Batch vs. Layer Normalization - 언제, 그리고 왜 쓰는 건가요?
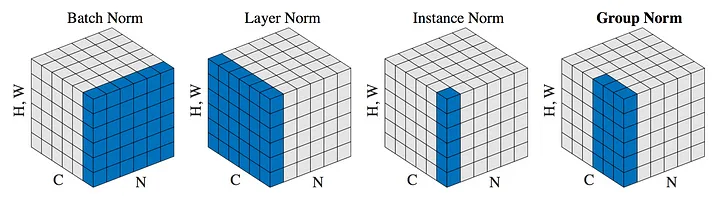
오늘은 배치 정규화(batch normalization)과 층 정규화(layer normalization) 기법에 대해 알아보고 비교하고자 한다.CNN부터 transformer까지, 항상 있는 듯 없는 듯 껴 있는 연산들이고, 코드 상에서도 딱 한줄 들어가는 존재감 없는 녀석들이다. 둘이 매번 헷갈린다. 뭔가 공변량 변화를 막아주기 위해 분포를 정규화해주는건 알겠는데...
구체적으로 어떻게 동작하는거지?
그래서 BN은 언제 쓰는거고, LN은 언제쓰는건데?
먼저 BN과 LN의 등장 배경에 있는 문제: 내부 공변량 변화(Internal covariate shift)에 대해 먼저 알아보자.
Covariate Shift & Internal Covariate Shift
공변량 변화(Covariate shift)는 학습 데이터와 테스트 데이터 사이의 분포 차이가 발생하는 현상을 의미한다. 가령 강아지로만 구성된 데이터셋으로 학습시킨 모델에게 고양이 데이터를 준다면, 강아지와 고양이 두 데이터의 (픽셀 값들의) 분포가 다르기 때문에 제대로 추론을 수행하지 못할 것이다.
이러한 covariate shift가 신경망 내부에서 일어나는 것을 내부 공변량 변화(internal covariate shift)라고 부른다. 인공 신경망은 매번 데이터가 입력될 때마다 각 층에서의 활성화 값을 출력한다. 이전 층의 활성화 값은 다음 층으로 전달된다. 문제는, 각 층을 계속할 때마다 각 층으로 입력되는 활성화 값들이 들쑥날쑥 바뀐다는 것이다. 이 문제는 층의 깊이가 깊어질 수록 더 심해진다.
왜 그럴까? 인공 신경망에는 매 step마다 각 층의 파라미터들이 업데이트되는데, 현재 step과 다음 step의 파라미터 값들이 다르니 이 층들을 지나온 활성화 값들도 다른 값을 갖게 된다. 층의 깊이가 깊은 경우, 각 층들의 파라미터 값이 살짝만 업데이트 되어도 이러한 변화가 누적되며 뒤쪽 층에게는 상당한 변화로 다가올 것이다.
이러한 내부 공변량 변화로 인해 신경망은 계속해서 변화하는 데이터에 맞춰 학습해야 하니 학습 과정이 더 많은 step을 요구하고, 불안정한 학습을 촉발한다. 또한 gradient가 너무 작거나 큰 값으로 계속해서 누적되는 경우 gradient vanishing/exploding 문제로 이어지기도 한다.
Batch Normalization
등장한 연도 자체는 BN이 LN보다 먼저 나왔다(Ioffe et al. ICML'15). BN은 내부 공변량 변화(Internal covariate shift)라는 문제를 해결하고자 도입되었다.
배치 정규화는 미니배치 내의 활성화값들의 평균과 표준편차를 구해 standard scaling을 적용하여 활성화 값들의 분포를 표준정규분포로 만들어주어 내부 공변량 변화를 없애고 학습을 안정적이고 빨리 수렴하도록 도와준다.
연산은 다음과 같다:
-
현재 미니배치 안에 존재하는 활성화 값들의 평균()과 표준편차()를 구한다.
이 때 은 배치 사이즈, 는 미니배치 내의 번째 샘플의 활성화 값이다.
-
각 활성화 값들을 평균으로 빼고 표준편차로 나누어 정규화한다 (Z-score/standard scaling).
이 때 은 분모를 0으로 만들지 않기 위한 작은 상수다.
-
학습 가능한 scale and shift 파라미터(각각 )를 곱하고 더해준다. 이렇게 하는 이유는, 활성화 값의 분포를 모두 일정한 정규분포로 만들어 버리면 내부 공변량 변화는 없어진다 해도 오히려 모델의 표현력이 떨어지는데(모델이 다양한 분포를 학습하지 못함), 학습 가능한 파라미터로 분포를 적당히 조절해주어 모델의 표현력을 떨어뜨리지 않으면서 정규화를 수행하기 위함이다.
