Pruning from Scratch via Shared Pruning Module and Nuclear norm-based Regularization (WACV, 2024)
논문 리뷰
Abstract
- 대부분의 pruning 연구들은 pre-trained된 모델들에서 중복되는 채널들을 찾아내는 방법에 집중하고 있지만, 이는 규모가 있는 네트워크를 학습할 때의 비용과, 효율적인 재구성을 위해서 채널을 고르는 것의 중요성을 간과하고 있다고 할 수 있다.
- 본 논문에서는 “pruning from scratch”라는 framework를 제시하여, 재구성과 표현의 수용량을 고려하도록 하고 있다.
- Shared Pruning Module(SPM)은 residual block들에서 채널 alignment 문제를 다루어서, pruning 후의 손실없는 재구성을 가능하게 한다.
- 이에 더해서, pruning 과정에서도 규모가 있는 네트워크의 표현력을 보존하기 위해서 nuclear-norm 기반의 정규화를 소개하고 있다.
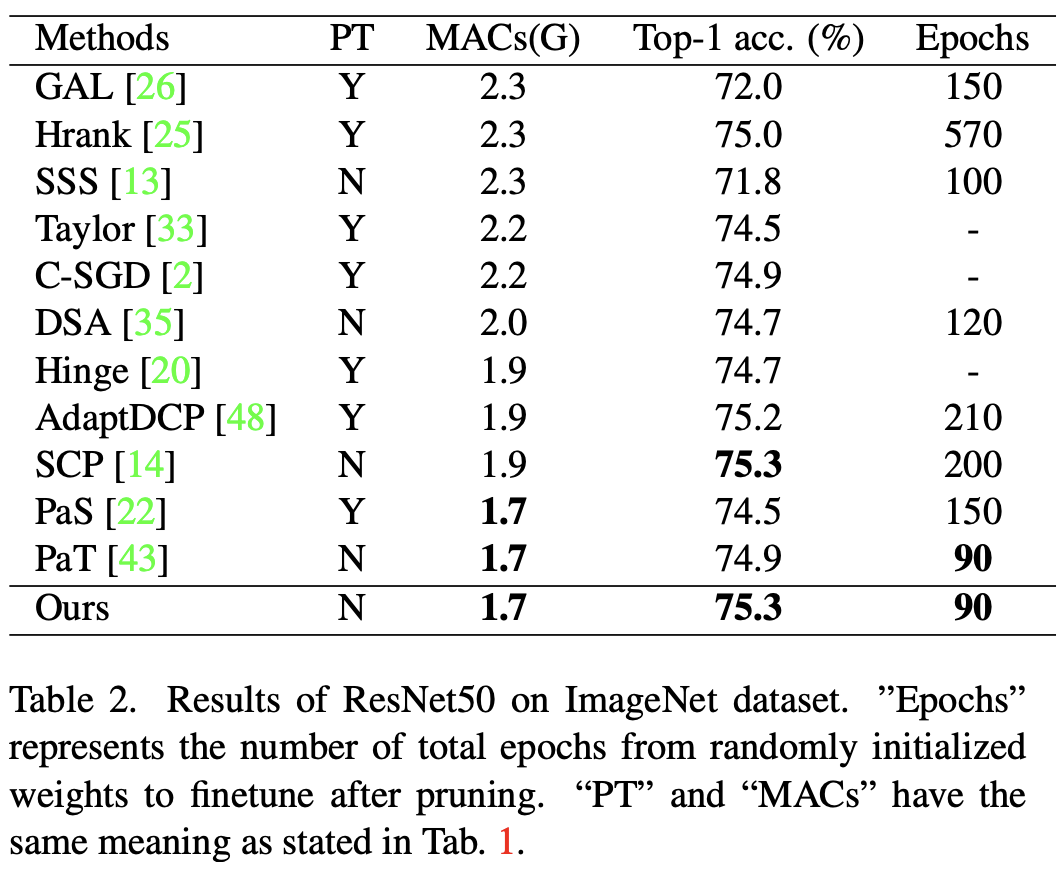
- 실험 결과적으로, ImageNet에서의 ResNet50의 MAC를 기존의 41%까지 경량화하면서도, top-1 accuracy 75.25%를 기록했다고 한다.
