
BERT (Bidirectional Encoder Representations from Transformers)
구글에서 개발한 NLP(자연어 처리) 사전 훈련 언어 모델 이며 총 3.3억의 단어의 코퍼스를 정제하고 , 임베딩하여 학습시킨 모델
BERT 모델
BERT 모델은 Transformer를 기반으로 하며 , 그림은 논문에 있는 모델 아키텍처를 참고하였다. BERT 는 이 중에서도 왼쪽, 인코더만 사용하는 모델이다.

출처 - BERT 논문
BERT 는 BERT - base (L=12, H=768, A=12), Bert- large(L=24,H=1024,A=16) 이 두가지 버전이 존재하며 L(Transformer의 블록 숫자) , H(hidden size), A(Transformer의 Attention block 숫자) 를 의미한다. 각각 파라미터 값이 크다는 것은 표현하는 은닉층이 크며, Attention개수를 많이 사용하였다는 것이다. BERT - base 는 1.1억개의 학습 파라미터, BERT - large 는 3.3억개의 학습파라미터를 사용하였다.
BERT의 내부 동작 과정
1. Input
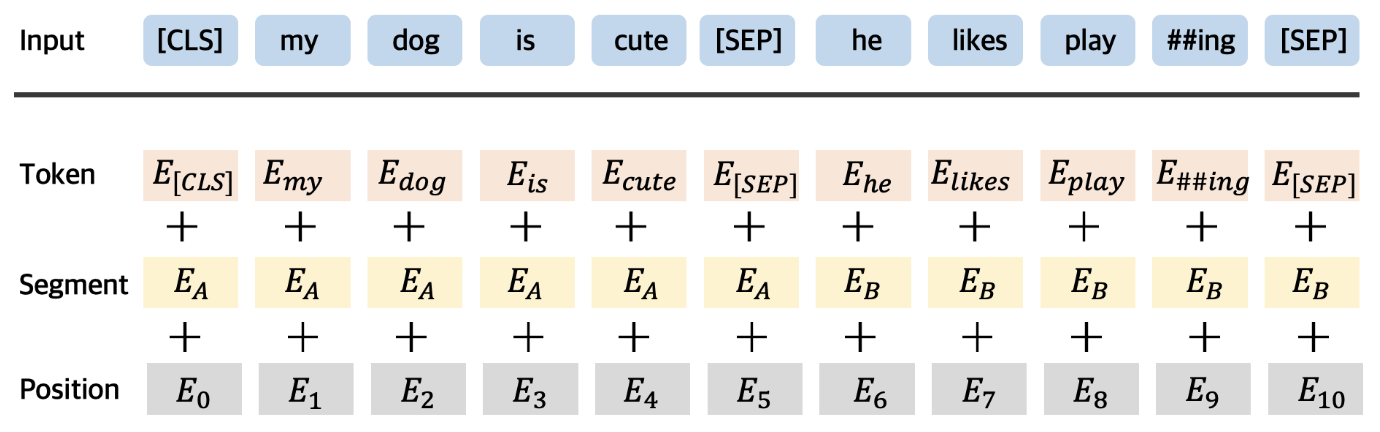
BERT Input : Token Embedding + Segement Embedding + Position Embedding
BERT 는 세 가지 임베딩을 합치고 Layer 정규화와 Dropout 을 적용하여 입력으로 사용한다
-
Token Emdbedding
: Word Piece 임베딩 방식을 사용하여 각 문자 단위로 임베딩을 족 , 자주 등장하고 길이가 긴 sub - word 를 하나의 단위로 만듬 , 자주 등장하지 않는 단어는 다시 sub- word 로 만든다.
-
Segement Embedding
: Senetence Embedding, 토큰 시킨 단어들을 다시 하나의 문장으로 만드는 작업, BERT 에서는 두개의 문장을 구분자로 넣어 구분하고 그 두 문장을 하나의 Segement 로 지정하여 입력한다. BERT 는 한 Segment를 512 sub-word 길이로 제한하며, 한국어는 보통 2- sub-word 가 한 문장을 이룬다.
-
Position Embedding
: BERT 는 Transformer 모델을 기반으로 만들어졌으며 이 중, 인코더만 사용한다. Transformer 모델에서는 Positional encoding 을 사용하고 BERT 는 이를 따서 Position encoding 을 사용한다. 이는 Token 순서대로 인코딩을 하는 것이다.
