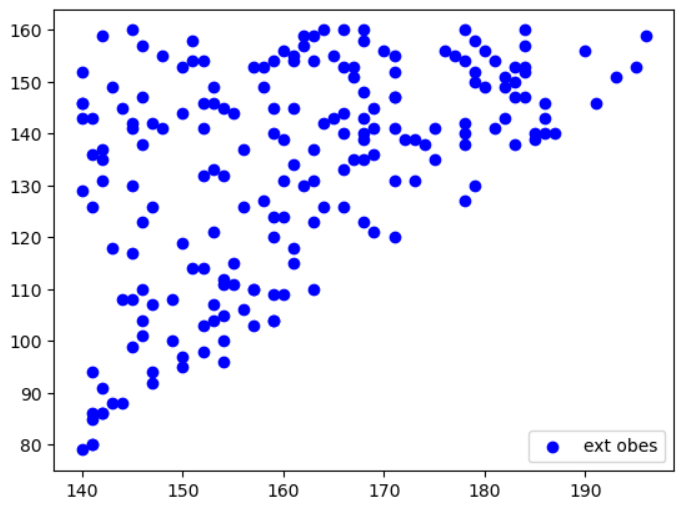
'Extreme obesity' 산점도 표현 완료
plt.scatter(d['Height'],d['Weight'],c='blue',label=
'ext obes')
d2 = data.loc['Obesity']
plt.scatter(d2['Height'],d2['Weight'],c='cyan',label='obes')
plt.legend()
plt.show()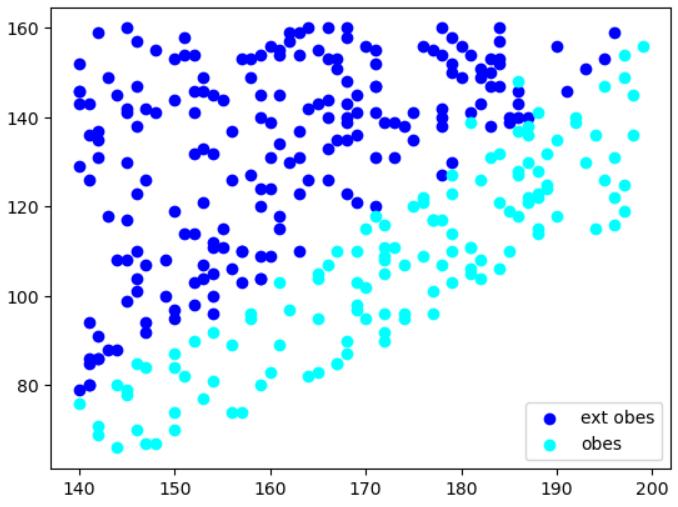
8. 그래프를 그리는 함수 정의
def bmi_draw(label,color):
d2 = data.loc[label]
plt.scatter(d2['Height'],d2['Weight'],c=color,label=label)Label을 하나씩 연결하면서, 색감도 설정하면서 함수를 6번 호출
bmi_draw('Extreme Obesity', 'blue')
bmi_draw('Obesity', 'cyan')
bmi_draw('Normal', 'green')
bmi_draw('Weak', 'yellow')
bmi_draw('Overweight', 'red')
bmi_draw('Overweight', 'gray')
plt.legend()
plt.show()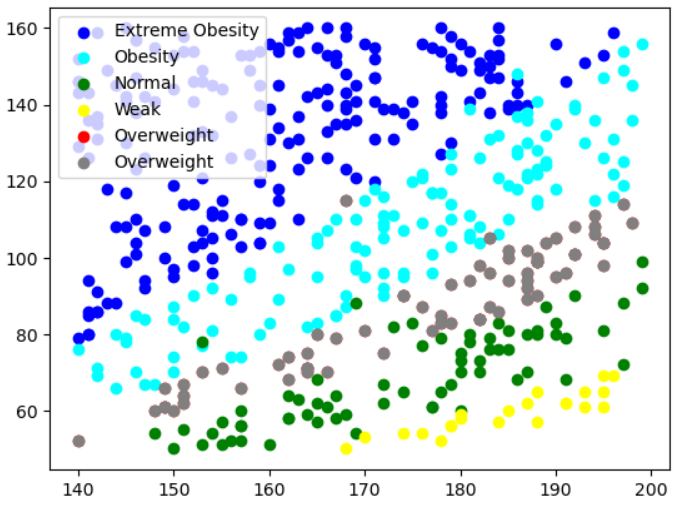
9. 모델링
모델 선택 및 하이퍼 파라미터 조정(knn모델 선택)
행은 총 500개로 이루어져 있다. 이 데이터 또한 훈련용 데이터, 테스트용 데이터로 약 7:3의 비율로 분리한다.
