1. req를 통해서 멜론차트 정보를 요청
import requests as req
res = req.get("https://www.melon.com")
res
#<Response [406]> 에러코드 발생
head = {'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'}
req.get("https://www.melon.com",headers =head)
#<Response [200]> 정상 요청, 응답 완료
res = req.get("https://https://www.melon.com/chart/index.htm",headers = head)2. bs을 통해서 html데이터로 변형
from bs4 import BeautifulSoup as bs
soup = bs(res.text,"lxml")3. 노래 제목 수집
title = soup.select("div.ellipsis rank01 > span > a")
#클래스가 두 개라면 공백이 생기게 되는데 공백을 없애고 .로 이어준다.
song = soup.select("div.ellipsis.rank01 > span > a")4. 가수 이름 수집
singer = soup.select("div.ellipsis.rank02 > a")데이터의 개수가 정해진 경우에는 반드시 데이터 검증이 필요하다. 데이터의 길이, 데이터의 중복여부를 확인하자
5. 수집된 데이터를 텍스트 정보만 추출해서 저장
song_list = []
singer_list = []
for i in range(len(song)):
song_list.append(song[i].text)
singer_list.append(singer[i].text)
6. 표를 제작(pandas)
import pandas as pd
dic = {"가수이름" : singer_list, "노래제목" : song_list}
melon = pd.DataFrame(dic)
melon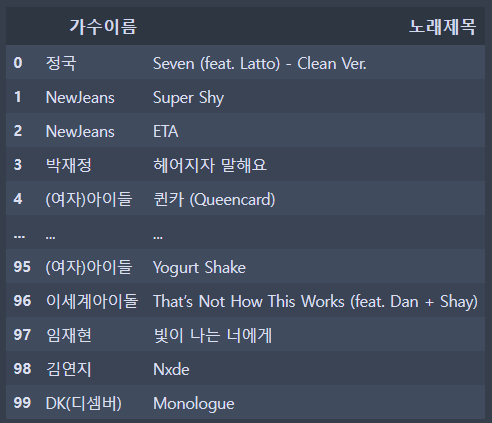
7. 파일로 저장
melon.to_csv("멜론차트.csv", encoding="euc-kr")
hello!