BERT 는 위 3가지의 입력 임베딩(Token, Segement, Positon) 을 취합하여 하나의 임베딩 값으로 만든 후 Layer Nomalizationi 과 Dropout을 적용하여 입력으로 사용
2. BERT 의 pre - training
BERT 는 기존의 방식들과 달리 두 가지 방향에서 학습을 진행하였으며, 두 가지 비지도 학습을 통해 훈련시켰다.
-
MLM (Masked LM)
MLM 은 입력으로 사용하는 문장의 토큰 중 15%의 확률로 선택된 토큰을 MASK 토큰으로 변환시키고, 언어 모델을 통해 변환되기 전 MASK 토큰을 예측하는 언어 모델
BERT 에서는 다음 단어가 무엇이 오는지 예측하는 학습이 아니라 ,
문장 내에서 무작위로 입력토큰의 일정 비율을 마스킹하고, 그 다음 마스킹된 토큰들을 예측한다. 마스크 토큰에 해당하는 마지막 hidden vector는 표준 LM 에서와 같이 어휘를 통해 출력 소프트맥스로 주어지고 단어를 예측하게 된다.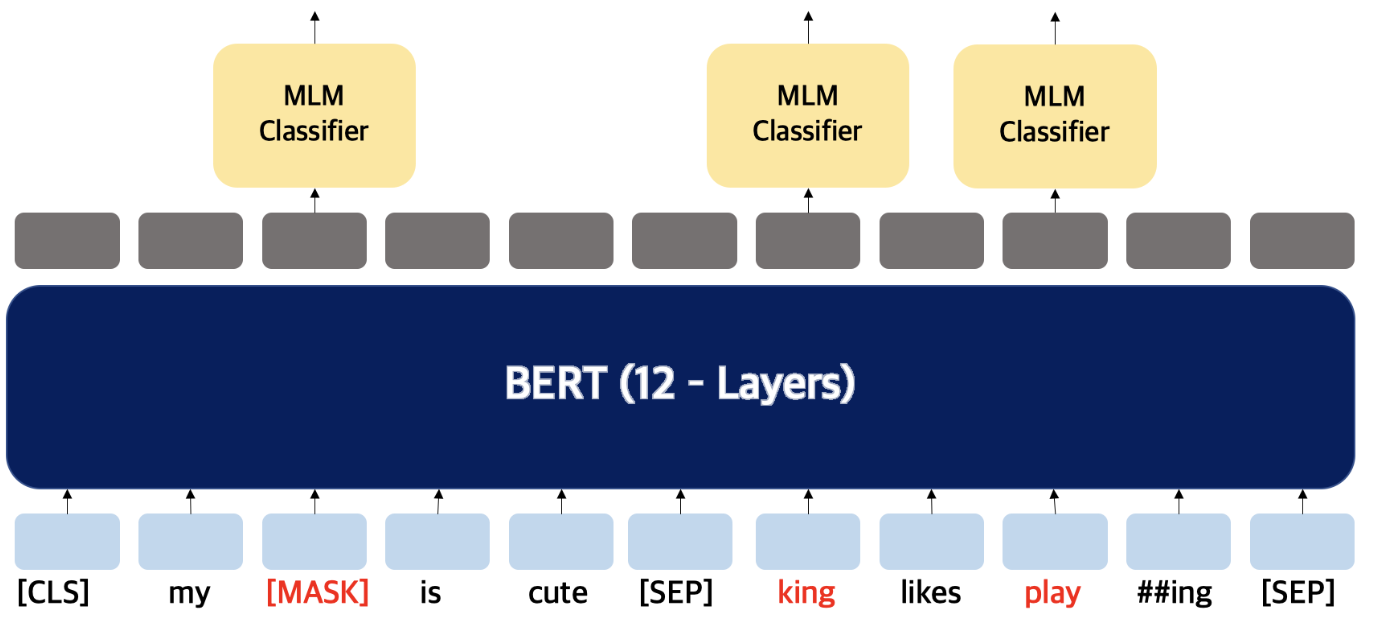
BERT 는 WorldPiece 토큰의 15% 를 무작위로 마스킹하고, 문장을 복구하는 것이 목표가 아닌 해당 단어 예측을 목표로 한다.따라서 양방향 학습은 가능해지지만, fine - tuning 중에 [MASK] 토큰이 나타나지 않기 때문에 (빈칸 단어 예측은 그냥 빈칸 단어로 주어지기 때문이다) , 사전 훈련과 fine- tuning 사이에 불일치를 만들어내는 단점이 존재한다.
