Abstract & Introduction
- 최근 self-attention을 기반으로 한 ViT들이 vision task들에서 놀라운 성능을 보이고 있는데, patch와 head와 block 개수의 증가로 인해 여전히 엄청난 computational cost를 요구하고 있다.
- 본 논문에서는 이미지 간의 너무 많은 변화로 인해 patch들 사이의 long-range dependency가 달라지는 문제가 생긴다고 한다.
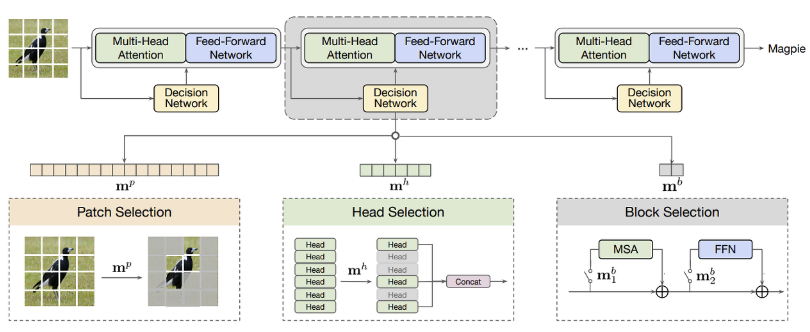
- 이를 해결하기 위해서, 어떠한 patch, head, block을 이용할 것인지 선택할 수 있도록 usage policy를 학습한 모델인 AdaViT라는 adaptive한 computation framework를 제시하여 최소의 성능감소로 inference 효율을 늘렸다고 한다.
- 가벼운 decision network라는 것을 transformer backbone에 부착하여서 즉석에서 결정을 할 수 있도록 하였다.
Approach
- AdaViT는 ViT의 모든 Patch / Head / Block 중 중요한 부분만을 선택하여 사용하며, 중요도는 Decision Network를 통해서 파악한다.
- Decision Network의 입력으로는 이전 transformer layer 출력을 의미하는 로 표현을 하는데, 이는 size가 (batch size, number of tokens, dimension)이 아닌 첫 번째 토큰인 policy token(class token) 만을 사용하여서 single layer perception인 를 통과하여 1d vector의 꼴로 나온다.
1. Patch selection module
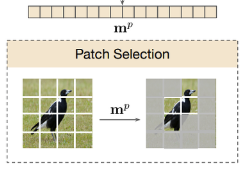
- patch selection을 위해서 각 layer마다 라는 single linear layer을 두고 여기에 이전 layer에서 가져온 policy token(class token)을 통과 시켜서 (1, N) (N: patch 개수)크기의 vector을 얻는다. 이 벡터에서 k번째 자리는 k번째 toekn의 유지 확률을 뜻한다.
- 이렇게 얻어낸 vector 를 keeping probability vector이라 부르며, 이 확률로 on/off를 결정하는 binary vector인 를 sampling한다.(는 sigmoid를 거치기 때문에, 확률에 의해서 0 또는 1로 항상 sampling 된다.)
- 마지막으로 얻어낸 가 binary한 성분을 가지기 때문에 간단하게 과의 elementwise 곱셈을 통해 on/off를 반영한다.
이에 대한 식은 다음과 같다.
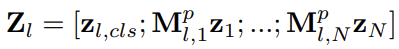
- 저자는 여기서 최대한 정보성이 많은 패치만을 살리고 나머지는 제외시켜서 속도를 향상시키고 싶었다고 한다.
2. Head Selection module
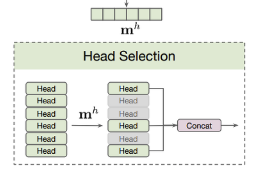
- Head Selection module에서도 patch 때와 비슷하게 라는 single linear layer을 사용한다. 마찬가지로 이전 layer의 policy token(class token)을 통과 시켜서 (1,H) (H:head 개수) 크기의 1d probability vector를 얻는다.
- 이 논문에서는 head의 on/off 방식을 2가지 method로 제안하고 있다.
2.1. Partial Deactivation
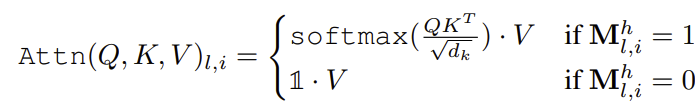
- 위의 수식처럼 sampling된 확룰이 1인 head에 대해서는 self-attention mechanism을 적용하고, 그러힞 않은 head에 대해서는 Value transform된 값을 그대로 사용하는 것을 partial deactivation이라고 명명한다.
2.2. Full Deactivation
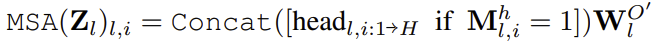
- 위의 수식처럼 off된 head는 모두 제외하고 on된 head만을 concat하여 다음 block으로 넘겨주는 것을 full activation이라고 명명한다.
