Abstract
- 논문에서는 모바일/임베디드 비전 애플리케이션에서 효율적인 모델들을 제시한다.
- 무게가 가벼운 신경망을 개발하기 위해서, 깊이에 대해 분리가 가능한 컨볼루젼들을 사용하는 유선형의 모델 구조를 기반으로 하고 있다.
- latency와 accuracy를 효율적으로 trade-off해주는 global parameter을 2 가지 소개한다.
- 이러한 hyperparameter들은 문제의 제약에 따라 어떤 모델이 최적의 사이즈인지 model builder가 선택할 수 있도록 한다.
Introduction
- CV에서 CNN은 계속해서 유명해져왔고, 트렌드는 더 깊고 복잡한 네트워크를 개발해서 정확도를 높이는 것이었다. 하지만, 이러한 접근방식은 크기나 속도 관점에서는 전혀 네트워크를 발전시키고 있지 않다. 자율주행이나 로봇과 같은 분야에서는 제한된 하드웨어에서 시간제약을 가지고 연산을 해야하기 때문이다.
- 본 논문에서는 작고 지연시간이 낮은 모델을 설계하기 위해서 필요한 2개의 hyper parameter과, 네트워크 구조를 제시한다.
- 2개의 hp는 각각 “width multiplier”와 “resolution multiplier”이라고 한다.
Method
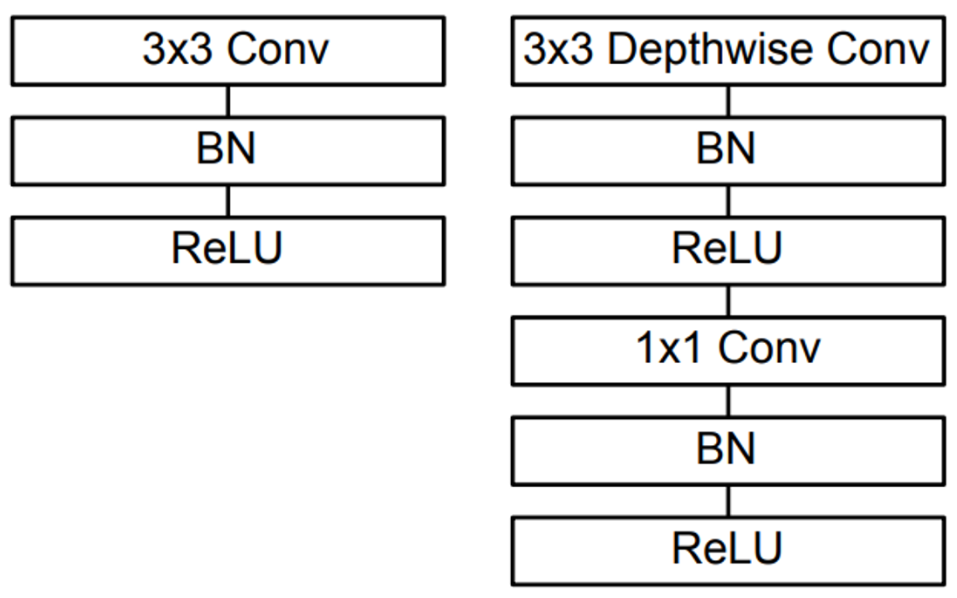
- 기존의 방식들은 filtering과 combining을 동시에 진행하지만 논문에서는 2 가지의 layer을 따로 나누어서(factorization) 진행하는 방식을 제시하여 계산량과 모델의 크기를 극적으로 줄였다.