Introduction
-
AI의 응용 관점에서 CNN은 놀라운 성과를 거두었고, 점점 더 좋은 성능을 제시함에 따라 계산복잡도도 따라서 증가하고 있다. 이는 edge devices에서의 배치를 부담스럽게 하고 있다.
-
이를 해결하기 위한 방법에는 여러가지가 있지만 그중 네트워크 pruning은 성능 감소를 최소화하면서도 자원 요구량을 줄일 수 있는 효과적인 방법 중 하나이다.
-
structured pruning은 중복되는 channel들을 layer에서 제외시킴으로써 inference 시간을 감소시킨다.
-
structured pruning은 크게 2 가지의 접근으로 나뉠 수 있다.
1. importance-based: norm이나 geometric median과 같은 heuristic 방식을 이용하여 channel의 중요성을 평가한다.
2. regularization-based: pruning 과정에 regularization loss를 포함시켜서 네트워크를 pruning한다. -
structured pruning 방식들은 주로 3단계 pipeline을 거치는데,
1. 규모가 큰 네트워크가 수렴하고 높은 성능으로 task를 처리할 정도가 될 때까지 사전학습을 진행한다.
2. 이러한 네트워크에서의 중복되는 채널들을 특정한 pruning 방식에 의거하여 제거한다.
3. 최종적으로 prune된 네트워크는 성능 감소를 최대한 무마하기 위해서 fine-tuning을 거친다. -
이러한 방식들은 마지막 2개의 단계들에 집중해서 잘 진행되어 왔고 좋은 결과를 보여왔다. 하지만, 이렇게 규모가 큰 네트워크들을 수렴할 때까지 학습시키는것은 어렵고 시간이 오래걸리는 전반적인 효율을 떨어뜨리는 일이다.
-
importance-based 접근방식을 사용하면 채널의 중요성을 찾기가 어려워지기에, 시간이 지남에 따라 서서히 네트워크를 prune해주는 regularization-based 접근방식을 택했다고 한다.
-
하지만 direct하게 적용되면 정보 손실이 너무 심하기에 본 논문에서는 이를 해결하기 위해 indirect하게 pruning 모듈에 적용하는 방법을 적용한다.
-
structured pruning을 통한 실질적 가속화에는 실제로 masked channel들을 제거해주는 재구성 과정이 필요하다.
-