인덱스에 있는 label을 컬럼쪽으로 연결하기(이동하기)
data2 = data.reset_index()문제, 답(컬럼 분리)
X = data2.loc[:, 'Height':'Weight']
y = data2.loc[:, 'Label']크기 확인
print('문제크기:', X.shape)
#문제크기: (500, 2)
print('답크기:', y.shape)
#답크기: (500,)인덱싱 추가학습
#행 데이터 접근 'ㅡ'
df.loc[행], df.loc[값:값] ==> df.loc[행:행]
df.iloc[행], df.iloc[값:값] ==> df.iloc[행:행]
#열 데이터 접근 'ㅣ'
df.loc[:,열], df.loc[:,열:열]
df.iloc[:,열인덱스], df.iloc[:, 열인덱스:열인덱스]
#행 열 접근
df.loc[시작행:끝행, 시작열:끝열]
df.iloc[시작행인덱스:끝행인덱스, 시작열인덱스:끝열인덱스]500개의 데이터 중 70%에 속하는 데이터의 개수는 350개다.
훈련용은 0 ~ 350개까지 테스트용은 350에서 ~ 끝까지
X_train = X.iloc[:350]
X_test = X.iloc[350:]
print(X_train.shape)
#(350, 2)
print(X_train.shape)
#(150, 2)
y_train = y.iloc[:350]
y_test = y.iloc[350:]
print(y_train.shape)
#(350,)
print(y_test.shape)
#(150,)10. 모델 학습
현재 데이터 클래스(카테고리)의 개수는 6개이다.
Index(['Obesity', 'Normal', 'Overweight', 'Extreme Obesity', 'Weak', 'Extremely Weak'],
dtype='object', name='Label')6개의 카테고리 중 한개를 판단하는 것은 다중분류 를 의미한다.
from sklearn.metrics import accuracy_score #정확도 지표knn_model 이라는 변수로 모델 객체 생성
사람이 설정하는 매개변수를 하이퍼 파라미터이며, 이웃의 수(n_neighbors) : 5개
knn_model = KNeighborsClassifier(n_neighbors=5)
knn_model.fit(X_train, y_train)11. 모델 예측 및 평가
pre = knn_model.predict(X_test)
pre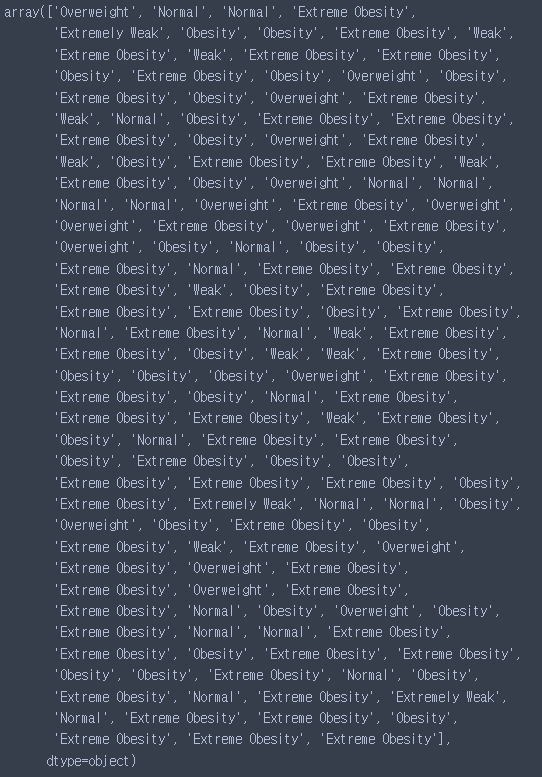
테스트용 예측시 150개가 출력이 잘 된 것을 볼 수 있다.
pre.size
#150test 데이터 정확도 지표
accuracy_score(y_test,pre)
#0.9066666666666666 약 90퍼센트 확률의 정확도를 가지고 있음.