And 연산 Data pit
데이터 준비
import pandas as pd
import numpy as np
import matplotlib.pyplot as pit
# 방법1 이중리스트 [[0,0,0],[0,1,0]....] 행으로 들어감
# 방법2 딕셔너리 {컬럼명: [0,0,0,......]} 열로 들어감
data_dic = {'A':[0,0,1,1,1,0,1,0], 'B':[0,1,0,1,0,0,1,1], 'A and B':[0,0,0,1,0,0,1,0]}
df = pd.DataFrame(data_dic)
문제 , 답 분리 (A ,B 분리)
X = df.loc[:,'A':'B'] #'B'도 포함
#문제 X는 대문자
y = df.iloc[:,-1]
#답 y는 소문자
데이터 확인
X.shape
#(8, 2)
y.shape
#(8,)훈련용 X_train, 테스트용 X_test 분리 및 확인
X_train = X.iloc[:6]
X_train.shape
#(6, 2)X_test = X.iloc[6:,:]
X_test.shape
#(2, 2)훈련용 y_train, 테스트용 y_test 분리 및 확인
y_train = y.iloc[6:]
y_train.shape
#(6,)y_test = y.iloc[6:]
y_test.shape
#(2,)print('훈련용 데이터:', X_train.shape, y_train.shape)
print('테스트용 데이터:', X_test.shape, y_test.shape)
#훈련용 데이터: (6, 2) (6,)
#테스트용 데이터: (2, 2) (2,)데이터 탐색(탐색적 데이터 분석)
- A 컬럼 int 데이터, 0/1
- B 컬럼 int 데이터, 0/1
- A and B 컬럼 int 데이터, 0/1
- 결측치X, 이상치x
모델링
- 모델 선택 및 하이퍼 파라미터 조정
- 모델 학습(Learning)
- 모델 예측 및 평가
모델 불러오기
분류하는 모델 중 knn 모델을 불러오기
sklearn(scikit-learn) 머신러닝 패키지 : 머신러닝에 사용되는 도구를 담은 패키지
지도/ 비지도/ 강화, 분류/ 회귀, 평가 공식(기능), 데이터 전처리 하는 기능
모델 객체 생성
모델마다 하이퍼 파라미터명과 쓰임이 다르다. knn에서는 n_neighbors가 하이퍼 파라미터(사람이 설정하는 값).
from sklearn.neighbors import kNeighborsClassifier
from sklearn.metrics import accuracy_score
knn_model = KNeighborsClassfier(n_neighbors = 1) #이웃이 한개모델 학습
모델이 학습할 때 사용하는 함수 fit()
knn_model.fit(훈련용 문제, 훈련용 답)
모델 예측(모델이 일을 잘 할 수 있을까?)
pre = knn_model.predict(X_test) #테스트용 문제 넣어줘야 함.
#array[1,0]이 출력이 된다. 이는 'A'와 'B'의 AND 연산을 예측한 것이다.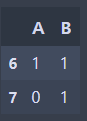
예측이 실제 정답과 항상 같지는 않고 예측이 틀릴 수 있다.
만약 knn_model = KNeighborsClassfier(n_neighbors = 1) 이웃(하이퍼 파라미터)이 많다면 정답을 다르게 예측할 수도 있을 것이다.
모델 평가
예측이 실제 값과 비교했을 때 몇 개나 잘 맞췄는지 표현하는 점수 척도
accuracy_score(y_test,pre)
#accuracy_score : 0~1로 출력이 된다. 1에 가까울 수록 잘 맞췄다는 것이다.
# 1.0
hello!