Medical Diffusion Paper Research
- Synthetic Augmentation with Large-Scale Unconditional Pre-training
- 이러한 방식들의 효과는 생성 모델의 성능에 엄청나게 의존을 하는데, 충분한 라벨링된 데이터 없이는 생성 모델의 성능을 보장할 수 없다.
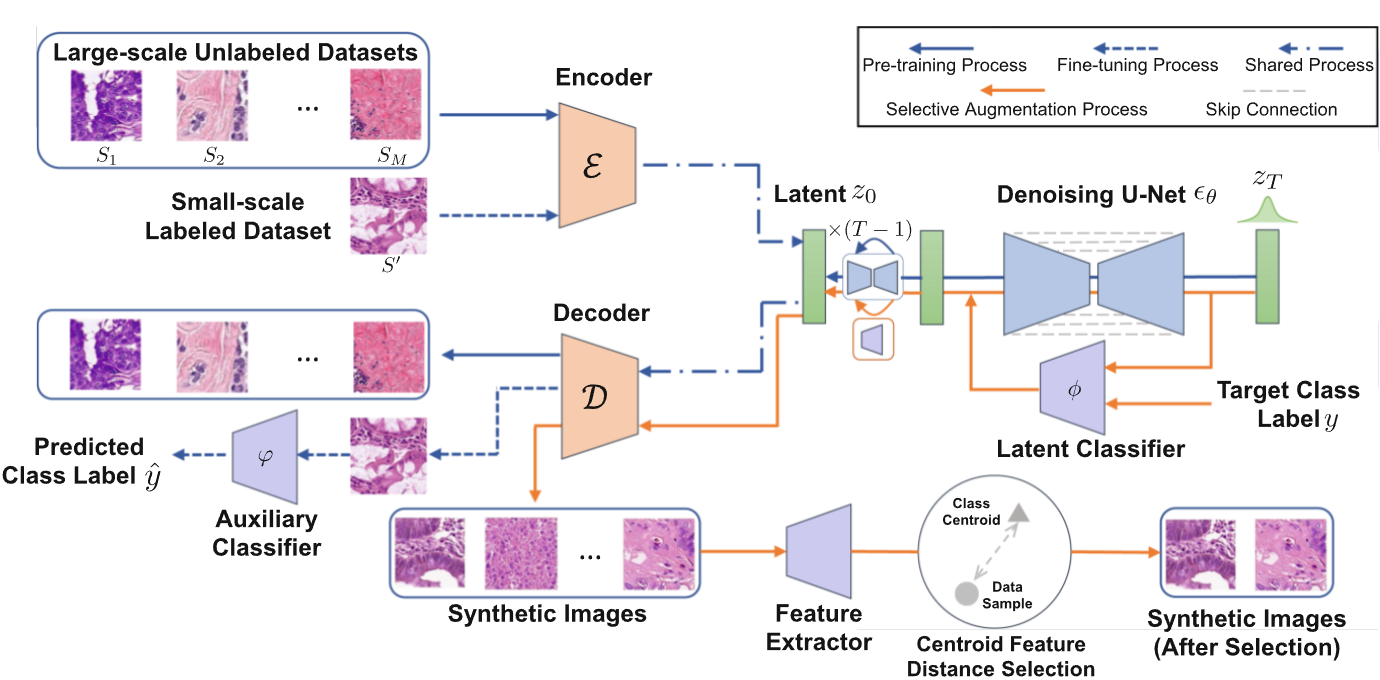
- 라벨링된 데이터에 너무 의존하는 경향을 최대한 줄이기 위해서 본 논문에서는 unlabeled large-scale data로 pre-train한 후, small-scale의 labeled data로 fine-tuning 될 수 있는 HistoDiffusion이라는 synthetic한 augmentation 방식을 제시하고 있다.
- HistoDiffusion은 LDM 기반이며 다양한 unlabeled data를 학습하여 conditional input없이 realistic한 이미지를 생성하도록 설계되어있다.
