Abstract & Introduction
- GPT-3 (1750억 개의 파라미터)와 같은 거대한 모델의 전체 파인튜닝은 높은 계산 및 메모리 비용으로 비현실적임.
- 사전 학습된 모델의 가중치를 고정하고, 트랜스포머 레이어에 학습 가능한 저랭크 행렬을 삽입함.
- 이를 통해 학습해야 할 파라미터 수를 최대 10,000배 줄이고, GPU 메모리 요구량 3배 감소시킴.
- 성능은 기존의 baseline에 비해 동등하거나 그 이상의 성능을 보이며, 기존의 어댑터 방식과는 다르게 추론 시간에 지연이 발생하지 않음.
Problem Statement
- full fine-tuning의 단점은 매 task을 위해서 다른 파라미터를 매번 모두 학습해야 한다는 점이다. 특히 GPT-3와 같이 parameter가 굉장히 많은 모델을 학습하는 것은 어렵다.
- 저자들은 작업별 파라미터 증가분 ΔΦ를 훨씬 작은 파라미터 집합 Θ로 표현하는 파라미터 효율적인 접근법을 제안합니다.
- ΔΦ를 저랭크 표현으로 인코딩하여 계산 및 메모리 효율성을 높입니다.
- 이 방법으로 GPT-3 1750억 모델의 경우 학습해야 할 파라미터 수를 원래 모델의 0.01%까지 줄일 수 있습니다.
Aren’t Existing Solutions Good Enough?
- 기존의 어댑터 방식은 아주 적은 파라미터와 계산량을 사용하여 추론 시간을 늘리지 않기 위해 설계되었다.
- 하지만, 큰 neural 네트워크는 하드웨어에 의존하며, 어댑터 레이어들은 순차적으로 계산되어야 하기에 온라인 추론 환경과 같이 배치 사이즈가 1과 같이 작은 경우에는 LoRA와 의미있는 레이턴시 차이를 보인다.

Methods
- Low-Rank-Parameterized Update Matrices
- 신경망은 많은 full-rank 행렬곱 연산을 포함한다.
- LLM들은 낮은 intrinsic dimension을 가지기 때문에, 특정 task에 이를 적용할 때에는 더 작은 subspace로의 projection만으로도 충분히 효율적으로 학습이 가능하다.
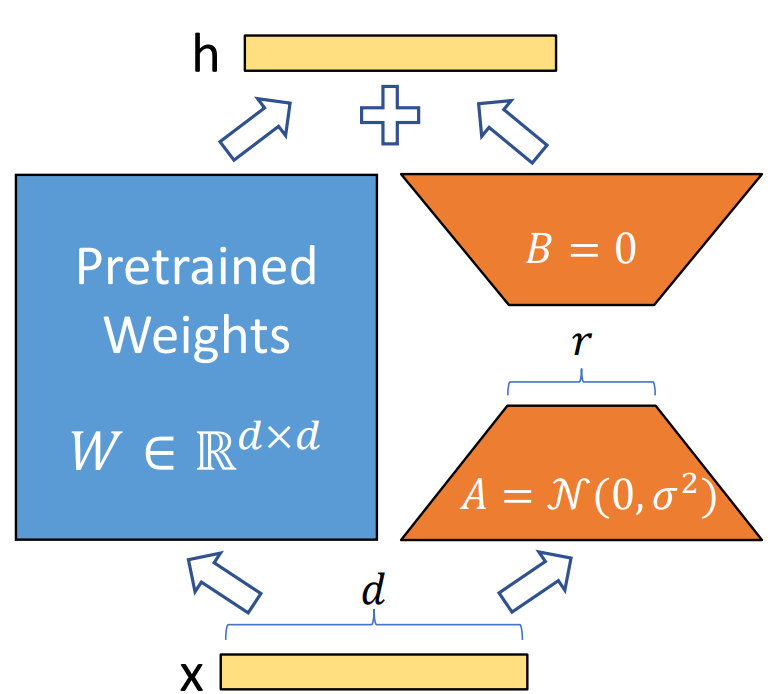
- 이에서 착안하여, 일때, 와 같이 업데이트를 low-rank decomposition으로 제한하여 표현한다. [단, ]
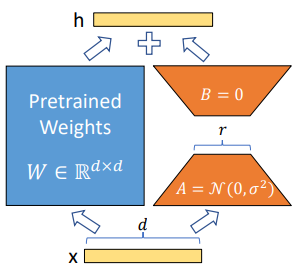
- A는 임의의 가우시안 노이즈 초기화를, B는 zero 초기화를 적용한다. 즉, 학습 초기 단계에서 는 0으로 시작한다.