훈련 데이터를 생성할때 무작위로 토큰의 15%를 선택한다
만약 i 번째 토큰이 선택된다면 , 80% 는 [MASK] 토큰으로 교체하거나, 10% 다른 토큰으로 교체하거나, 10% 는 변경되지 않은 i 번째 토큰을 사용한다. ( 미세 조정 시 올바른 예측을 돕도록 마스크에 노이즈를 섞음)
→ 모델은 변경이 된 단어에 대해 적합한지를 판단해 예측을 하게 된다.
-
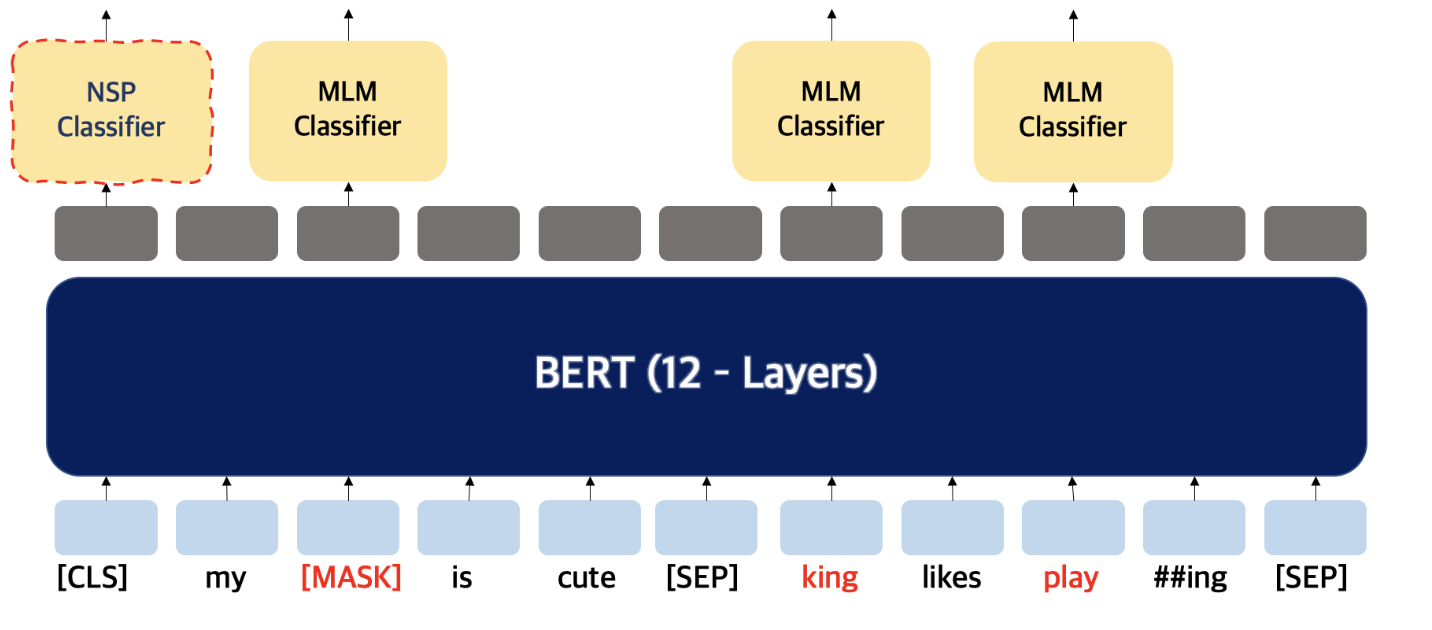
NSP (Next Sentence Prediction)
BERT 는 Question Answering 에서도 사용되기 위해 두개의 문장을 제공하고 문장들이 이어지는 문장인지 분류하는 훈련도 거치게 된다. 이때 문장들은 50% 확률로 이어지는 문장
여기서 [SEP] 토큰을 사용한다. 각 문장이 다른 문장임을 보여주기 위해 문장과 문장 사이에 [SEP] 토큰을 넣게 되며 가장 앞에 있는 [CLS] 토큰에 이 문장이 이어지는 문장인지에 대한 예측을 한다
3. Transfer Learning
: 학습된 언어모델을 전이학습시켜 실제 NLP Task를 수행하는 과정 이며 BERT 언어 모델에 NLP Task를 위한 추가적인 모델을 쌓는 부분
우리가 풀고자하는 Task의 데이터를 통해 추가적으로 학습시키며 검증과 테스트를 거치게 된다.