- 이 경우에는 transformer의 input dimension이 block마다 점점 줄어들어서 연산 이득이 계속해서 중첩되어 약간의 성능 하락을 trade-off로 내어주긴 하지만, 물리적인 dimension 크기를 줄여 큰 연산 이득을 볼 수 있다고 한다.
3. Block selection module
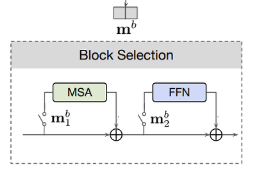
- Block selection의 경우에도 앞선 두 module과 마찬가지로 single layer perceptron을 사용하여 probability vector를 만든다.
- 이 경우에는 를 통과해서 2가지의 probability vector을 이용하여서 한 transformer block의 sublayer인 MSA와 FFN로 나누어서 각각 on/off를 선택할 수 있게 한다.
4. Optimization problem
위에서 말했던 module들에는 discrete한 sampling(binary decision)을 backpropagation 할 수 없다는 문제가 있다. 이를 해결하기 위해서 본 논문에서는 특별한 trick을 사용하는데, 이는 선행 연구인 Gumbel max trick을 기반으로 한 Gumbel softmax trick이라는 method를 사용한다. 이를 설명하기 위해서 먼저 Gumbel max trick에 대해서 설명 하겠다.
Gumbel Max trick
- Gumbel max trick을 사용하는 이유는 앞서 설명드린 일정 확률로 part 각각에서 0 또는 1이라는 값을 특정 확률로 sampling 하는 미분 불가능한 방식을 back propagation 하기 위해서다.
- categorical distribution 가 (로 분포되어 있다고 가정해보자. 이때, Gumbell distribution의 특성을 이용해 trick을 사용한다.
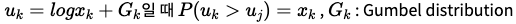
- 위와 같은 식으로 discrete한 categorical 함수를 continuous한 식으로 바꿔줄 수 있어서 미분이 가능해진다.
- 이렇게 변환한 값들 중에서 가장 큰 값의 index만을 취하기 위해서 gumbel max trick에서 나온 값 중 argmax index , 즉 확률이 가장 높게 나오는 값의 인덱스 만을 취할 수 있어야 하는데, argmax의 미분이 문제가 된다.
Gumbel Softmax
- 이를 위해서 Gumbel Softmax를 사용하는데, 이는 기존에 존재하는 softmax temperature 개념을 Gumbel max trick과 합친 것으로 볼 수 있다.
- 0에 매우 근사한 temperature 설정을 통해서 가장 높은 probability를 가지는 index를 sampling할 확률을 1에 가깝게 만들어주는 역할을 한다.
- 여기에 Gumbel max trick을 접목함으로써 Gumbel Softmax trick이 완성된다. 이렇게 argmax function의 미분 문제, discrete sampling에 대한 backpropagation 문제를 해결했다고 한다.
최종적인 식은 다음과 같이 기존 softmax에 temperature을 적용한 식을 바탕으로 Gumbel function이 들어가게 된다.
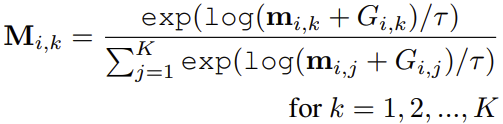
Loss Function
- Loss function으로는 2가지가 있는데, 첫 번째로는 classification task를 위한 cross-entropy loss가 있고, computation cost를 줄이기 위한 usage loss가 있다고 한다.
- cross entropy loss에 더해 최대한 많은 개수의 patch / head / block을 생략하기 위한 loss인 라는 이름의 loss를 추가하여 사용한다.

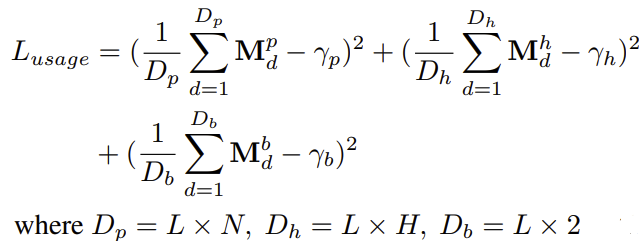
- 여기서 는 각 patch / head / block의 통과율을 적어도 어느정도는 유지시키기 위해 마련한 budget이라고 한다. 모든 경로가 다 block되면 안되기 때문이다.
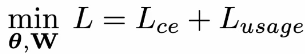
- gumbel-softmax trick 덕분에 end-to-end 형식으로 두 loss function을 합치고, 최소화하는 것이 가능했다고 한다.