Batch Normalization: Training vs. Inference
지금까지는 미니배치 단위로 학습할 때를 가정하고 이야기했지만, 만약 싱글 데이터포인트 단위로 입력되는 추론 단계에서는 BN이 어떻게 동작할까?
간단히, BN은 학습 도중 입력된 모든 미니배치에 대해 와 의 이동평균을 저장해두고, 추론 시에 이렇게 저장된 와 를 가져와 정규화를 수행한다.
BN의 장단점
BN의 장단점을 요약하면 다음과 같다:
BN의 장점
1. 내부 공변량 변화를 막아 학습 시 수렴 속도가 빠르고 안정적인 학습이 가능하다.
2. 위와 같은 이유로 깊은 층을 가진 신경망도 효과적으로 학습할 수 있다.
3. 초기 가중치 설정값의 영향을 줄여준다 (뭘로 초기화하든 결국 뒤에서 정규화해주기 때문에).
4. Overfitting을 방지하는 역할이 있다. (BN의 정규화 과정은 일종의 regularization 역할을 수행한다)
BN의 단점
1. 배치 사이즈에 의존적이다. 작은 배치 사이즈에서는 통계값이 불안정해 오히려 학습을 방해할 수 있다.
2. 순차적 데이터(sequence)에 대해 부적합하다. (다음 section에서 설명)
3. 연산 overhead가 늘어난다. 어쨌든 새로운 연산 과정과 파라미터가 추가된 것이고, 학습중 매번 이동평균도 구해줘야 한다.
Batch Normalization for NLP
일반적으로 BN은 자연어 처리(NLP) 분야에서는 잘 쓰이지 못한다고 한다. 그 이유는 이미지 데이터와 시퀀스 데이터의 특성 차이 때문인데, 한 미니배치에 들어있는 모든 이미지는 동일한 shape(HxW)를 가지지만, 시퀀스 데이터는 그렇지 않고 각각의 시퀀스가 (padding을 제외하면) 제각각의 시퀀스 길이를 가지기 때문에 시퀀스 데이터에 적용하기엔 부적합하다고 볼 수 있다.
반면 CNN과 같은 모델이 이미지 데이터를 다루는 경우에는 적합하다.
Layer Normalization
층 정규화(LN) 역시 내부 공변량 변화에 대처하기 위한 정규화 기법으로, 시퀀스 데이터 학습에 취약한 BN의 단점을 개선하고자 등장하였다. 먼저 BN과 LN의 연산을 아래 그림과 함께 비교해보자.
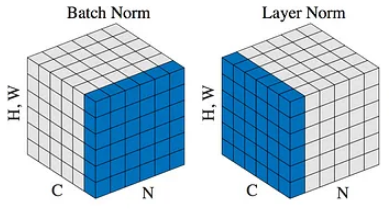
(그림의 H,W는 이미지라면 height x width가 되겠지만, 시퀀스라면 시퀀스 길이로 봐도 무방하다)
- BN은 앞서 설명했듯 미니배치 내의 모든 데이터에 대한 활성화값들의 평균/표준편차를 구하여 정규화를 수행한다.
- LN은 반면 배치와는 관계 없이, 각 데이터포인트들에 대한 활성화 값들의 평균/표준편차를 구하여 정규화를 수행한다.
아래 그림이 직관적으로 더 이해하기 쉬울 듯 하다.
