An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ICLR 2021)
논문 리뷰
목록 보기
5/21
Abstract
- Transformer 구조는 등장 이래로 자연어 처리 분야의 표준으로 자리잡았고 컴퓨터 비전 분야에서 적용은 한정적이었다.
- 비전 분야에서 attention은 CNN과 함께 적용되거나 convolution의 전체적인 구조는 유지하면서 특정 요소만 대체하는 데 사용되었다.
- 본 논문에서는 convolution network 의존이 필수가 아니고, pure transformer을 image patches의 sequence에 직접적으로 적용하는 것이 상당히 좋은 성능을 낸다는 것을 입증한다.
- 기존의 convolution network보다 train에 필요한 연산량이 크게 감소하면서도 성능이 매우 훌륭하다.
Introduction
- self attention 기반 구조는 자연어 처리에서, transformer의 연산 효율성과 확장성 덕분에 100B 파라미터 이상의 크기 모델을 훈련하는 것이 가능해졌고, 현재까지 성능 포화 징조는 보이지 않는다.
- 하지만, computer vision에서는 convolution구조가 여전히 우세했지만, 여러 연구가 self-attention을 CNN-like 구조와 결합하여 일부는 Convolution을 완전히 대체하기도 하였다.
- 이러한 모델들은 이론상 효율적이었지만 특수한 attention 사용 때문에 하드웨어 가속기에서는 아직까지 효율적으로 작용하지는 못했다.(Resnet-like 구조를 아직까지는 이기지 못했음)
- NLP에서의 성공적인 scaling에서 영감을 받아서 본 연구에서는 가능한 극소량의 변형만을 거친 표준 transformer 모델을 이미지에 직접적으로 적용하는 실험을 진행한다.
- 이미지를 patch 단위로 분리하고, 선형 임베딩 시퀀스를 입력으로 하여 transformer 모델에 전달한다.
- Image patch들은 word token과 같은 방식으로 취급된다.
- ImageNet과 같은 mid-sized dataset에 regularization 없이 훈련시킬 때, 이러한 모델은 비슷한 크기의 ResNet보다 몇 % 더 낮은 정확도를 보인다.
- 하지만 모델이 더 큰 데이터셋으로 훈련된 경우에 inductive bias를 이겨낸다는 사실을 발견한다. 즉, ViT는 충분한 규모로 사전학습된 다음에 더 적은 양의 데이터포인트를 갖는 task에 전이시키면 훌륭한 결과를 얻을 수 있는 것이다.
Method
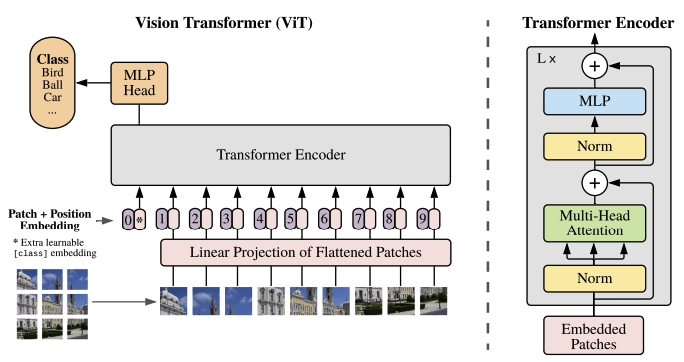
- Transformer의 input 값은 1차원 sequence 이기 때문에 고정된 크기의 patch로 나눠준 이미지를 1차원으로 flatten 해주어야 한다. HWC 형식의 이미지(원본)를 NPPC로 변환하는 과정이다.
여기서 N은 sequence의 수, PP는 패치의 크기, C는 이미지 채널, (H/W)는 이미지의 높이/너비 이다. - 이렇게 1차원으로 바꾼 이미지를 transformer에 사용할 수 잇는 D차원의 벡터로 바꾸어준다.
- 이렇게 만든 이미지 토큰에 classification을 하기 위해서 extra learnable class token을 추가하여 같이 넣어준다.

- 당연하지만, 중요한 점은 ViT도 역시 Transformer답게 정말 많은 데이터로 Pre-Training하지 않으면 좋은 성능을 기대할 수 없다. ViT도 구글 내부 이미지 약 6억장 정도로 Pre-Training 되었다고 하니 이를 Fine-Tuning 하여 사용하는 것이 좋다.
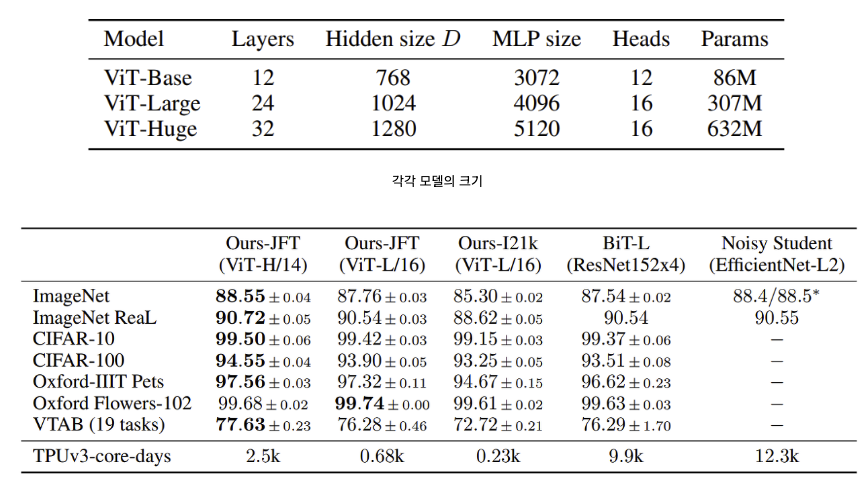
Experiment
Reference
- https://velog.io/@choonsik_mom/Vision-TransformerViT-논문-리뷰
- https://hipgyung.tistory.com/entry/쉽게-이해하는-ViTVision-Transformer-논문-리뷰-An-Image-is-Worth-16x16-Words-Transformers-for-Image-Recognition-at-Scale
- 이해하기 쉬운 GIF = https://github.com/lucidrains/vit-pytorch/blob/main/images/vit.gif
{kind=link}
Paper URL : https://arxiv.org/abs/2010.11929
Github URL : https://github.com/google-research/vision_transformer

1999.09.10 / LIG Nex1 AI Researcher