크롤링
웹 사이트의 내용에 접근하여 원하는 정보를 추출해 내는 행위
anaconda Prompt JUPYTER NOTEBOOK 이용
Request 사용법
import requests as req #req -> 파이썬에서 브라우저의 역할을 대신한다.requests를 통해서 네이버 페이지 정보를 요청
req.get("https://www.naver.com") #req야 네이버 정보를 가져와
#<Response [200]> 통신에 성공했다는 뜻으로 응답코드를 넘겨받는다.
# 200, 300 -> 통신에 성공했습니다.
# 400 -> 클라이언트 요청의 문제가 있다.
# 500 -> 서버의 문제가 있다.
res라는 변수에 응답 데이터를 저장하자.
res = req.get("https://www.naver.com")res에서 크롤링에 필요한 html코드를 받아오자
res.text
# <!doctype html> <html lang="k......melon 사이트 크롤링 해보기
import requests as req
res = req.get("https://www.melon.com/")
res
#<Response [406]>멜론 서버에서 들어온 요청이 브라우저가 아닌 컴퓨터임을 인지한다.
개발자 도구 -> network -> 새로고침 -> headers -> user-Agent
head = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'}headers 정보를 같이 요청한다.
req.get("https://melon.com/", headers = head)
#<Response [200]> 정상적으로 응답까지 완료되었다.실제 데이터 수집
뉴스 타이틀 수집하기
- 네이버 사이트(검색한 뉴스 화면)를 요청
res = req.get("https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%EC%98%A4%EC%97%BC%EC%88%98+%EB%B0%A9%EB%A5%98")
#'<!doctype html> <html lang=".....
html 데이터 받아오기 완료!BeautifulSoup
req를 통해서 받아온 텍스트 데이터를 컴퓨터가 이해할 수 있는 html형태로 변환
# 주의할 점. stone이 아닌 일반 soup을 임포트
from bs4 import BeautifulSoup as bs- 응답을 받은 데이터에서 뉴스 타이틀만 수집
soup = bs(res.text,"lxml") #lxml형태로 변환해줘!뉴스 타이틀 우클릭 -> 검사
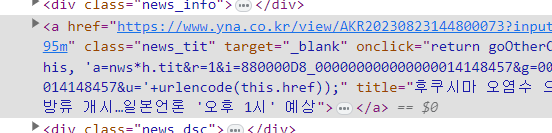
select함수 html데이터에서 특정 요소만 수집
title = soup.select("a.news_tit")
- 수집된 요소 중에 컨텐츠(텍스트) 데이터만 추출
title[0].text
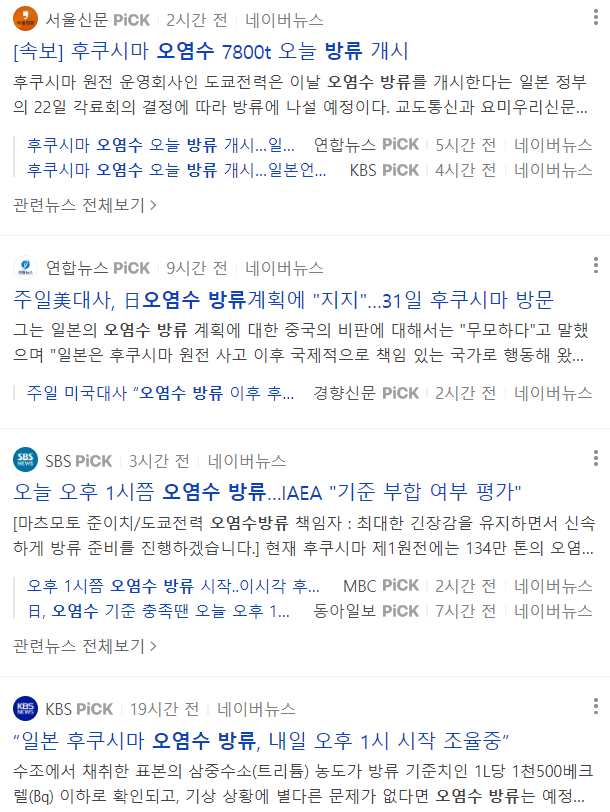
#"후쿠시마 오염수 오늘 방류 개시…일본언론 '오후 1시' 예상"모두 가져오기(반복문)
for i in title :
print(i.text)
#후쿠시마 오염수 오늘 방류 개시…일본언론 '오후 1시' 예상
#오후 1시쯤 오염수 방류 시작‥이시각 후쿠시마
#“일본 후쿠시마 오염수 방류, 내일 오후 1시 시작 조율중”
#주일美대사, 日오염수 방류계획에 "지지"…31일 후쿠시마 방문
#日 오염수 내일부터 방류…서울시 "모든 수산물 매일 표본조사"
#[속보] 日언론 “오염수 70%는 방류 기준 미달”
#식약처 "후쿠시마 오염수 방류 관계없이 日 식품 수입규제 유지"
#김동연 "日 오염수 방류, 정부는 방조 넘어 공조…철회하라"
#이재명 “日오염수 방류는 제2의 태평양 전쟁”
#한총리 "日오염수 방류, 기준에 안 맞으면 국제 제소"네이버 금융정보 수집
res = req.get("https://finance.naver.com/")
res
#<Response [200]>
res.text
#'<html lang="ko">\n <head> \n <title.....
soup = bs(res.text, "lxml")
title = soup.select("#_topItems1 > tr > th > a") #만약 id, class태그가 없다면 나를 포함하는 바로 위의 태그에 id나 class태그를 확인한다. 만약 바로 위의 태그도 없다면 구분자가 있을 때 까지 찾아야 한다.
for i in title:
print(i.text)
부모자식을 의미하는 자식 선택자를 잘 활용
수집하고자 하는 요소가 아이디, 클래스 구분자가 없다면 반드시 부모를 검사
부모태그가 구분자가 존재할 때 까지 검사를 진행
구분자가 없는 경우에는 정확하지 않을 확률이 높음
선택자 한번에 가져오기
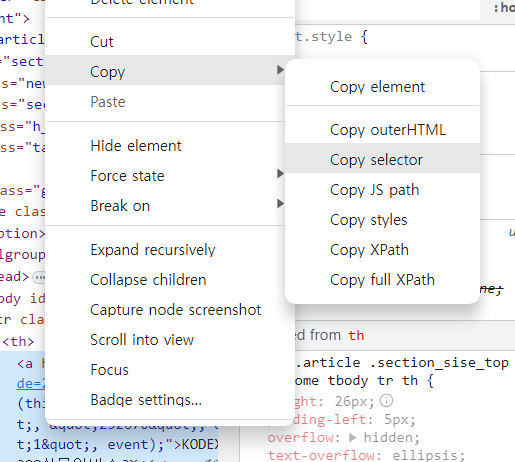
#_topItems1 > tr:nth-child(1) > th > a선택자를 한 번에 가지고 오는 방법
1. 개발자 도구에서 요소에 우클릭 -> copy -> copyselector
-
주의점! 반드시 내가 선택한 하나만 가지고 온다.
-
복수개가 필요한 경우에는 선택자를 수정(ex nth-child())

hello!