Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation
논문 리뷰
목록 보기
10/21
Abstract & Introduction
- 본 논문에서는 self-distillation 학습 방법을 제안한다.
- 전통적인 knowledge distillation인 사전 학습된 teacher 네트워크의 출력을 softmax처리 한 값을 활용하는 방법과 다른 self-distillation은 모델 내부의 지식을 증류하는 방식을 활용한다.
- 일반적인 지식 증류와는 다르게 teacher과 student model이 같은 모델이다.
- Cross entropy는 student의 output과 GT label 사이의 loss를 구하는 것이고, KL divergence는 분포가 서로 어떻게 비슷한지를 distance로 구하는 것이다.
- t가 커지면 loss surface가 평평(soft)해지며, 그럴수록 일반화가 잘된다.
Method
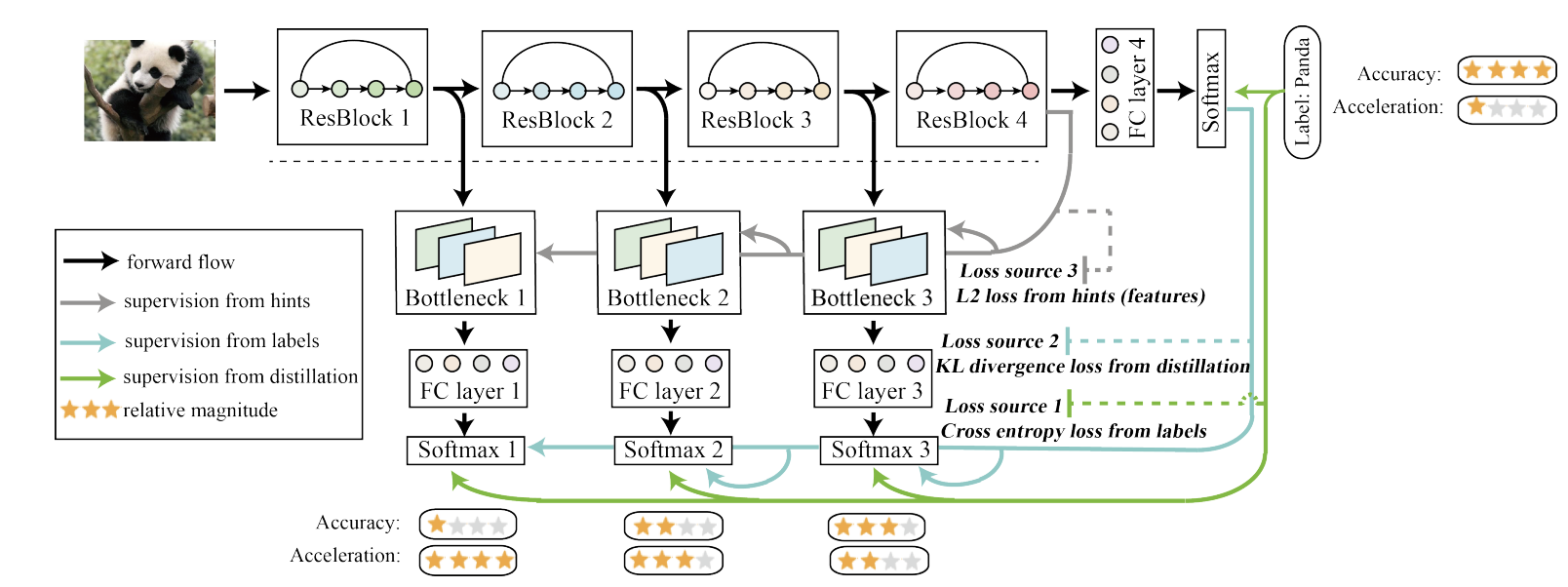
- block을 기준으로 student를 3가지로 나누어서 증류한다.
- block이 깊어질수록 정확도는 올라가지만 속도는 감소하는 trade-off가 있으며 선택해서 사용할 수 있다는 장점이 있다.
- loss는 3가지로
- Teacher을 따라가는 KL Divergence loss
- GT를 따라가는 Cross-Entropy loss
- Teacher의 feature map을 따라가는 L2 loss
가 있다.
Experiment
- noise를 주어도 강해진다.
- block 내부에서의 vanishing gradient 문제를 어느정도 해결해준다.
- block 내에서 conv layer들 간의 gradient 정도를 좀 더 서로서로 비슷하게 만들어준다.
- classifier이 깊어질수록 좀 더 집중된 클러스터링을 보인다.

1999.09.10 / LIG Nex1 AI Researcher