크롤링
1.파이썬 웹 크롤링 BeautifulSoap
웹 사이트의 내용에 접근하여 원하는 정보를 추출해 내는 행위anaconda Prompt JUPYTER NOTEBOOK 이용res에서 크롤링에 필요한 html코드를 받아오자melon 사이트 크롤링 해보기멜론 서버에서 들어온 요청이 브라우저가 아닌 컴퓨터임을 인지한다.개발
2.멜론차트 데이터 수집 Beautiful Soap
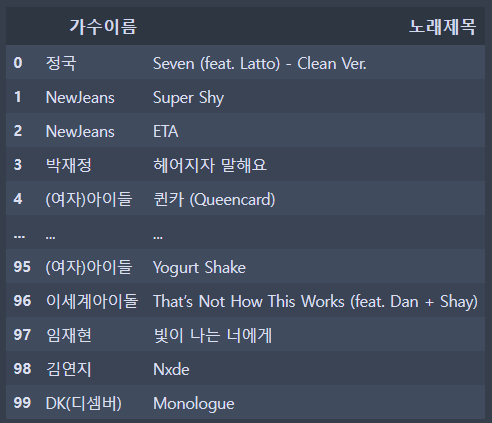
데이터의 개수가 정해진 경우에는 반드시 데이터 검증이 필요하다. 데이터의 길이, 데이터의 중복여부를 확인하자
3.바디럽 리뷰 수집 BeautifulSoup

멜론과 마찬가지로 프로그래밍 언어로 접근하는 것을 제한했다.header를 입력한다.soup 사용결과값이 나오지 않는다. 이는 리뷰를 수집할 때 많이 발생하는 상황으로 여러 개의 페이지로 구성되어 있을 때 발생하는 문제다. 한 페이지 안에 원하는 값이 여러개의 페이지로
4.파이썬 웹 크롤링 selenium

브라우저를 자동제어하여 크롤링을 자동화시키는 라이브러리이다. 동적 크롤링을 진행할 때 사용된다. 사용하기 위해서는 반드시 설치를 해야한다.라이브러리 설치Selenium 최신버전 업그레이드브라우저 역할을 해주는 라이브러리변수 설정검색창의 위치를 알아온다.\`driver.
5.한솥도시락 데이터 수집 Selenium

라이브러리 호출한솥도시락 페이지 이동상품 이름 수집선택자가 class나 id가 아닌 요소로 찾기(class이긴 함)글자 꺼내오기업로드중..
6.네이버 지도 데이터 수집 Selenium
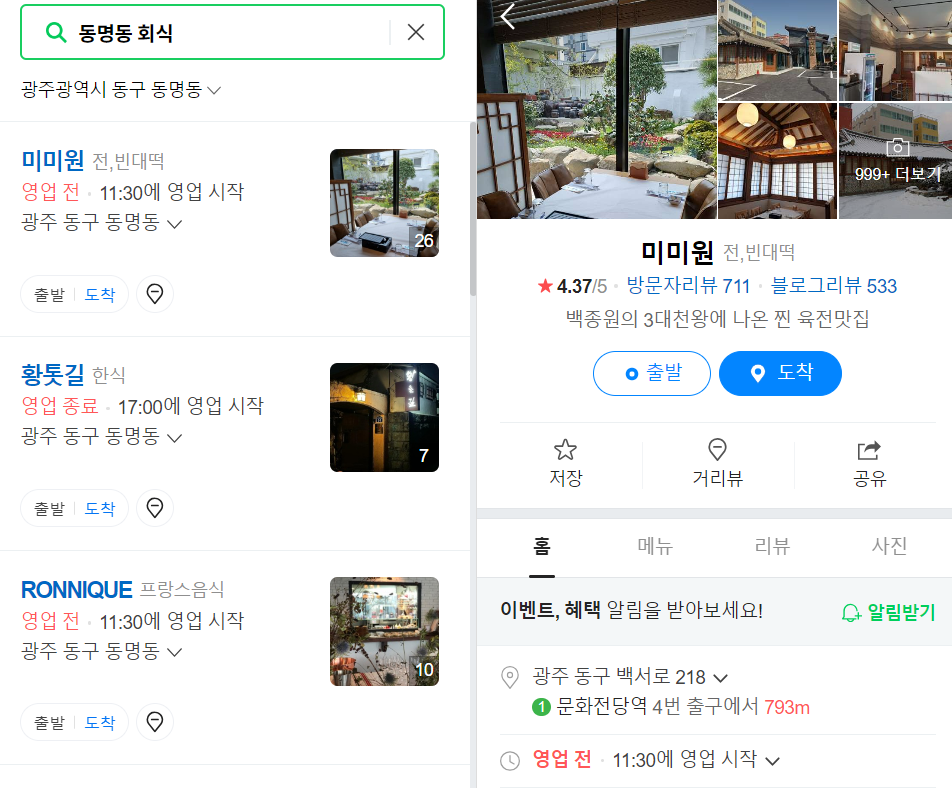
동명동 회식 이란 키워드로 네이버 지도에서 가게 이름 정보들을 크롤링해보자.1\. selenium 필수 import2\. 크롬 드라이버를 실행해서 네이버 지도 사이트로 이동3\. 검색창에 검색어를 입력("동명동 회식")검색창의 구분자인 id값이 실행할 대마다 변한다.
7.이미지 데이터 수집 Selenium

2\. 네이버 푸바오 이미지 검색 및 이미지 태그 수집3\. 이미지 태그 안에 있는 속성(이미지 경로)을 가지고 오기4\. 이미지 가공src만 담는 리스트 생성5\. 파일로 저장업로드중..
8.네이버 이미지 selenium