- 그 후에는 처음 보는 labeled-data를 이용하여 fine-tuning해서 특정 카테고리에 대한 이미지를 생성할 수 있도록 한다.
- 또한, 생성된 데이터를 본 모델의 학습에 넣을 때 신뢰도가 높은 데이터만을 선택하여 집어넣는 selective augmentation process 매커니즘을 추가하였다고 한다.
- 3개의 조직병리학 data로 pretrain하고, CRC라는 조직병리학 data에 대해서 fine-tuning한 모델로 augmentation을 진행했을 때, 6.4%의 classification 성능 향상을 이뤄냈다고 한다.
- DiffMix: Diffusion Model-Based Data Synthesis for Nuclei Segmentation and Classification in Imbalanced Pathology Image Datasets
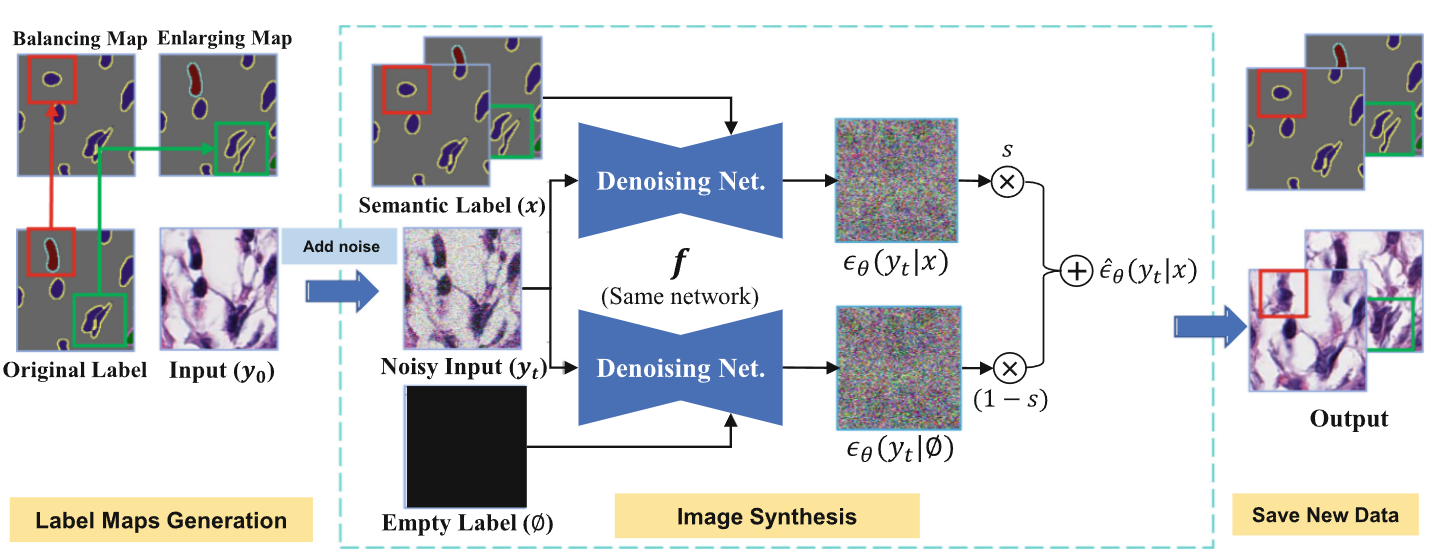
- Semantic Diffusion Model(SDM): noisy한 input 와 semantic label인 를 각각 encoder, decoder에 독립적으로 넣어준다.
- semantic label x를 넣어주면 condition이 되고, empty label을 넣으면 uncondition이 된다.
- Balancing Map: 가장 적은 데이터 수를 가진 클래스의 핵을 cut/paste/smooth 한다.
- Enlarging Map: 핵인 부분들을 랜덤하게 perturb 시켜서 데이터의 다양성을 증가시킨다.
- 핵들의 위치를 랜덤하게 옮겨서 SDM이 예측 불가능한 다양한 semantic map을 넣어주려고 노력했다.

1999.09.10 / LIG Nex1 AI Researcher