Experiment
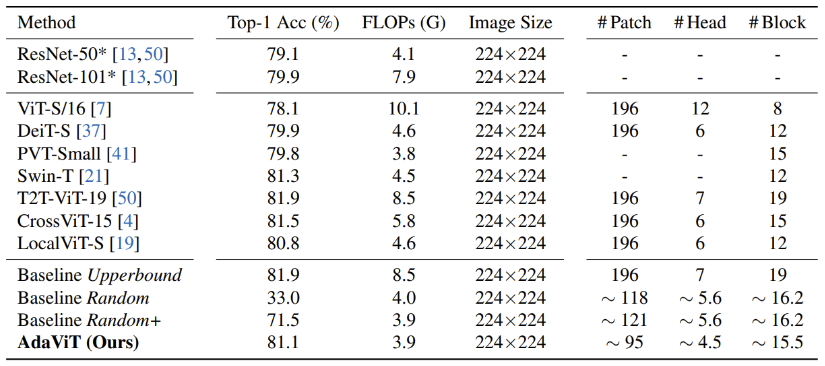
- ImageNet에 대한 실험 결과이고, Baseline upperbound는 기존의 ViT를 의미한다.
- AdaViT는 이에 비해 0.8%의 성능 하락이 있었지만, FLOPs가 2배 이상 감소한 결과를 보인다.
- Baseline Random은 말 그대로 ViT의 patch / head / block을 random하게 deactivate한 경우이고, Random+는 여기에 fine-tuning까지 적용했을 떄의 결과라고 한다.
- 이처럼 random deactivation과의 비교를 통해서 본 논문에서 제시하는 방식의 deactivation의 타당성을 보여주는 듯 하다.

- 위 그림은 transformer layer가 진행됨에 따른 activate된 patch를 나타낸 그림이다. 이 그림을 통해 layer가 진행됨에 따라서 점점 중요한 patch들만 activate됨을 확인할 수 있다.
- Transformer 자체가 input dependent하며, 논문에서 제시하는 방법도 input adaptive하게 설계되었기 때문에 입력에 따라 patch가 on/off되는 양상은 차이가 있음을 확인할 수 있다.
Ablation study
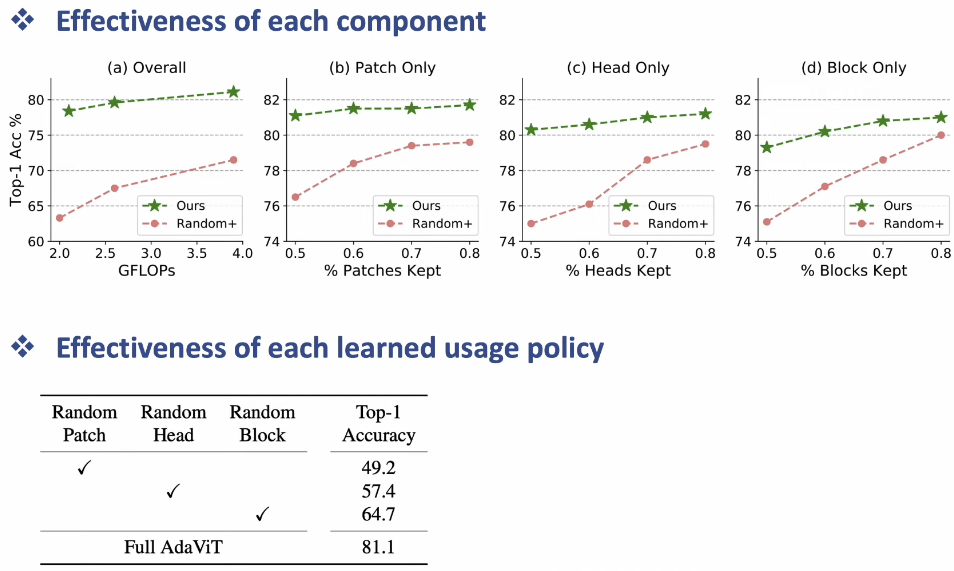
- 위 그림에서 볼 수 있듯이, patch / head / block 에 대한 방식을 각각 따로 하나씩만 적용했을 때에도 성능 하락 없이 경량화가 가능했음을 보였다고 한다. 이를 통해 본 논문의 방식이 실제로 효과적임을 증명했다고 한다.
Conclusion
- 본 논문에서는 어떠한 patch / head / block을 사용할 것인지 결정하는 adaptive computiation framework인 AdaViT를 제시하고 있다.
- 이를 위해서 light weight network인 decision network를 각 transformer block에 추가하여 사용한다.
- 실험결과적으로 아주 적은 성능 감소로 2배 이상의 계산량 감소를 통해 효율성을 증가시킴을 확인하였다고 한다.
Reference
Paper URL: https://arxiv.org/abs/2111.15668
Code URL: https://github.com/MengLcool/AdaViT

1999.09.10 / LIG Nex1 AI Researcher