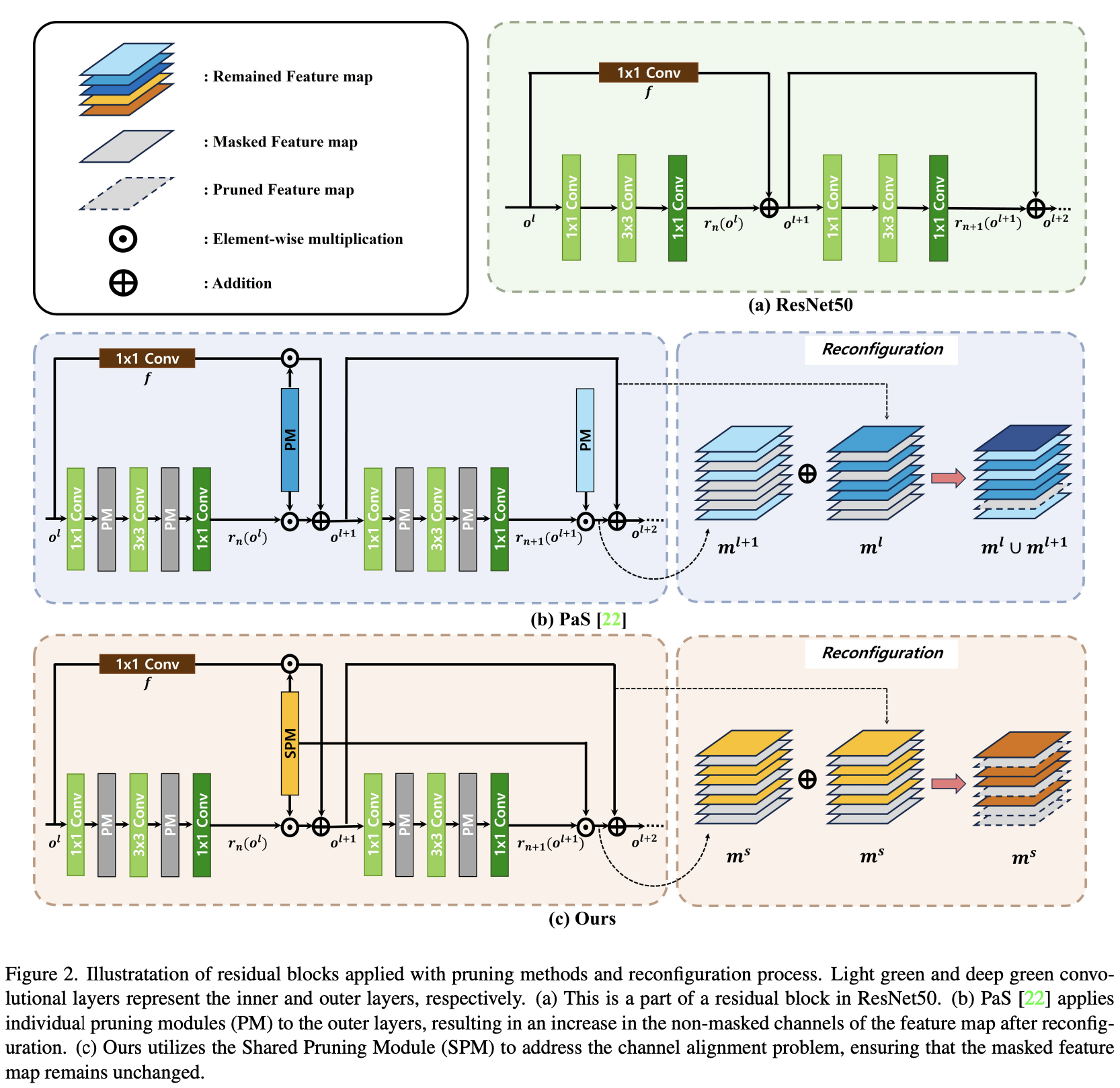
residual block들은 컨볼루전 layer들로 구성되어있고, 이들은 shortcut connection과의 관계를 기준으로 inner과 outer layer로 구별 될 수 있다.
-
inner layer들은 독립적으로 작용하기 때문에 재구성이 쉽지만, outer layer들은 channel alignment를 고려하지 않고 재구성하게되면 성능이 떨어지게 된다.(shorcut connection과 연결되어 있기에)
-
본 논문은 SPM을 제시함으로써 outer layer들을 prune하여, 성능을 보존함과 동시에 효율적인 네트워크 압축을 가능케 한다.
-
올바른 채널을 선택하도록 pruning module을 인도해주는 것은 중요하며, 효율적인 표현력을 유지하기 위해선 네트워크의 성능을 관리 및 유지하며 이루어져야 한다.
-
본 논문에서는 MAC를 pruning 하는 쪽으로 모듈을 인도하는 과 pruned network의 표현력을 유지하기 위해 모듈을 인도하는 총 2 가지의 loss를 제시한다.
Related Works
- Structured pruning
- Reconfiguration after pruning
- Pruning from Scratch
Methods
- 본 논문은 Pre-trained model로부터 자유로운 pruning from scratch방식을 위한 framework를 제시하고 있다.
- SPM으로 재구성을 위한 channel alignment 문제를 네트워크 크기 증가 없이 해결하며, 제시된 regularization 방식으로 표현력을 유지하면서 모델의 계산량을 원하는 정도까지 감소시킨다.
3.1 Shared Pruning Module (SPM)
- structured pruning은 성능에 가장 영향이 적은 필터들을 제외시켜서 네트워크의 크기를 줄인다
- 이 pruning indicator이고, 을 제거할지 말지 결정한다. Indicator function인 보다 크면 1, 나머지 경우에는 0이 되게 만드는 이진 마스크로 볼 수 있다.
- 이러한 이진화 과정 때문에 미분이 불가능해지는 문제가 발생하는데 이것을 해결하기 위해서 STE라는 방식을 사용하여 Back Propagation이 가능하게 만든다.
