Abstract
- 성능 좋은 시퀀스 변환 모델은 대체로 인코더와 디코더를 포함한 복잡한 RNN 또는 CNN 신경망에 기반을 두고 있음
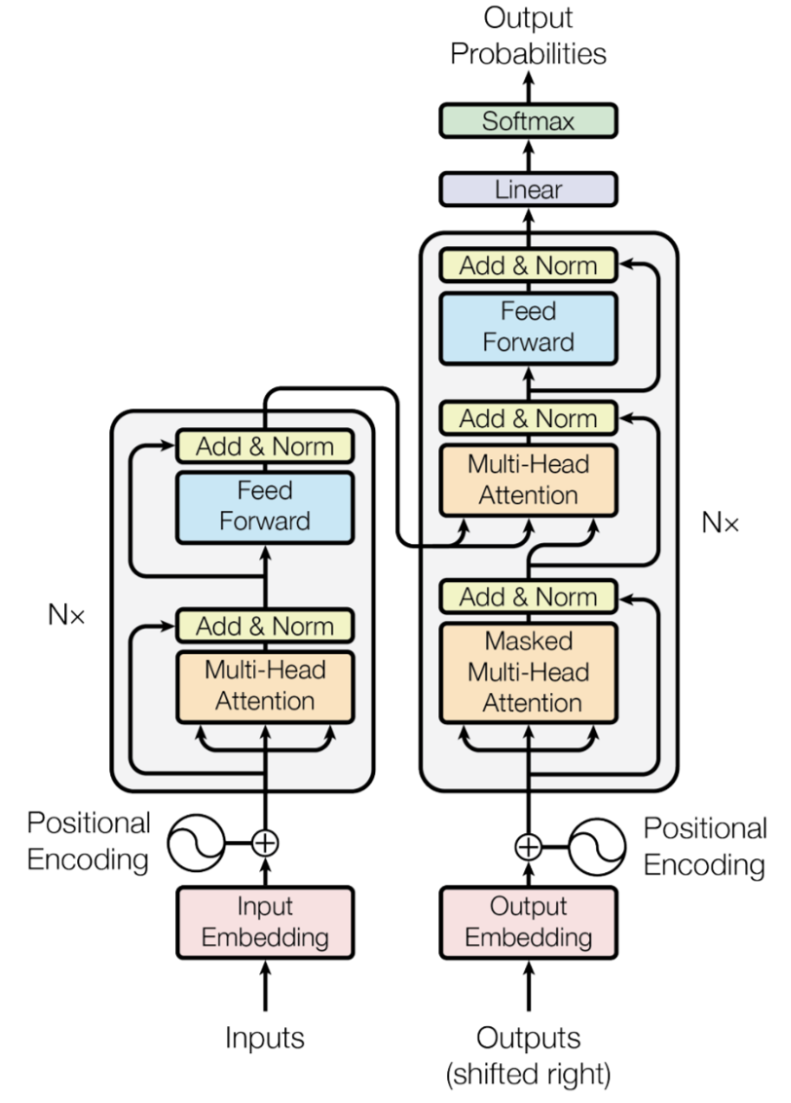
- 본 논문은 재귀적으로 시퀀스를 처리하지 않는다는 점과, 컨볼루전을 제외하였다는 점, 그리고 오직 attention mechanism에만 기반한 Transformer이라는 모델을 제안한다.
- 오직 행렬의 곱만을 이용해서 병렬적으로 시퀀스 데이터를 처리할 수 있다. (속도 개선, 계산량 감소)
- 크거나 한정된 학습 데이터를 가지고도 성공적으로 일반화가 가능함.
Introduction
- RNN, LSTM, GRU와 같이 이전에 시퀀스 모델링과 변환 문제에서 뛰어난 성과를 보이던 회귀 모델들은 주로 입력과 출력의 symbol position에 따라 계산을 수행했었다.
