Abstract
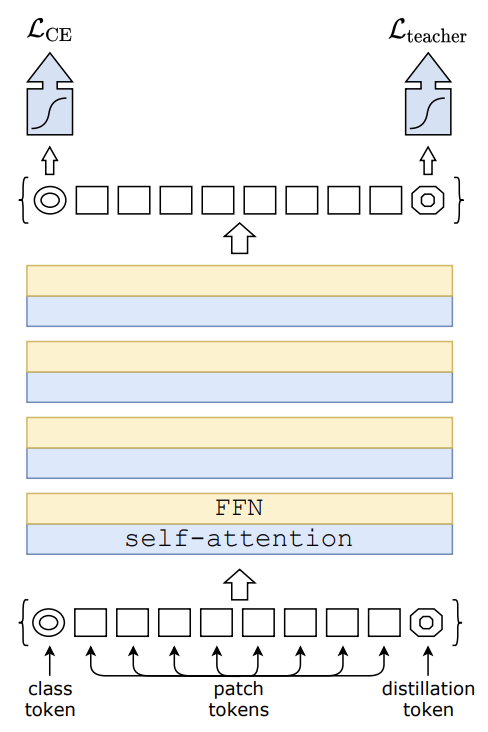
- DeiT의 특징은 크게 2 가지가 있다.
- ViT와 동일한 transformer 모델 구조를 가지고 있다.
- CNN 구조의 teacher모델의 지식을 증류 기법으로 학습한 student 모델을 사용하여 CNN의 inductive bias를 상속받는다.
- DeiT는 Knowledge Distillation 기법으로 학습되어서 데이터 효율성이 높은 모델이다. 따라서, 대규모 데이터셋이 필수 요건이 아니고 적은 데이터로도 높은 성능을 달성한다.
Introduction
- ImageNet만 활용했을 때, 본 논문에서 제안한 학습 기법 사용시 ViT보다 약 5퍼센트의 성능 향상 이 있었다고 한다.
- distillation 추가 적용 시, convolution 기반 EfficientNet보다 성능이 좋았다고 한다.
EfficientNet: 메모리와 FLOPs를 constraint로 둔 상태에서 width, depth, resolution 3가지를 모두 compound하여 accuracy를 최대화 할 수 있는 hyperparameter로 구성한 모델(coumpound)
Method
-
Soft Distillation: teacher 모델의 softmax 값 활용
-
Hard label distillation: teacher 모델의 예측값 활용
- : logit of teacher model
- : logit of student model
- : softmax function
- : groundtruth label
- : argmax_c Z_t (c)
-
실험적으로 hard label distillation with label smoothing의 성능이 더 좋았음
-
Class token 이외에 distillation token이 추가됐으며, 이로 인해서 output도 하나 추가됌
-
Loss를 2가지로 도출한다
- : Class token output에서의 예측값과 gt label 간의 loss
- : Distillation token output에서의 예측값과 teacher model smoothed label 간의 loss
-
실험적으로 class token과 distillation token이 비슷하며(not same) cosine 유사도가 0.93임을 확인하였다.
-
distillation token은 class token과는 다른 기능을 가지며, classification 성능 향상에는 도움을 전혀 주지 않는다.
-
GT label외에 teacher의 pseudo label을 함께 활용하여 fine-tuning할 때의 성능이 더 좋았다고 한다.
-
inference 단계에서 두 가지의 아웃풋인 class/distillation token을 softmax해서 더해주는(fusion) 방법을 사용했다고 한다.
Experiment

- DeiT 모델에는 크기별로 다양한 모델이 존재하는데 이들 간에는 Head 개수, 그리고 embed-dimension에만 차이가 있고 나머지는 동일하다.
- Distillation 시에 teacher의 네트워크가 CNN일 때 성능이 좋은데, 저자들은 이를 inductive bias까지 transfer 받을 수 있기 때문이라고 해석하고 있다.
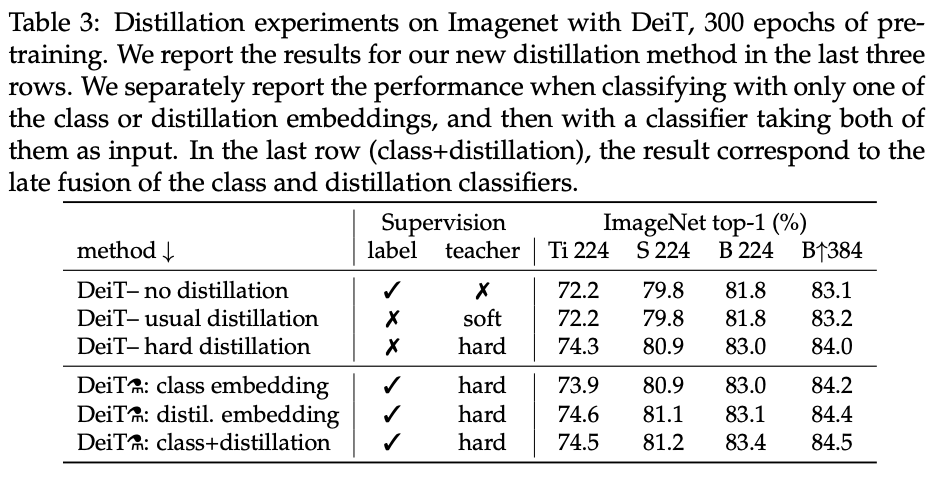
- distillation 추가 시에 성능 향상이 있었고, 이는 distillation token 방식까지 같이 추가해주었을 때 성능이 최고치였다고 한다.