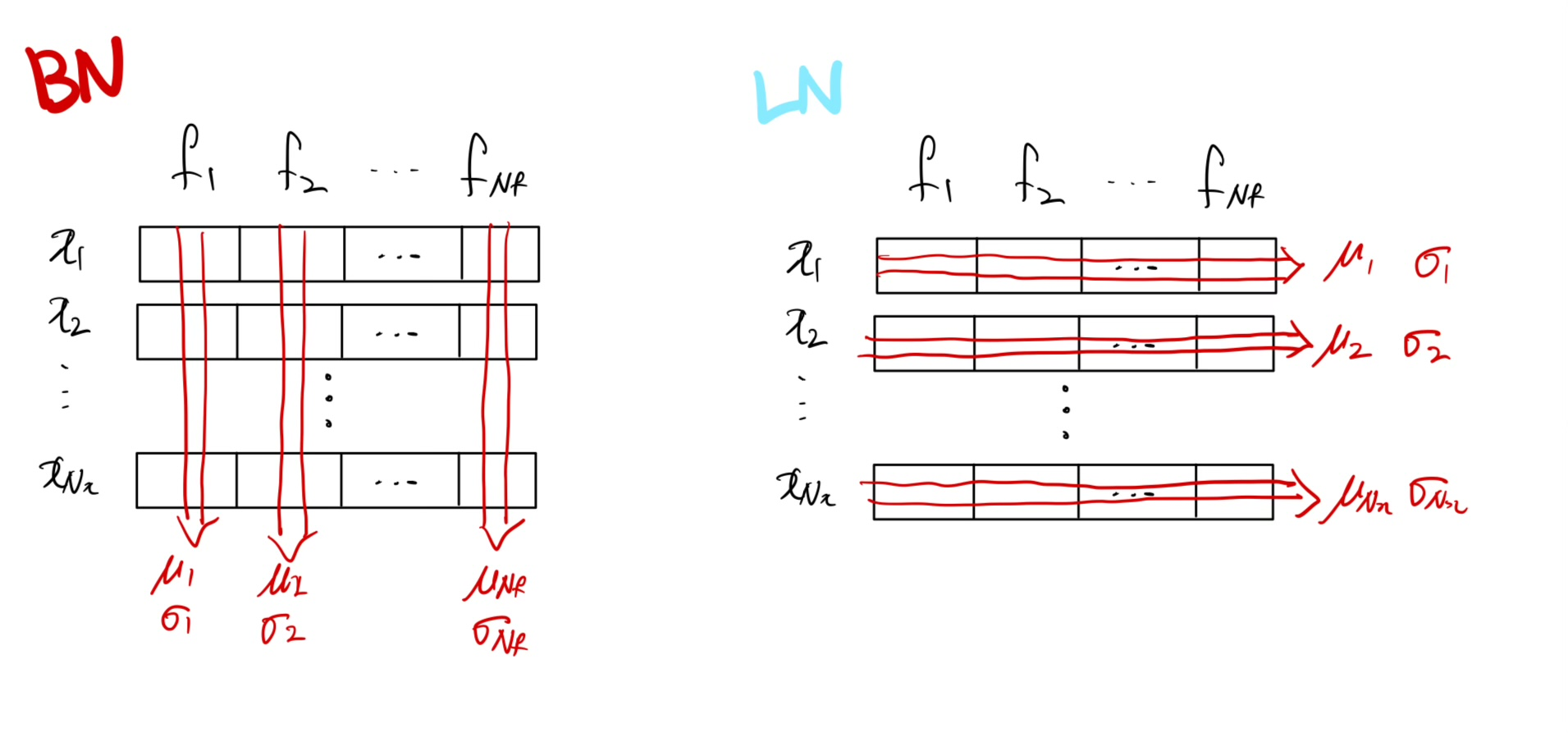
그림에서 는 미니배치 내의 번째 데이터, 는 각 데이터의 번째 feature를 나타낸다.
LN의 연산 과정을 수식으로 나타내면 다음과 같다:
-
평균()과 표준편차() 계산
BN과 비교했을 때 배치() 단위 활성화 평균/표준편차를 구하는 식에서 한 데이터 포인트 내에서의 활성화값(feature; )들을 평균/표준편차 내는 식으로 바뀌었다 (는 임의의 임베딩 차원이라고 하자).
-
정규화
-
Scale and shift (BN과 동일하게 학습 가능한 파라미터 도입)
조금 더 구체적인 예시로, "I am a student"라는 문장이 입력되었고, 이 문장이 임베딩 레이어(=임베딩 차원)를 거쳐 아래와 같은 모양이 되었다고 하자. 이 때 LN 연산은 아래 그림처럼 수행된다.

즉, 문장 내의 각 토큰에 대해 임베딩 차원(feature dimension)에 대해 평균/표준편차를 구해서 정규화를 수행한다.
Why Layer Normalization?
LN은 BN처럼 학습 시의 불안정성과 overfitting을 방지해주면서 배치에 대한 의존성을 줄여 자연어와 같은 시퀀스 데이터 학습을 더 효과적으로 만들어주었다.
LN의 장단점을 정리하면 다음과 같다:
LN의 장점
1. BN의 장점과 같다 (안정적이고 빠른 수렴, overfit 방지).
2. 배치 사이즈에 대한 의존성이 없어 시퀀스 데이터에 적용할 수 있다.
3. BN과 다르게 학습/추론 시 동작이 같아 평균/표준편차에 대한 이동평균을 매번 계산해서 저장할 필요가 없다.
LN의 단점
1. BN의 단점과 같이 추가적인 연산량이 도입된다(정규화, scale and shift).
2. 각 데이터 포인트에 대해 독립적으로 연산하기 때문에 대규모 배치에서 연산 overhead가 커진다.
다음 포스트에서는 BN과 LN을 제외한 다양한 정규화 기법들(Instance norm, Group norm, RMS norm, Shuffling BN, etc.)을 알아보겠습니다.