Straight Through Estimator(STE):
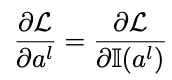
- gradient들의 direct passing을 가능하게 하는데, 이로써 네트워크들은 heurisitc criteria와 관계없이 자동으로 pruning 될 수 있다.
- 현대 네트워크들은 자주 residual block을 추가하여 gradient 소실을 해결하는 성능 개선을 사용하는데, residual block들은 주로 이런식으로 쌓인다.
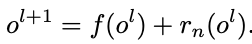
- pruning module들은 outer layer들을 포함한 모든 convolutional layer 뒤에 붙게 된다. 또한, 연달아 쌓인 residual block들이 있다.
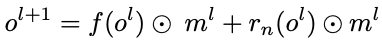
- 첫 번째 residual block 경우에는 위 식과 같이 shortcut connection이 작동하며 binary mask 는 pruning module의 indicator에 의해서 생성된다.
- 는 1x1 convolution layer과 bottleneck의 output layer 둘 다에 적용되기 때문에 합연산들은 모두 같은 마스크를 사용하여 행해진다.
- 결과적으로, output feature map의 pruned channel들은 재구성 뒤에도 변하지 않는다. 하지만, 첫 residual block의 후속 block들은 초기 블록과 같지 않다는 점은 인지해야 한다.
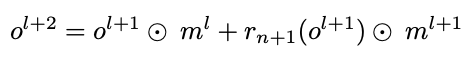
- 후속 shortcut connection 연산들에서는 합연산 시에 다른 이진 마스크들인 를 사용해서 행해진다.
- 합연산 전에 마스크들이 적용이 되며, 마스크들은 각기 다른 pruning indicator들에 의해 생성이 되기 때문에 다양한 수나 서로 다른 indice의 masked channel들을 가지고 있을 수 있다.(이를 channel alignment problem이라고 칭한다)
- binary mask들 사이의 불일치는 결국에는 네크워크 구조나 2개의 레이어 사이의 계산 flow 불일치로 이어질 수 있다.
- 성능 저하없이 binary mask로 네트워크를 재구성 하기 위해서는 union operation이 필요하며, 논문에서는 이를 이용하여서 binary mask인 를 합쳐주고 있다.
- 이러한 channel alignment problem으로 인해서 합연산이 이루어지고 나면 실질적으로는 pruning이 되지 않은 상태가 된다. 따라서 SPM을 제시하여서 masked channel를 이전 레이어의 masked channel에 맞춰주도록 한다.
3.2 Regularization for pruning from scratch
- 두 개의 regularization term인 2개를 소개하고 있다.
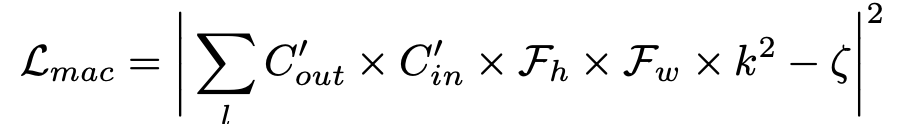
- target MAC와 현재 MAC의 차이에 대한 squared norm 형태를 보인다.
- 하지만, target MAC만을 추구하기 보단 성능 개선도 생각을 해야한다.
- 이를 해결하기 위해서 본 논문에서 추천하는 방식은 각 layer 마다의 표현력을 유지하는 것이다.
- 수학적으로 보았을 때 rank의 개념이 표현력을 표현하기 위해 사용될 수 있다.
- 정수값 만을 이산적으로 표현할 수 있는 rank 개념을 그대로 loss에 적용하는 것은 쉽지 않기 때문에, 저자들은 nuclear norm을 사용하여 더 유연하고 연속적인 표현을 가능케 한다.
- nuclear norm은 matrix의 singular value들의 norm이다.
- nuclear norm은 L1, L2 regularization 여부에 따라 달라지며, 웨이트들을 줄이는 것뿐만 아니라 표현력의 용량을 평가한다.
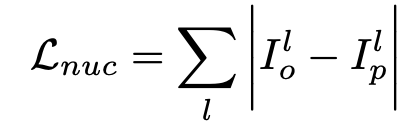
- 는 각각 original layer와 pruned layer의 표현력을 나타낸다.
