딥러닝 건물의 토대를 만들기
model = Sequential()층 쌓기
model.add(Dense(units, activation, input_dim))
model.add(Dense(units, activation, input_dim))
model.add(Dense(units, activation, input_dim))
model.add(Dense(units, activation, input_dim))
#각 층마다 다를 수 있다.
units = 이진분류 = 1, 다중분류 = 클래스의 갯수, 회귀 = 1
- activation : 이진분류 = 'sigmoid', 다중분류 = 'softmax', 회귀 = 'linear'sigmoid
이진분류에서 sigmoid를 사용하는 이유
- sigmoid는 0~1까지로 결과를 바꿔줌(y값)
- 해당 결과를 보면 딥러닝 모델을 어떤 식으로 수정해야 하는지 알 수 있음
- 0또는 1에 가까울 수록 모델이 예측을 잘 하고 있다는 것.
건물 외부 디자인
이진분류
model.compile(
loss : binary_crossentropy
optimizer : ADAM(RMSPROP,NADAM) #웬만하면 ADAM
metrics : ['accuracy'], ['mean_squared_error'] #생략가능다중분류
model.compile(
loss : categorical_crossentropy
optimizer : ADAM(RMSPROP,NADAM) #웬만하면 ADAM
metrics : ['accuracy'], ['mean_squared_error'] #생략가능회귀
model.compile(
loss : mean_squared_error
optimizer : ADAM(RMSPROP,NADAM) #웬만하면 ADAM
metrics : ['accuracy'], ['mean_squared_error'] #생략가능CNN(Convolution Neural Network)
이미지 학습이 가능하다.즉, 2차원의 데이터도 학습이 가능하다. 데이터에서 특징을 추출하고 추출된 특징을 기반으로 학습한다. 따라서 이미지의 크기, 방향등에 크게 관여받지 않는다.
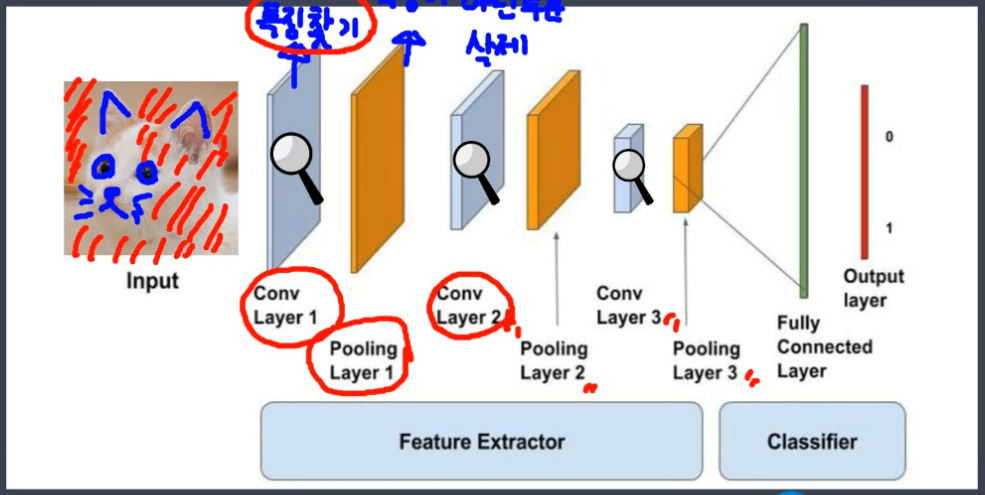
Convolution Layer에서 특징을 찾고 Pooling Layer에서 특징이 아닌 부분을 삭제한다. 큰 특징을 찾고, 그 다음으로 큰 특징을 계속해서 찾아내는 과정이다. Dense는 찾아진 특징을 토대로 사물을 구분할 규칙을 만든다.
데이터 경로지정
#경로 : /content/drive/MyDrive/data/dogs_vs_cats_small
#데이터 경로지정
train_dri = '/content/drive/MyDrive/data/dogs_vs_cats_small/train'
valid_dir = '/content/drive/MyDrive/data/dogs_vs_cats_small/'개와 고양이 분류하기
라이브러리 호출
from tensorflow.keras.preprocessing.image import ImageDataGenerator순서
-
픽셀값 변경
-
숫자 크기 줄여 연산량 감소시키기
-
분산(값이 분포해있는 범위) 줄여서 연산의 오류를 줄어들도록 만들기
-
이미지 크기 맞춰주기(150,150)
-
라벨링(문제 데이터, 정답 데이터)
픽셀값 변경
(0~255 /정수)형태를 (0~1 /실수) 형태로 변경
generator = ImageDataGenerator(rescale=1./255) #1. = 1.0묵시적 형변환(프로그래밍에서 연산상에서 타입이 변동되도록 하기)
- 하나의 변수에 이미지 파일 전부 다 합치기
- 이미지 크기 동일하게 만들어주기
- 라벨링
train_generator = generator.flow_from_directory(
directory = train_dir, # train 이미지 경로, 변환할 이미지
target_size = (150, 150), # 변환할 이미지 크기
batch_size = 100, # 한 번에 변환할 이미지 갯수
class_mode = 'binary' # 라벨링 방법, 만약 다중분류라면 categorical
)CNN 모델 설계(특징 추출부)
라이브러리 호출
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Conv2D, MaxPool2D, Flatten모델 생성(기둥 생성)
model1 = Sequential()입력층(특징 찾기)
model1.add(Conv2D(
filters = 32, #찾을 특징의 갯수
kernel_size = (3,3), #특징의 크기
input_shape = (150,150,3), #모든 이미지의 모양, rgb = 3
activation = 'relu' #출력층을 제외한 활성함수는 웬만하면 relu
))특징이 아닌 부분 삭제
model1.add(MaxPool2D(
pool_size = (2,2) #기준 크기에서 1개의 특징만 가져오기 / 4개중에 한개 사용하기
))분류 분석 시작
특징 추출부와 분류부를 이어주는 역할
model1.add(Flatten()) 분류 분석시작
model1.add(Dense(units = 32, activation = 'relu))출력층
model1.add(Dense(units = 1, activation = 'sigmoid'))학습 방법 설정
model1.compile(
loss = 'binary_crossentropy',
optimizer = 'Adam',
metrics = ['accuracy']
)학습 시작
model.fit(
train_generator, #학습데이터(X_train, y_train이 합쳐져 있다.)