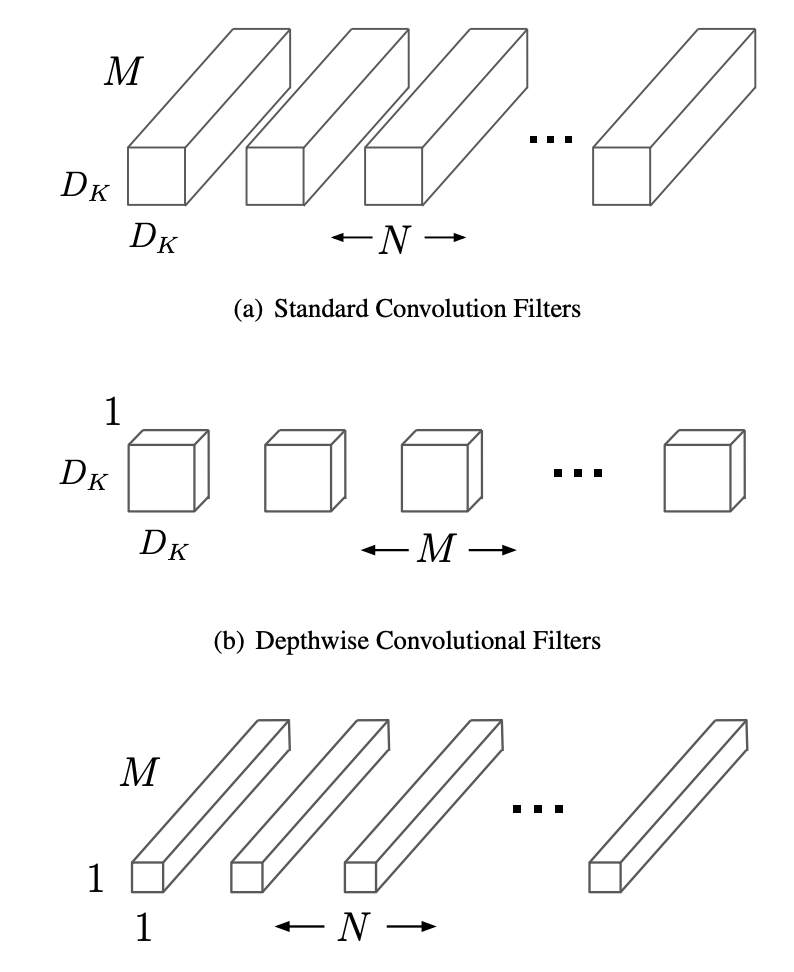
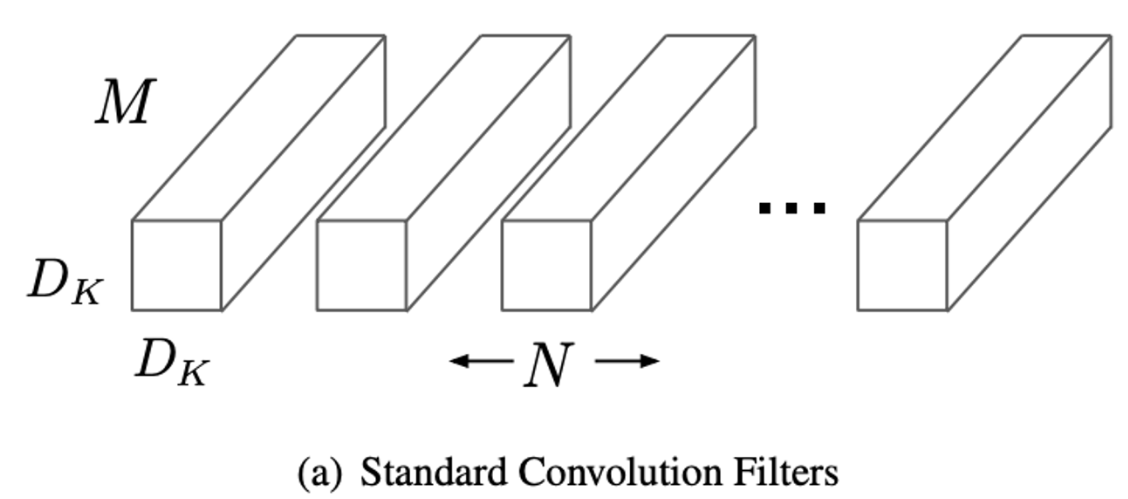
1. Standard Convolution
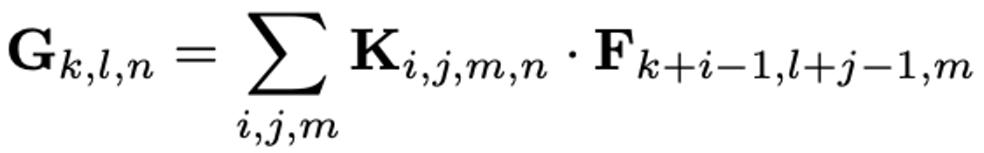
1) Feature Map
(spatial width) / (height of square input feature map)
= (spatial width) / (height of kernel size)
Number of input channels (depth)
Number of output channels (depth)
2) Computational Cost
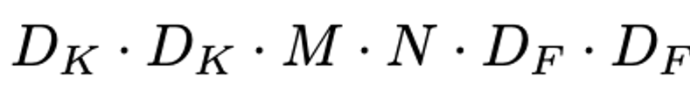
2. Depthwise Seperable Convolution
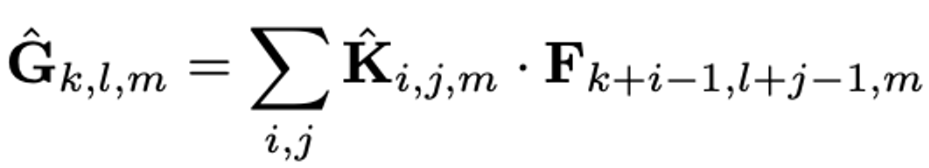
1) Depthwise Convolution
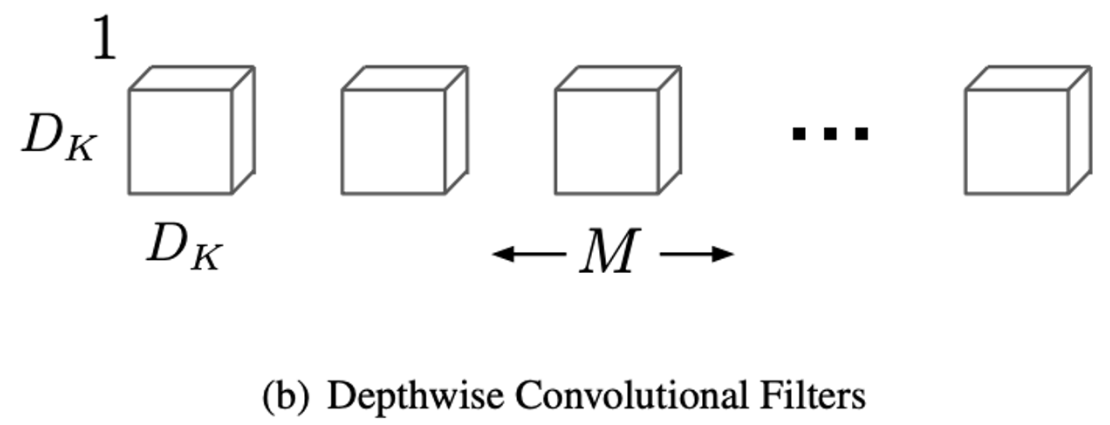