- 문제점 : 순서대로 계산해야 해서 병렬처리가 불가능(느리고, 효율성이 떨어진다.), 길이가 긴 시퀀스를 처리하기에 적합하지 않다(기울기 소실 발생, 메모리 효율 낮음)
Method
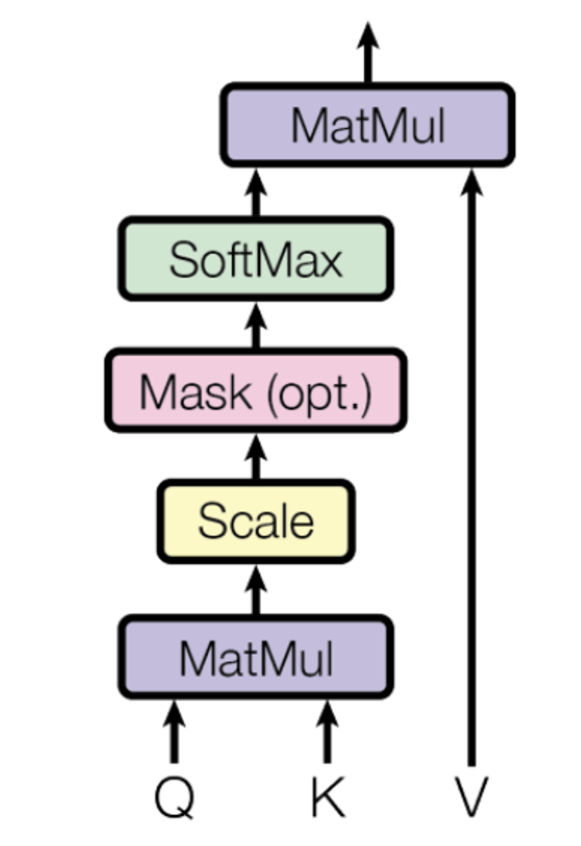
1. Scaled Dot-Product Attention
- self attention : 다른 pos와 자신의 pos간의 상호작용을 캡쳐하는 것을 뜻한다.
- Q와 K를 내적하고, dk(key의 차원수)의 제곱근으로 나누어 스케일링 해준다.
- Query: input 단어(알아보고자 하는 단어)
Key: 문장의 모든 단어를 벡터로 쌓아놓은 행렬
Value: 데이터 들의 값 - Q dot K 를 하여서 relation matrix를 구해냄(Q와 문장의 모든 단어들과의 관계를 구함)
dk의 제곱근으로 scaling하여 값들을 0 근처로 근사하게 만든다.(기울기 소실 해결)
softmax로 확률 분포화 시킨 후에 value matrix와 내적하여서 관계의 정보를 업데이트 시킨 값을 구해낸다.
2. Multi-Head Attention
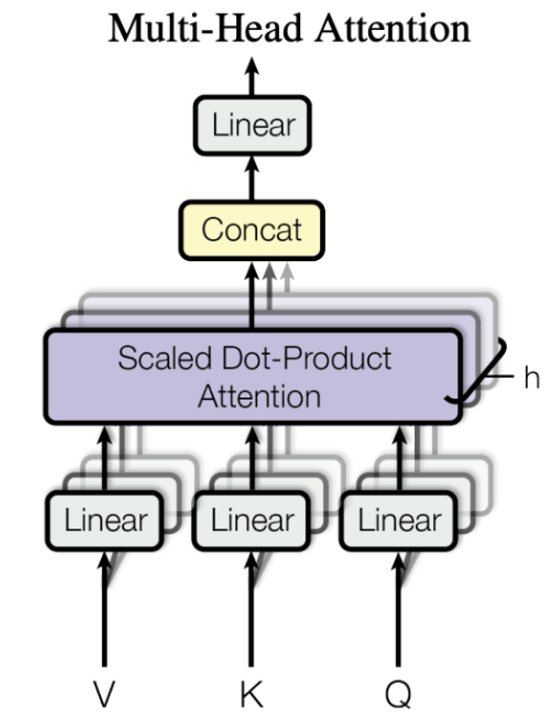
- Q, K, V를 선형변환(공간변환)한 후 위에서 설명한 Scaled Dot-Product Attetnion에 넣어준다.
- 중요한 점은 h라는 header을 정해주어서 마치 CNN에서 필터 수를 여러 개로 늘려주어서 다양한 관점에서 self attention을 진행하게 되고 이는 모델을 더 강력하게 만든다.
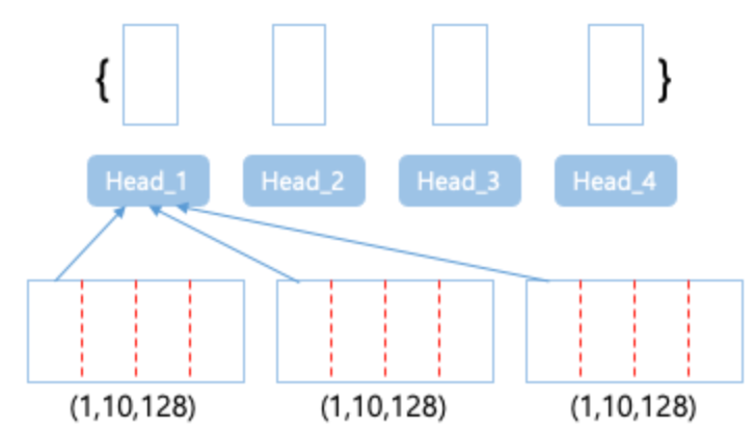
- 그림과 같이 QKV를 공간변환한다
(QKV 128차원, 1개→ QKV 32차원, 4개) - 이렇게 쪼갠 것을 병렬화 하여서 attention을 진행한 후 나온 4개의 결과 행렬을 concate해주어 합친 후에 projection을 하여서 다시 기존 공간으로 돌려보낸다.
