Abstract
- DNN들이 강력하지만 모델의 크기와 무게가 너무 커서 edge device에는 응용되기 힘들기에, 이를 지식 증류로 압축하고 줄이려는 노력들을 해왔다.
- 본 논문에서는 교사 모델과 학생 모델 사이의 간격이 크면 학생 모델의 성능이 감소한다는 문제점을 제시하고 있다.
- 이를 해결하기 위해서 다중 지식 증류 라는 기법을 소개하고 있고, 이는 교사 모델과 학생 모델 사이에 중간 크기의 네트워크 모델을 추가하여서 간극을 줄여 효율적인 지식증류를 말한다.
Assistant based Knowledge Distillation
- 지식 증류의 핵심은 GT만으로 학습하는 것 뿐만이 아니라 교사 모델이 어떻게 작동하는지 등의 정보까지 관찰하는 것이다.
- 주로 지도학습에서는 를 선생/학생 모델의 logit들이라고 하면, GT label인 는 cross-entropy loss인

이다.
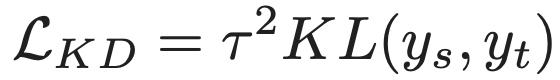
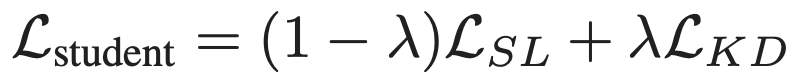
-
교사 모델의 크기가 커지면 성능이 증가하여서 더 좋은 supervisor이 되어서 학생 모델의 성능도 증가한다.
-
교사 모델이 너무 복잡해지면서 학생이 선생모델을 따라하거나 배우기에 충분한 용량이 안된다.
-
교사 모델이 커지면 데이터에 대한 확실도가 증가하면서, soft target의 soft한 정도가 줄어들어서 학생 모델이 배울 정보들이 줄어든다.
-
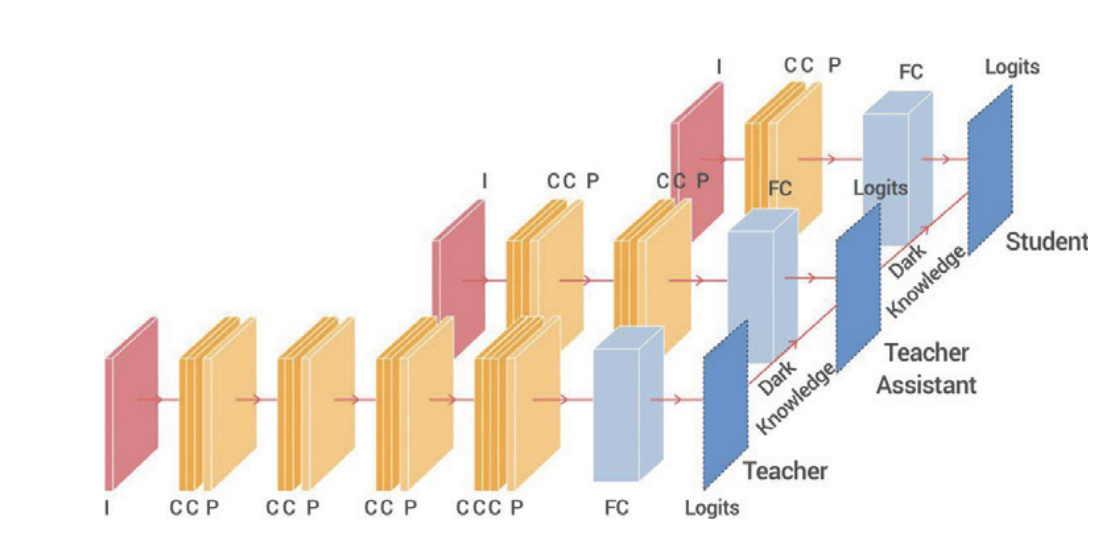
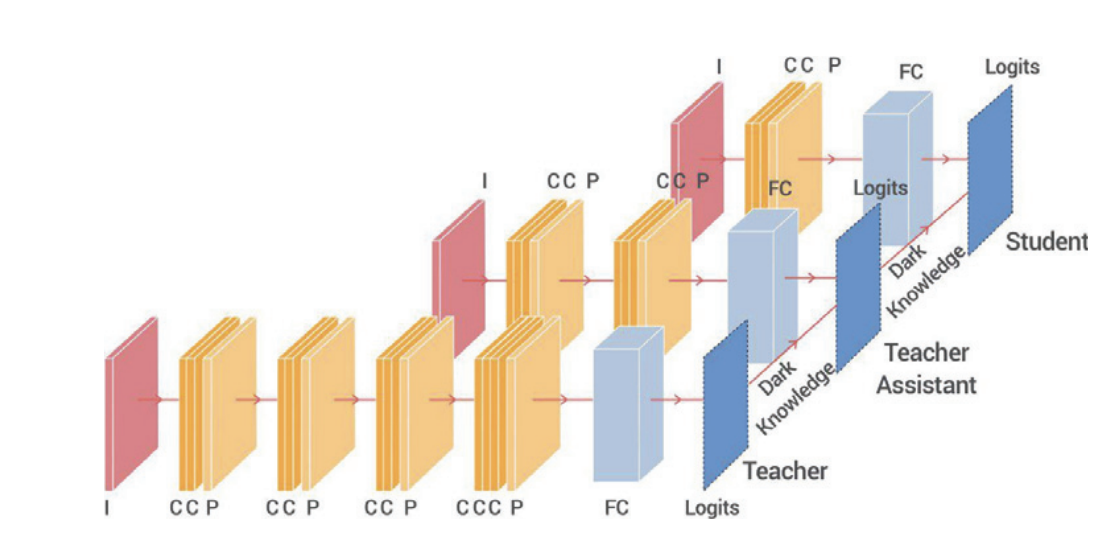
TA 모델은 학생과 교사 모델 크기 사이 어딘가의 크기를 가진다.
-
TA 모델은 교사 모델에게서 지식증류된다.
-
TA 모델은 학생 모델을 지식 증류로 학습시킨다.
-
distillation를 사용하면 loss surface가 평평하게 나타나는 경향이 있다.
-
loss surface가 평평할수록 noise에 강해져서 성능이 좋다.

1999.09.10 / LIG Nex1 AI Researcher