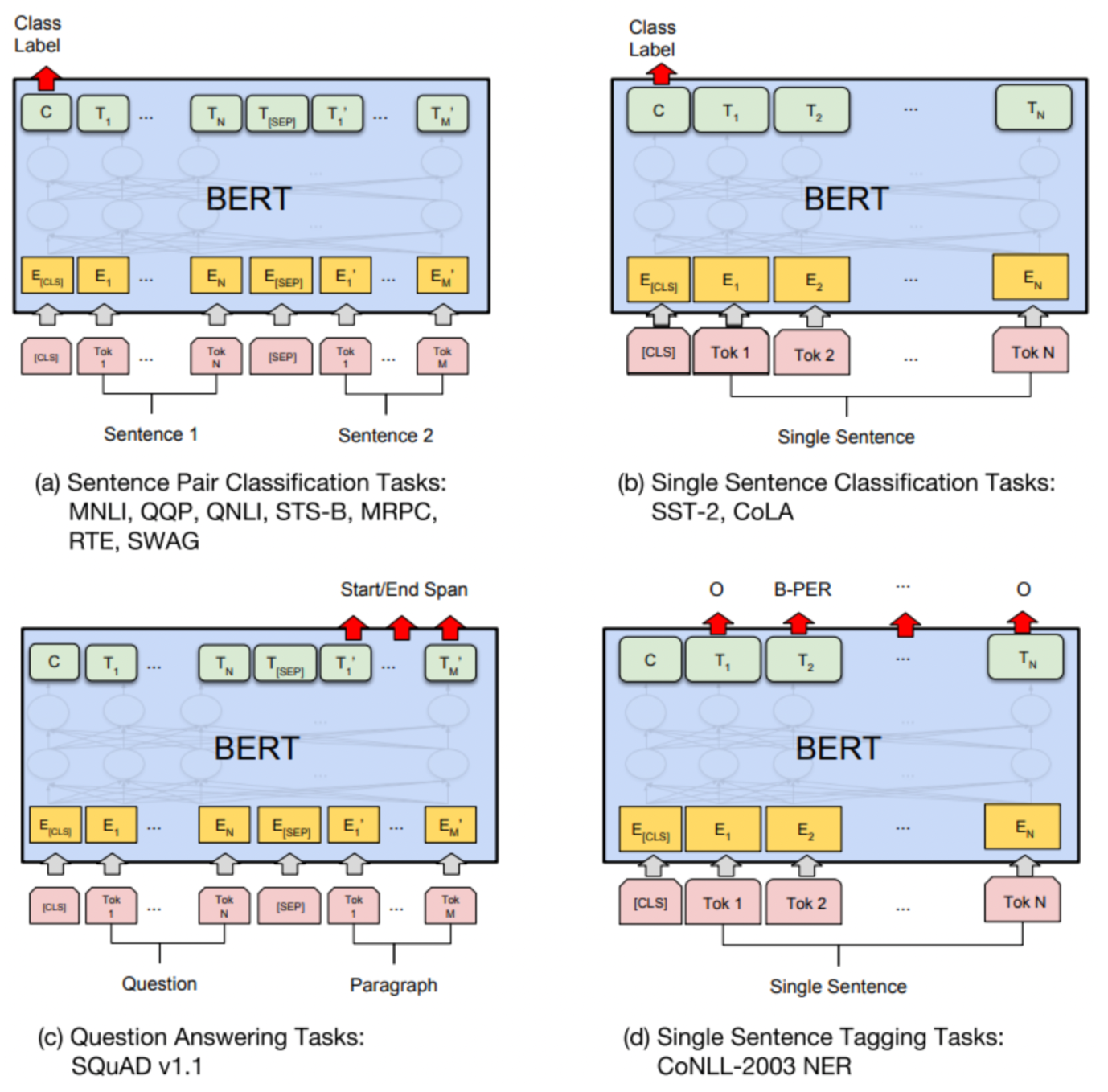
출처 - BERT 논문
(a) Sentence Pair Classification Task → 문장 쌍 분류 문제로 두 문장을 하나의 입력으로 넣고 두 문장간의 관계를 구하는 task
(b)Single Sentence Classification Task → 한 문장을 입력으로 넣고 문장의 종류를 분류하는 문제
(c)Question Answering Tasks→ Question에 정답이 되는 Paragraph의 substring을 뽑아내는 것, toekn 이후의 token 들에서 Start/End Span을 찾아내는 task 수행
(d)Single Sentence Tagging Tasks→ Named Entity Recognitoin 이나 형태소 분석과 같이 single sentence 에서 각 토큰이 어떤 class 를 갖는지 clssifier를 적용하여 정답을 찾아냄 , 다른 Task 들과 다르게 모든 토큰에 대해 결과값을 구한다
참고/레퍼런스
keep stusy.tistory.com
velog.io/@xuio
BERT 에 대해 쉽게 알아보기
BERT 톺아보기
BERT 논문정리
