Enhance Image Classification via Inter-Class Image Mixup with Diffusion Model (CVPR 2024)
논문 리뷰
목록 보기
18/21
Abstract
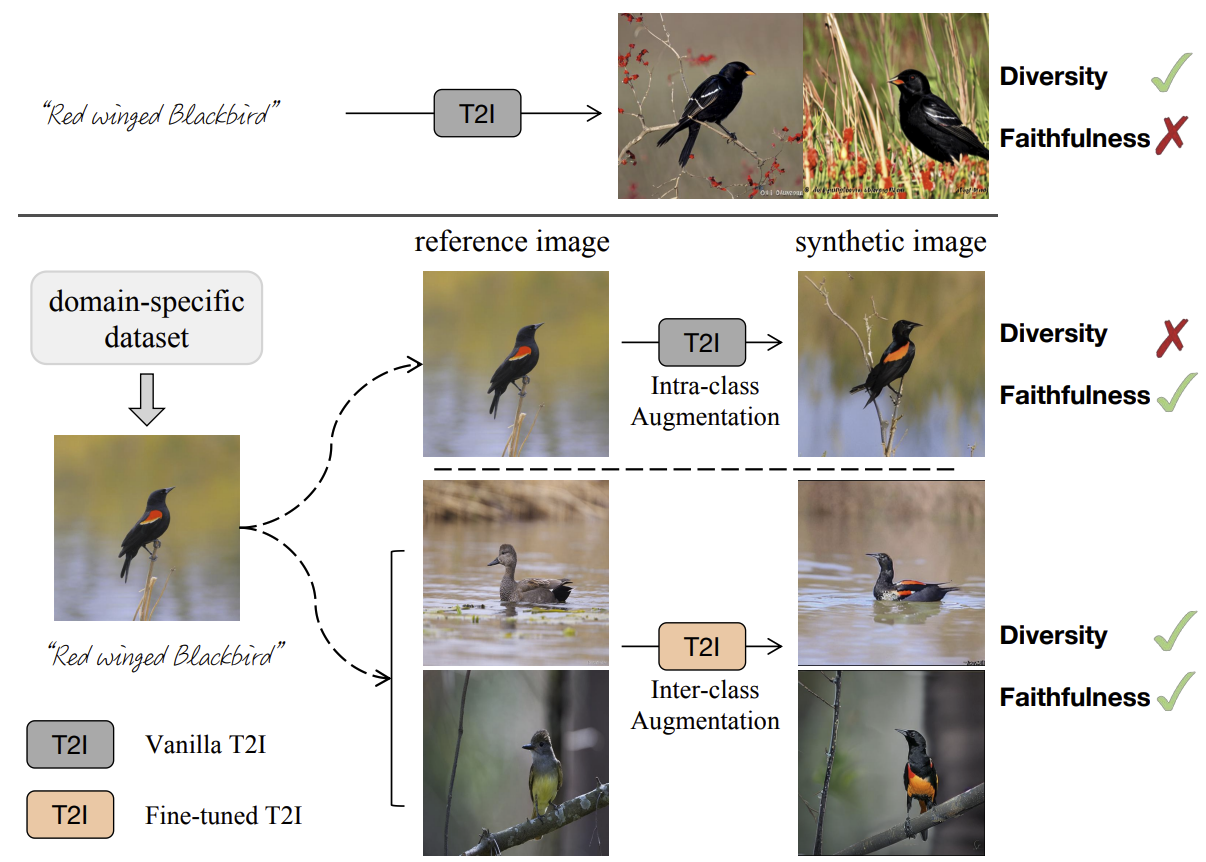
- T2I 모델들은 최근 강력한 성능을 보여왔지만, 이러한 모델들을 classification과 결합했을 때 좋은 성능이 나올까에 대한 의문은 여전히 남아있다.
- 데이터 증강에서의 생성형 방식과 전통적인 방식 둘 다 일정하면서 다양성이 높은 이미지를 만들기에는 부족함이 있다. 여기서 faithful → 전경 관점에서, diverse → 배경 관점에서 라는 뜻.