: to apply a single filter per each input channel
2) Pointwise Convolution
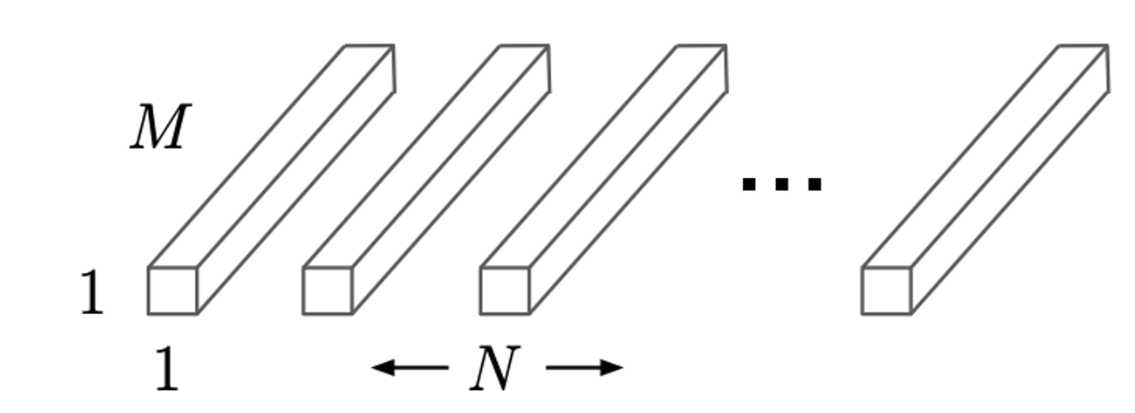
: to create a linar combination out of the output
→ Both batch norm and ReLU nonlinearities are used for both layers
3) Computational Cost
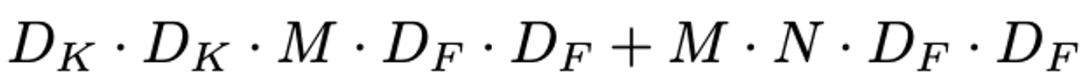
- Filtering과 Combining 총 2단계의 과정으로 나눔으로써 계산량을 1/N^2 + 1/Dk^2 으로 줄어들게 된다고 한다.
Network Structure
Reference
Paper URL : https://arxiv.org/abs/1704.04861
Github URL : https://github.com/pytorch/vision/blob/main/torchvision/models/mobilenetv2.py

1999.09.10 / LIG Nex1 AI Researcher