Introduction
- 기존의 ViT window는 고정적이기 때문에 segmentation 하기가 어려웠다.
- Swin Transformer는 window를 세밀하게 쪼개는 것뿐만 아니라, 여러 모양의 window를 이용한다.
- 단순하게 window 이용에서 그치지 않고 shift까지 적용하고 self-attention을 수행한다.
- 기존의 ViT는 고해상도 이미지에 대해서 computatuonal complexity가 복잡해지는 문제가 있기 때문에 해상도(픽셀)이 늘어날수록 모든 patch 조합에 대해 self-attention을 수행하는 것은 불가능해진다.
- Swin transformer은 계층적 feature map을 구성함으로써 이미지 크기에 대해 linear complexity를 가질 수 있도록 고안된 구조를 가진다.
Method
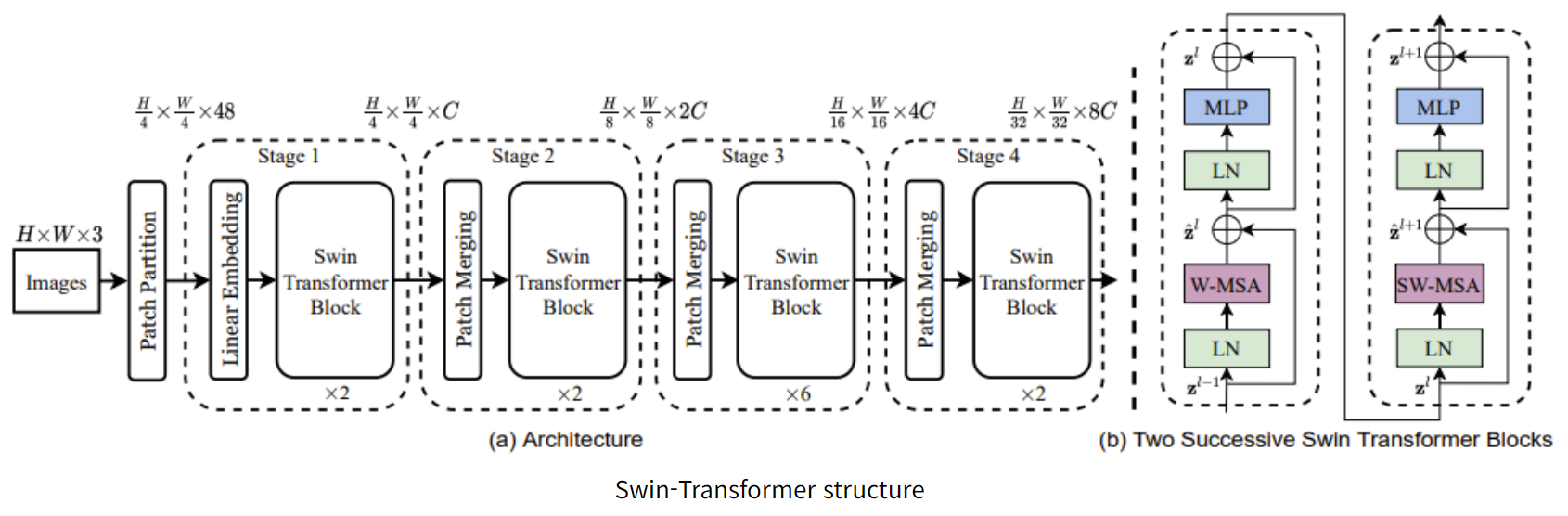
- Image들을 일단 patch로 만들고, swin transformer block에 넣어주는 형태를 반복하는 구조를 가지고 있다.
- 중간 과정에 Patch Merging이라는 patch들을 합쳐서 크기를 늘려주는 과정이 포함되어있다.
- Swin Transformer Block을 보면 W-MSA와 SW-MSA가 있다. 이것이 Swin의 가장 큰 핵심이고 shift를 MSA에 적용하는 형태라고 볼 수 있다.
MSA vs W-MSA
- Swin Transformer에서 MSA는 Multi-Self-Attention으로 MHA과 같은 개념이라고 볼 수 있다.
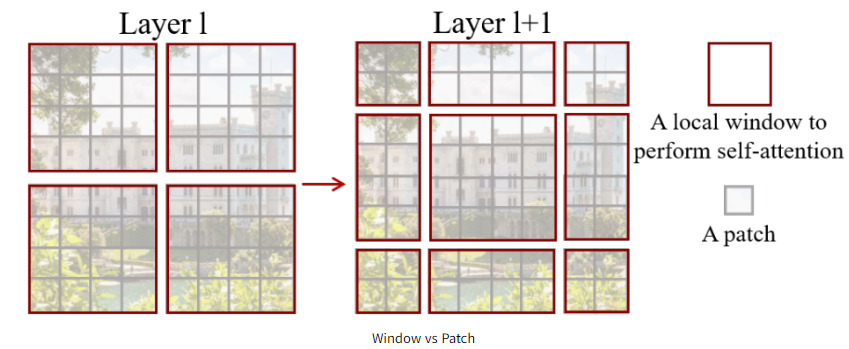
- Patch란 image를 구성하는 조각의 개념이고, window는 patch를 묶고 있는 개념이다. (window 속 patch size는 4x4이다.)
- 효율적인 모델링을 위해서는 self-attention을 window안에서 수행하면 되기에, window는 non-overlapping한 방법으로 균등하게 분할되도록 배열할 수 있다.
- 이미지는 근처 픽셀끼리의 연관성이 매우 높기 때문에 근처 patches만 이용해서 self-attention을 수행하여 연산량도 줄이고 세밀한 부분에서의 픽셀간의 연관성을 파악하기 위한 목적이 있다. 이것이 바로 W-MSA이다.
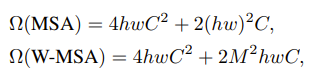
- h, w가 클수록 연산량이 급격히 증가한다.
SW-MSA
- SW-MSA는MSA를 적용하기 전에 shift를 시키는 과정이다.
- 윈도우가 나뉘어 있는데 각자 다른 개수와 차원을 가지고 있다. 이를 모두 고려해서 연산을 하게 되면 모델이 매우 복잡해질 것이다.
- 이를 해결하기 위해서 cyclic shift를 이용해서 왼쪽에 있는 window를 오른쪽 아래로 이동시킨다.
- 또한, Masked MSA를 적용하는데, 사진에 있는 A,B,C 구역에 mask를 적용해서 self-attention이 적용되지 못하도록 한다. 그 이유는 A,B,C는 왼쪽에 있는 픽셀들의 값이기 때문에 오른쪽에 위치한 pixel과의 연관성이 거의 없다고 볼 수 있기 때문이다.
- Mask MSA연산이 끝난 후에 다시 window를 원상복귀 시킨다. 이러한 SW-MSA를 통해서 window간의 연결성과 위치를 파악할 수 있기 때문에 model이 이미지를 학습할 때 도움이 된다.

Relative Position Bias
- Swin Transformer에서의 다른 점 한 가지는 Positional encoding을 처음에 적용하지 않는다는 점이다. Relative Position Bias(B)를 이용해서 attention 연산 과정 중에 더해주는 형태를 취한다.
- 기존의 Transformer, ViT에서의 position encoding은 absolute coordinate에 대한 기준이었다면, Relative Position Bias는 relative coordinate에 대한 기준으로 weight를 준다.
Reference

1999.09.10 / LIG Nex1 AI Researcher