- 장점: 다양한 관점에서의 attention으로 인한 정확도 향상 및 병렬 처리로 인한 속도/효율 향상!
3. Position-wise Feed-Forward Networks
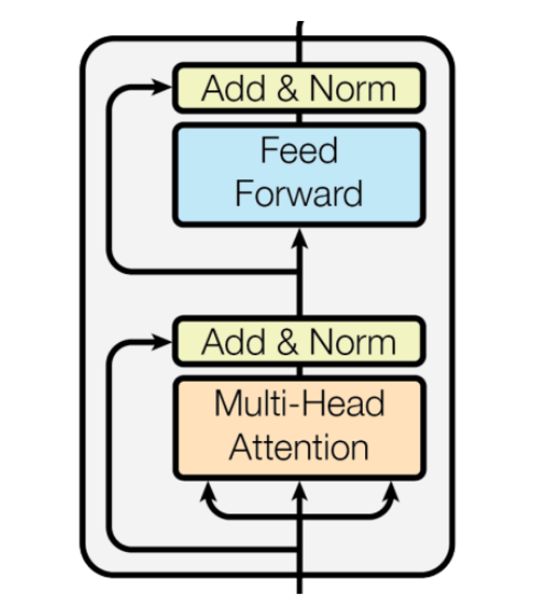
- 각 Multi-Head Attention 이후에는 Feed-Forward를 통과 하게 한다.
- Feed-Forward의 구조는 [Linear-ReLU-Linear]의 형태를 가지며, 더 큰 차원의 은닉층으로 선형변환하여서 복잡한 관계를 추가로 연산을 하는 것이다. 비선형성 및 깊이를 부여하는 역할을 한다.(MobileNetV2에서의 hidden value와 비슷하다…?)
4. 3 types of Attention Layers
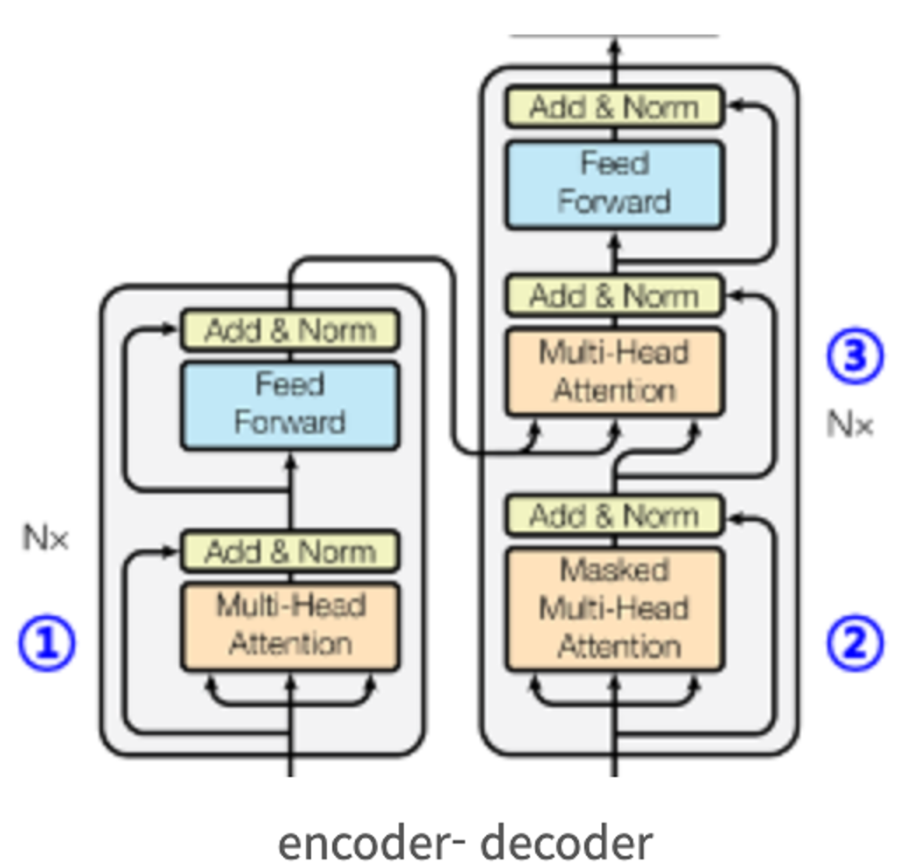
1) Encoder Attention
- QKV 모두 encoder의 output에서 가져오며, 자신의 pos(Q)와 문장의 다른 모든 pos(K)의 self-attention을 계산하여 representation을 구해낸다.
- 이렇게 구해진 representation을 추후에 encoder-decoder attention에서 K와V로 사용한다.