- 가 성립하기 때문에, 추론 시에는 단순히 식을 사용하는 것으로 W를 구할 수 있으며, 평소의 추론과 동일하게 진행될 수 있다.
- 이러한 이유로 추론 시간에 latency를 추가하지 않는다는 뜻이다.
- task를 변경할 때에도, 에서 를 뺄셈하여 를 손쉽게 복원한 후, 를 다시 더해주기만 하면 되기 때문에, 적은 메모리로도 빠르게 적용할 수 있다.
- Applying LoRA to Transformer
- Transformer의 구조에서 self-attention module에 총 4개() , MLP module에 2개의 weight 행렬이 존재함.
- 각 (or )는 attention head로 slicing 되지만, 저자들은 이를 의 차원을 갖는 single matrix로 간주한다.
- 단순성과 파라미터 효율성을 위해서, 본 연구에서는 attention weight만을 바꾸는 것을 다룬다. (MLP 모듈은 freeze 상태)
- Practical Benefits and Limitations
- 핵심 이점은 메모리 사용량과 저장공간의 감소이다.
- Optimizer state를 저장하지 않아도 되기에, Adam으로 학습된 large Transformer에 대해서 VRAM 사용량을 최대 까지 줄인다.
- checkpoint size를 약 10,000배까지 줄인다.
- GPT-3 175B 모델에 대해서 전체 파인튜닝에 학습 시간에 비해 25%의 속도 향상을 관찰하였다.
- 여러 task 간의 전환 시에 LoRA의 가중치만 교체하면 되어서 비용 효율적이다.
- 추론 지연을 없애기 위해 가중치를 병합하면, 서로 다른 A와 B를 가진 입력을 한 번에 배치 처리하기 어렵다.
- 하지만, latency가 중요하지 않은 환경에서는 동적으로 병합을 하지 않는 선택을 할 수 있는 선택지가 있다.
Experiments
- 실험은 RoBERTa, Ce-BERTa, GPT-2, GPT-3 175B에 대해서 진행하였다.
- FT: 모델은 사전학습 weight와 bias로 초기화되며, 모든 weight가 gradient update를 거친다. GPT-2는 마지막 두 레이어만 학습하며, 나머지는 freeze하는 방식. ()
- Bias-Only or BitFit: Bias 벡터만 학습되며, 나머지는 전부 freeze하는 방식.
- Prefix-embedding tuning(PreEmbed): input token에 special token을 삽입하며, 이 토큰은 모델에 일반적으로 없는 학습 가능한 단어 임베딩을 포함한다. 이를 앞에 추가하여(prefixing) 성능에 어떤 임팩트를 주는지에 집중하는 방식.
- Adapter Tuning: self-attention module/MLP module과 residual connection 사이에 ****adapter layer를 추가하여서 학습하는 방식. 기존 방식은 라 불리며, MLP 뒤와 LayerNorm 뒤에만 layer를 추가하는 방식은 로 불림. 효율성을 위해 몇 개의 레이어를 버리는 방식은 라고 불림.
- LoRA: 학습 가능한 rank decomposition 행렬들을 weight 행렬들과 평행하게 추가하는 방식.