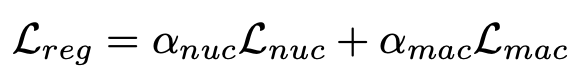
- 위 식에서 는 scale factor이라고 한다.
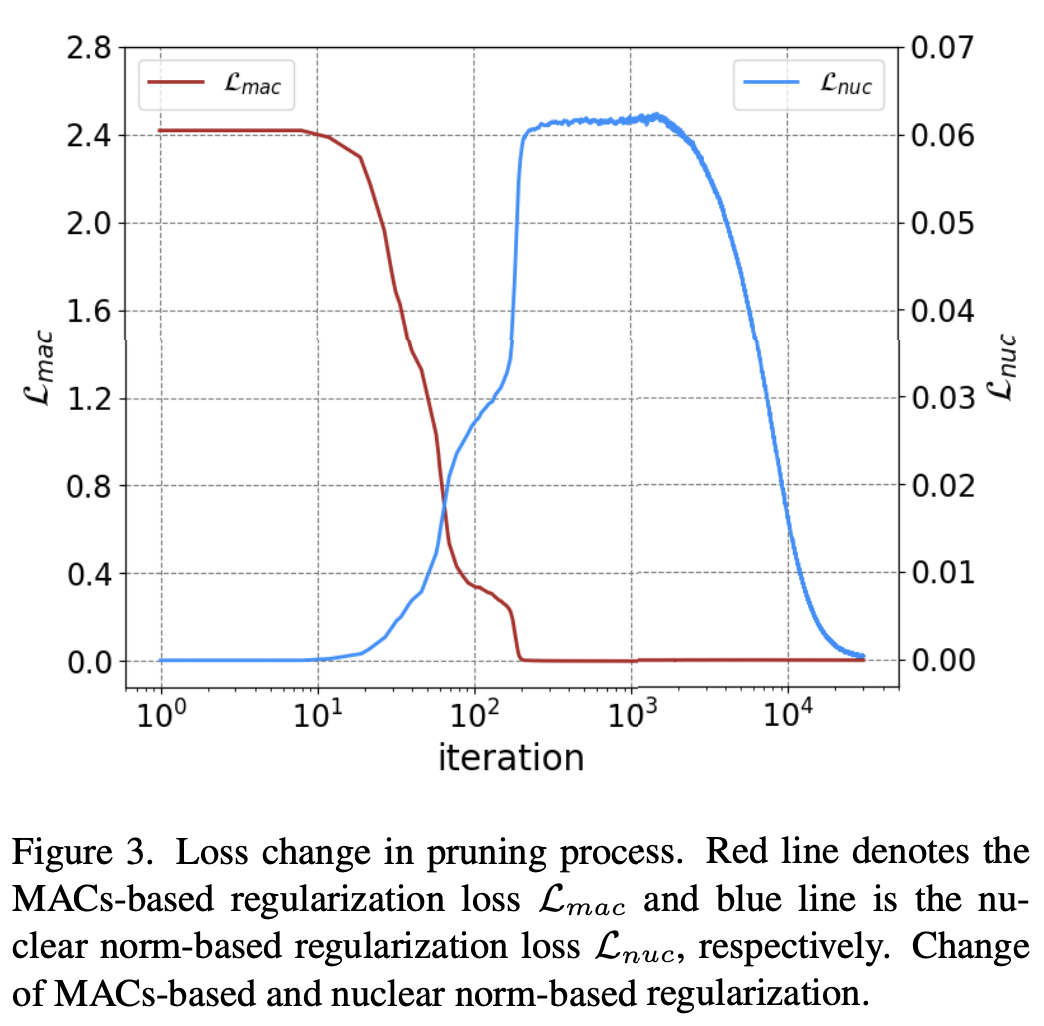
- 이렇게 두 loss를 combine해서 사용하여 성능 저하를 최소화하면서도 계산량을 줄일 수 있었다고 한다.
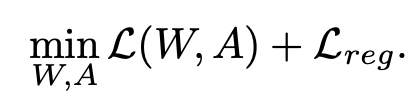
- 이러한 regularization과 classification loss를 합해서 최종 loss function을 완성했다고 한다.
Experiment