- 이를 해결하기 위해서 inter-class한 데이터 증강 방식을 제안하는데, 이를 Diff-mix라 명명하며, diversity와 faithfulness 두 방면 모두에서 뛰어난 균형을 보이는 모델이다.
Method
- Preliminary
- T2I personalization
- 제한된 숫자의 concept-oriented 이미지들을 사용하여서 디퓨전 모델을 특정 concept에 맞게 finetuning하는 과정이다
- 이러한 concept들은 주로 identifier이라는 것을 사용하여서 표현된다.
- fine-tuning전략에 따라서 장 단점이 바뀌는데, faithfulness를 포기하면
- Image to Image Translation
- 이미지-이미지 변환은 reference 이미지를 활용하여서 정교하거나 섬세한 부분들을 수정하는데 활용할 수 있다.
- SDEdit에서 아이디어를 가져오며, reference이미지를 target이미지로 변환시킨다.
- Translation과정 중에는 noise를 끝까지 입히지 않고 특정 step T에서 시작한다.
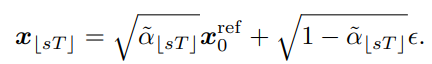
- strength parameter인 s를 사용하여서 diversitiy와 faithfulness 사이에서의 밸런스를 사용자가 선택할 수 있다.

- General Framework
- 2가지 step으로 구성이 되는데, 하나는 faithfulness를 높히기 위한 Stable Diffusion finetuning과 하나는 diversity를 위한 inter-class translation이다.
- Fine-tune diffusion Model
- 바닐라 distillation은 특히나 train shot이 늘어날 때 덜 효과적인 경향을 보인다
- 이를 완화하기 위해 SD를 널리 쓰이는 T2I personalization 전략과 접목하여 사용한다
- 기존에 있던 전문 text prompt들을 fine-tuning 단계에 직접적으로 text에 넣는 것은 모델의 수렴과 faithfulness를 방해한다.
- 이를 해결하기 위해서 text를 넣는 대신 저자들은 와 같은 형태의 identifier를 사용하여 prompt를 “ [metaclass]”의 형태로 모두 통일 시킨다.
- 여기서 는 학습 가능한 identifier이며, i는 [1, N] 사이에서 증가한다.
- metaclass란 bird와 같은 공통되는 큰 카테고리를 뜻한다
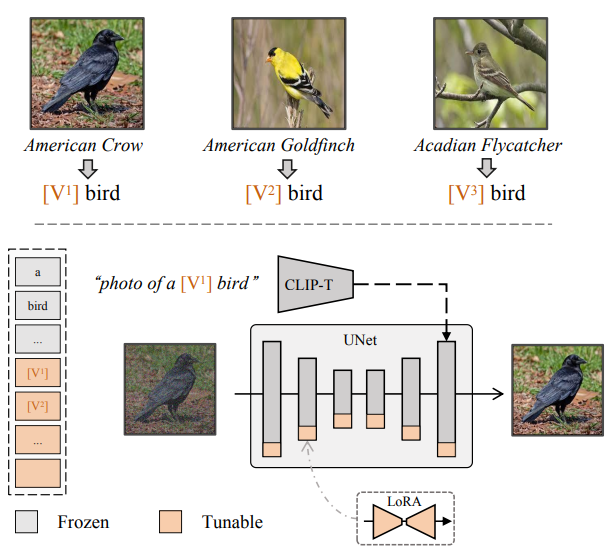
- LoRA라는 파라미터 효율적인 finetuning 방식을 채택한다.
- LoRA는 직접적으로 바로 finetuning 하는 것이 아닌, low-rank 행렬들의 잔여물들을 fine-tuning한다. rank d는 10으로 설정한다.
- Data Synthesis Using Diffusion Model
- 3가지 방법이 존재한다.
- distillation 기반 Diff-Gen
- intra-class 증강 Diff-Aug
- inter-class 증강 Diff-Mix
- Diff-Gen은 full reverse process(T-steps)를 통하여 scratch(random 가우시안 노이즈)로부터 샘플들을 생성한다.
- 반대로, Diff-Aug는 diversity의 일부를 포기하고 reference image를 수정하는 것으로 이미지를 생성한다.