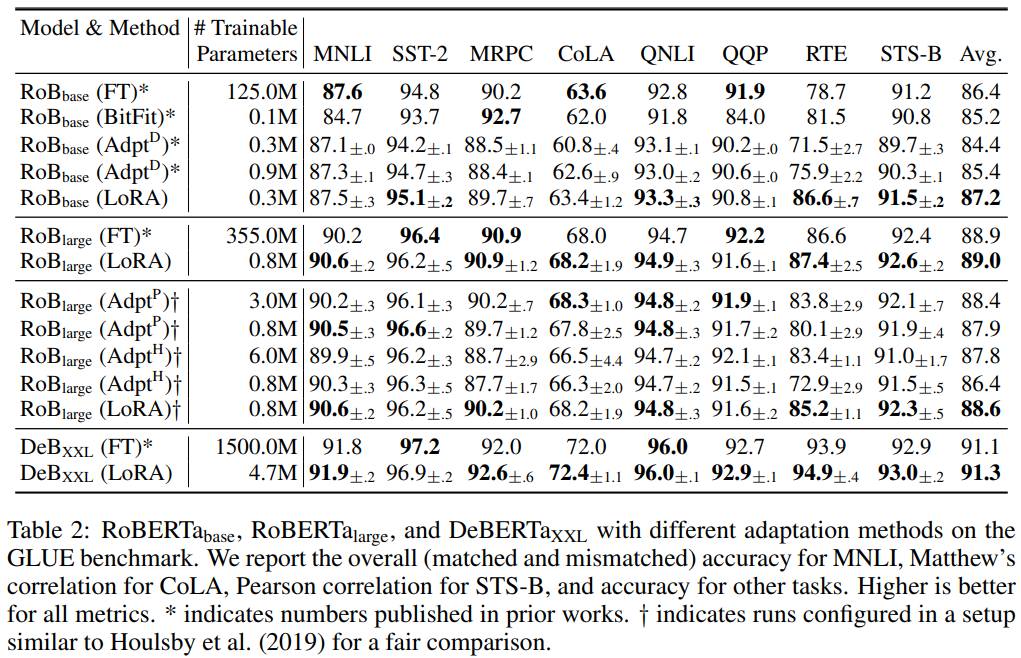
- RoBERTa Base & Large 실험
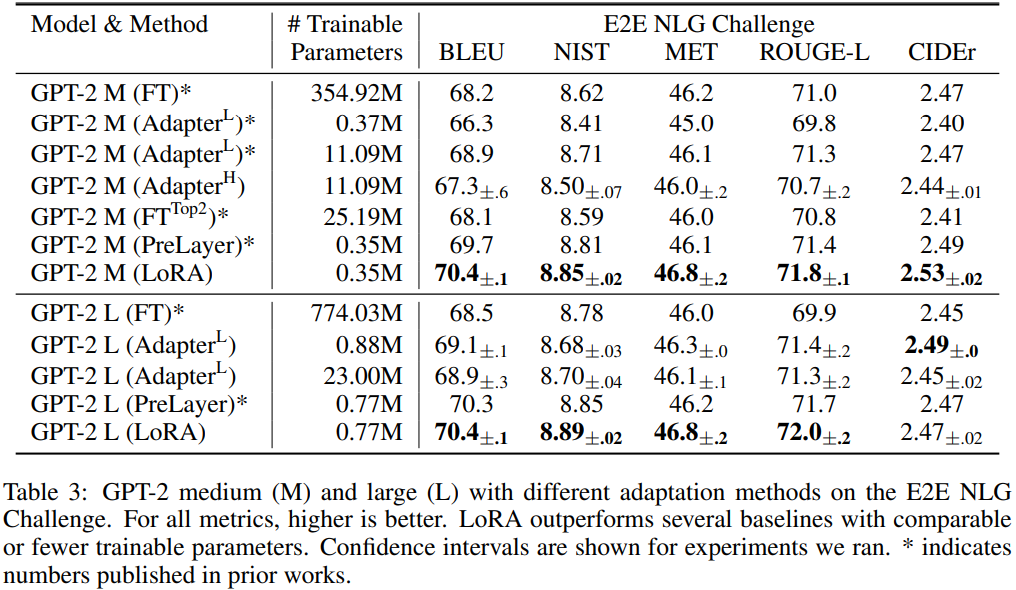
- GPT-2 Medium & Large 실험
- GPT-3 175B 실험
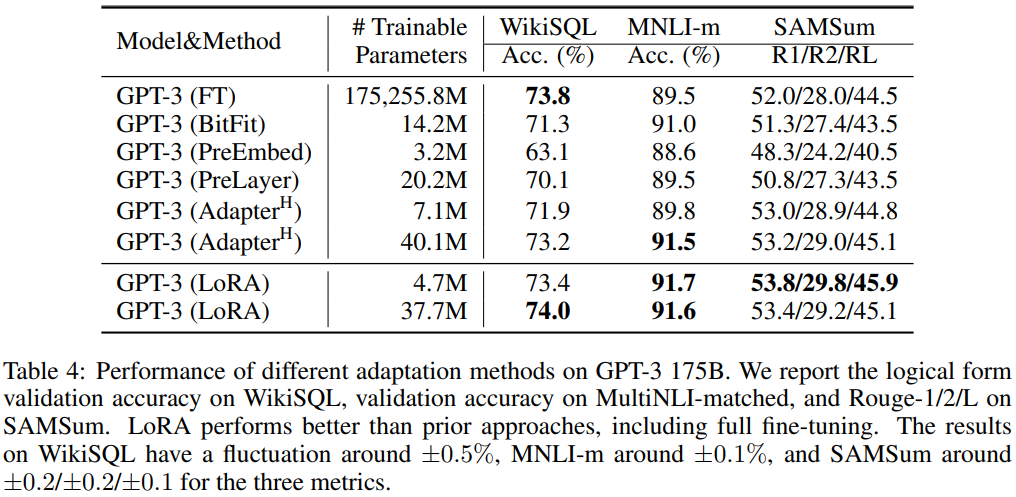
Ablation Study
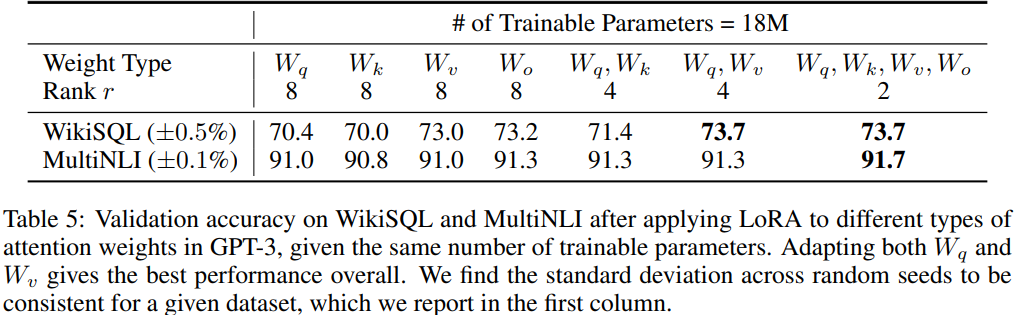
- 트랜스포머의 어떤 부분에 LoRA를 적용하는 것이 좋을까?
- 에 적용할 때 성능이 꽤 괜찮았고, 전부 다 줄때 가장 좋았다.
- 효율을 따져볼 때에는 에만 적용하는 것이 가장 효율적이며 성능이 좋다.
- 최적의 r 값은 무엇일까?
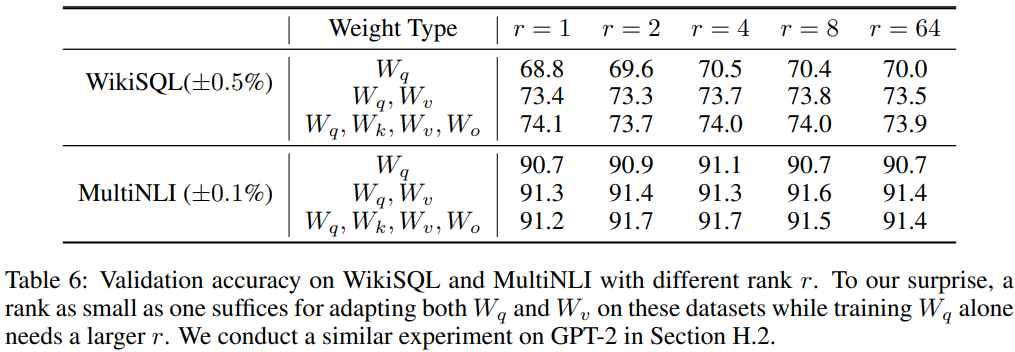
- $W_q$ 에만 적용할 때에는 r=1로는 부족했지만, 이외의 경우에는 r=1만으로도 충분했다.
- r의 값을 키우는 것이 의미있는 subspace를 항상 배우는 것은 아니었다.Conclusion and Future Works
- 거대 언어 모델을 fine-tuning하는 것은 하드웨어(storage/swiching) 면에서 매우 비싸고 어려운 일이다.
- 본 논문에서는 좋은 성능을 유지하면서도, latency와 입력 텍스트 길이에 영향을 주지 않는 효율적인 adaptation 전략인 LoRA를 소개한다.
- 본 논문에서는 언어 모델에 집중하지만, 제시된 방법은 dense layer를 가진 신경망이라면 일반적으로 적용될 수 있다고 한다.
- 다른 efficient adaptation 방법들과 함께 사용될 수 있다고 한다.
Paper : https://arxiv.org/pdf/2106.09685
Github : https://github.com/microsoft/LoRA

1999.09.10 / LIG Nex1 AI Researcher