2) Decoder Attention
- 지금의 pos(Q) 이후의 단어들은 mask를 씌워서 이후의 sequence들은 보지 못하게 하여서 개연성이 없는 미래 정보를 볼 수 없게 하는 방식이다.
- Q가 한칸씩 옮겨갈 때마다 mask의 pos도 한칸씩 우측으로 shift된다.
- 즉, 현재 pos(Q)와 현재 위치를 포함한 이전 모든 pos들만을 남기고 나머지를 가린(K) 단어들과의 self-attention을 계산하여서 information을 도출한다.
이렇게 도출된 information은 encoder-decoder attention에서 Q로 사용된다.
3) Encoder-Decoder Attention
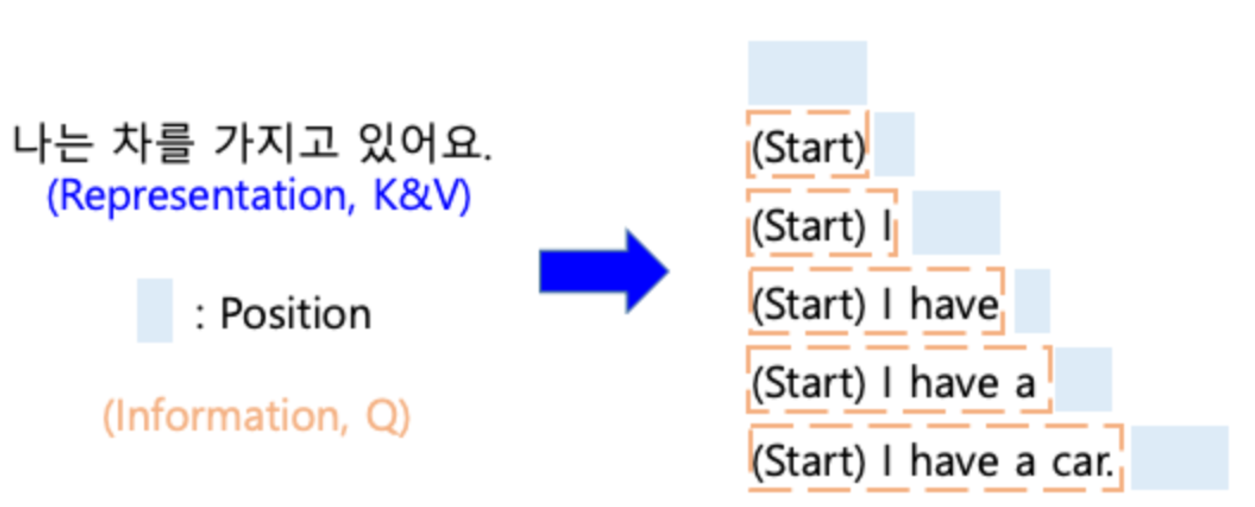
- 위에서 말한 representation을 K,V로 information을 Q로 이용하여서 attention을 진행하는 방식이다.
- Q가 단어 하나가 아니라는 점에서 다른 것 같다(?)
5. Positional Encoding
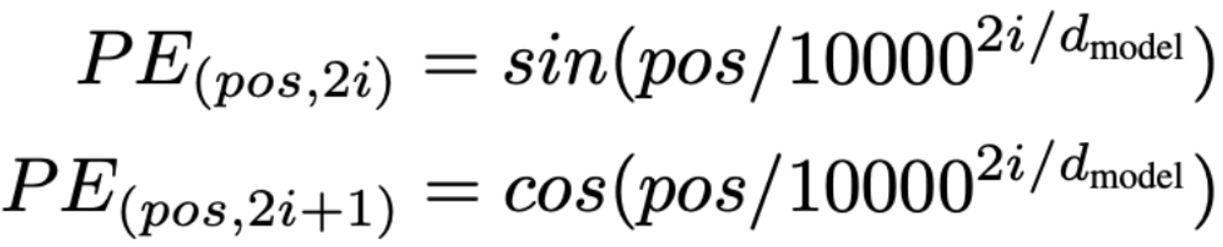
- Transformer와 RNN 계열 모델의 가장 큰 차이는 word-by-word가 들어가는 것이 아닌 문장을 통째로 넣어준다는 점이다. 또한, 이에 따라서 예측하려는 단어(pos)가 어디인지 반드시 명시해주어야 한다.
- 이때, 선형함수가 아니라 삼각함수를 사용하는데 2가지 장점을 가지게 된다.
장점1 : 각 sequence에 적용하는 경우에도 위치별로 극심한 값의 차이가 없다.
장점2 : pos마다 서로 다른 값을 가진다.
6. Reference
Paper URL : https://arxiv.org/abs/1706.03762
Github URL : https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/transformer.py

1999.09.10 / LIG Nex1 AI Researcher