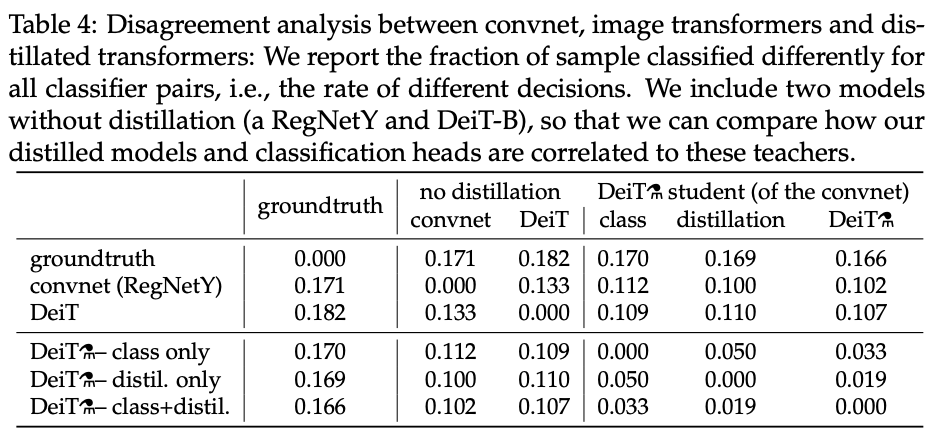
- CNN 기반의 teacher을 두었을 때 는 teacher와 비슷한 경향성을 보였다고 하는데, 이를 inductive bias transfer로 인한 현상이라고 해석한다.
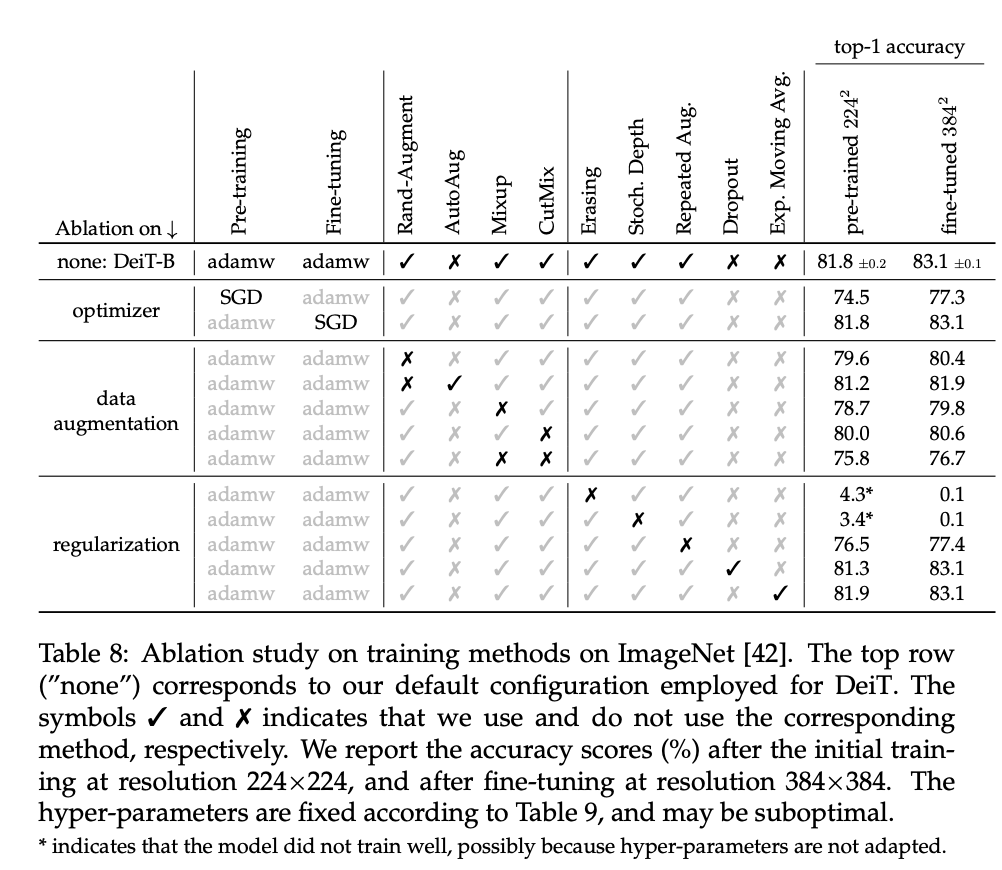
- transformer는 inductive bias가 없기 때문에 data를 augmentation 해주는 것이 매우 효과적이었다고 한다. 이때, 사용한 augmentation 방법은 mixup, cutmix, erase 세 가지이다.
Reference
Paper URL : https://arxiv.org/abs/2012.12877
Github URL : https://github.com/facebookresearch/deit

1999.09.10 / LIG Nex1 AI Researcher