- 자세히는 intra-class train dataset에서 임의로 샘플링을 하고, image translation을 이용하여 이미지를 좋게 수정한다.
- intra-class란, 객체에 대해서 conditioning prompt가 GT기반으로 생성이 되어 있는 데이터를 말한다.
- Diff-Mix는 Diff-Aug와 같은 방식을 사용하지만, reference 이미지가 intra-class dataset에서 sampling되는 것이 아니라 full-training set에서 sampling된다는 차이가 있다.
- 이것은 inter-class interpolation을 하기 위해서다.
- Diff-Mix는 Diff-Aug에 비해서 좋지 않은 결과를 보여주는 경우가 잦아서, 이를 해결하기 위해서 CLIP모델을 필터링의 기준으로 사용하여서 content의 신뢰도를 검증한다.
- 3가지 방법이 존재한다.
- T2I personalization
Experiments
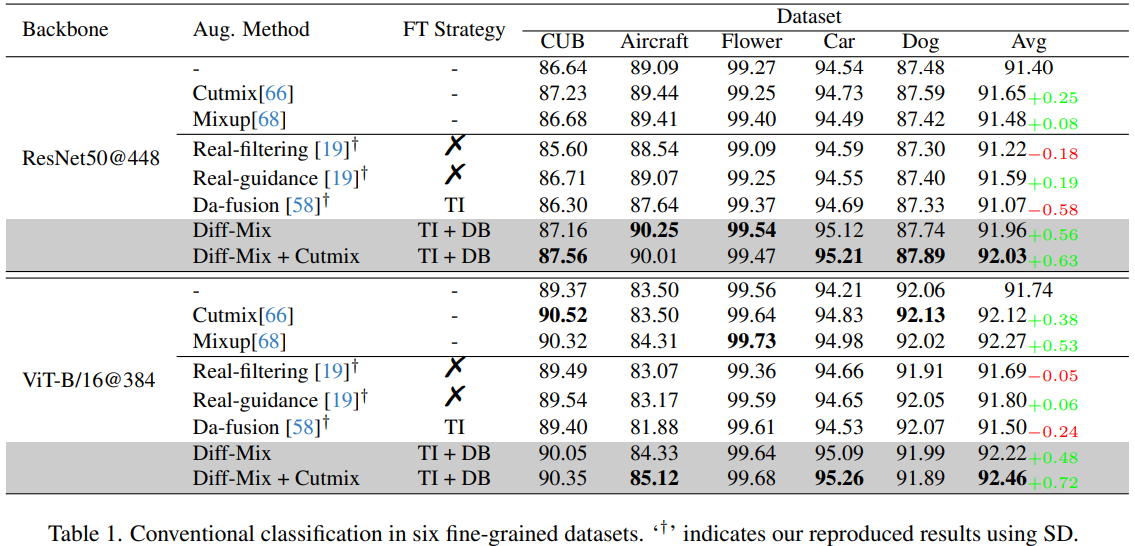
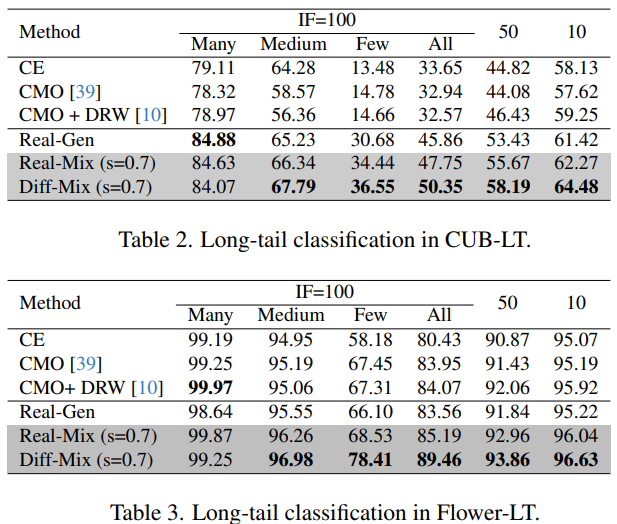
- Imbalance Factor이 클수록 불균형한 데이터셋이다.

1999.09.10 / LIG Nex1 AI Researcher