epochs = 20,
validation_data = valid_generator
)학습 결과


강아지 사진 넣어보기
import PIL.Image as pimg
import cv2
pre_img = cv2.imread('/content/janggoo.jpg',cv2.IMREAD_COLOR) # 이미지 불러오기
pre_img = cv2.cvtColor(pre_img, cv2.COLOR_BGR2RGB) # 이미지 색상 변경하기
pre_img = cv2.resize(pre_img,(150,150)) # 이미지 크기 변경하기
pre_img = pre_img.reshape((1,150,150,3)) # 이미지 차원 변경하기확인해보기
model1.predict(pre_img)
#1/1 [==============================] - 0s 176ms/step
#array([[1.]], dtype=float32)
강아지를 잘 구분했다. 1은 강아지, 0은 고양이다. 개의 규칙은 잘 찾았지만 고양이의 규칙은 잘 찾기 못했다. 또한 Train은 학습이 잘 됐고, val은 학습이 안됐다. 이말은 즉 과대적합 상태에 해당된다.
과대적합 해소
1. 데이터의 양을 늘린다. (많이 어렵다.)
2. 모델을 더 깊게 구성한다. (층을 더 많이 쌓는다.)
3. 데이터를 확장한다. (양을 늘리는 것과는 다른 의미로, 가지고 있는 데이터를 다양하게 표현한다.)
데이터 확장
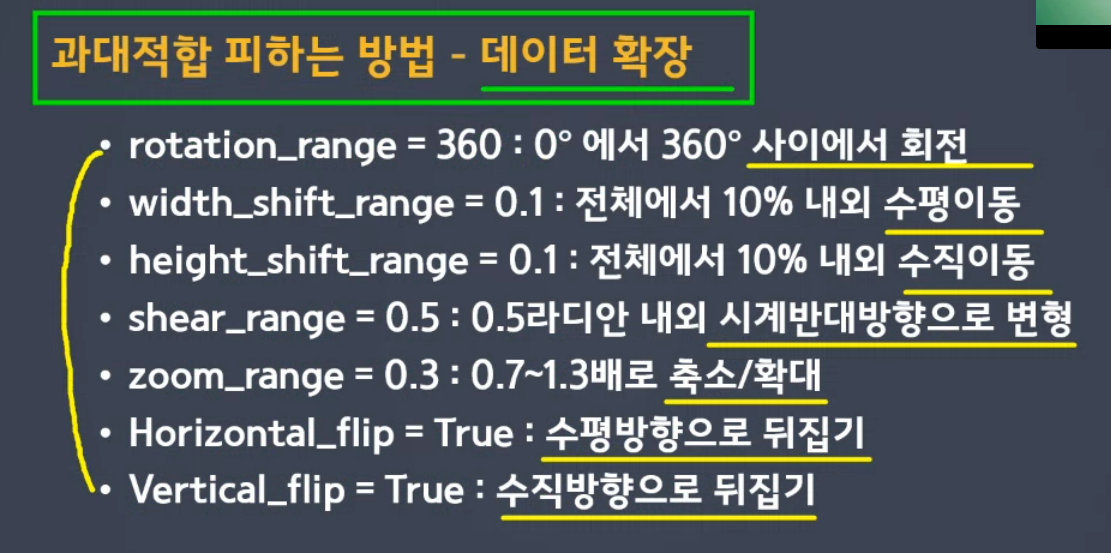
-
데이터를 확장하고 새롭게 학습한다.
-
데이터를 확장하면 원본 데이터는 사라진다.
-
모델설계 -> 확장 안 된 이미지로 학습 -> 결과 확인 순서이다.
기존 모델에 확장 데이터로 학습하기(확장의 방법)
aug_generator = ImageDataGenerator(
rescale = 1./255, # 픽셀값 조정
rotation_range = 20, # 회전 범위(20도까지는 돌리자)
width_shift_range = 0.1, # 수평 이동(10%는 수평 이동)
height_shift_range = 0.1, # 수직 이동
shear_range = 0.1, # 반시계 방향 회전
zoom_range = 0.1, # 확대/축소 비율(10퍼정도는 확대 축소하겠다.)
horizontal_flip =True, # 수평 뒤집기
fill_mode = 'nearest') #가까운 값으로 비어있는 곳을 채운다
데이터를 직접 확장 시키기
train_aug_generator = aug_generator.flow_from_directory(
train_dir,
target_size = (150,150),
batch_size = 100,
class_mode = 'binary'
)학습시키기
model1.fit(
train_aug_generator,
epochs =20,
validation_data = valid_generator)결과 확인

학습 정확도(accuracy)는 1에서 0.7655까지 떨어졌지만 val_accuracy는 0.7060에서 0.7390까지 올랐다. 학습 정확도와 val_accuracy는 비슷한 정확도를 가지게 되면서 과대적합을 해소하게 되었다.
